 Бизнес-Блог Блоготей Бизнес-Блог «Блоготей» — информационный блог о бизнесе и финансах. Полезные статьи и новости из мира бизнеса, финансов, банков, экономики, инвестиций.
Бизнес-Блог Блоготей Бизнес-Блог «Блоготей» — информационный блог о бизнесе и финансах. Полезные статьи и новости из мира бизнеса, финансов, банков, экономики, инвестиций. 
XYZ-анализ: как узнать, сколько товара должно быть на складе
Собственники бизнеса обычно примерно знают, какие товары в их ассортименте более востребованы, а какие менее. Но знание это, как правило, интуитивное. Его одного недостаточно для принятия решения, когда и в каком количестве закупать товар, чтобы оптимально использовать склад. Купите слишком много неходового товара — зароете прибыль в запасы и затоварите склад. Слишком мало востребованного — бизнес будет проседать по выручке.
Вероятность ошибки минимальна, когда собственник решает, сколько закупать товара, на основе цифр, а не по наитию. Сегодня расскажем об XYZ-анализе, смысл которого — дать собственнику те самые цифры, которых ему не хватает.
Вся суть XYZ-анализа в одном примере
Для XYZ-анализа нам понадобится статистика по продажам товаров за несколько месяцев. Смысл метода — понять, насколько устойчив спрос на товар в разные периоды.
Для примера возьмем условный магазин канцтоваров.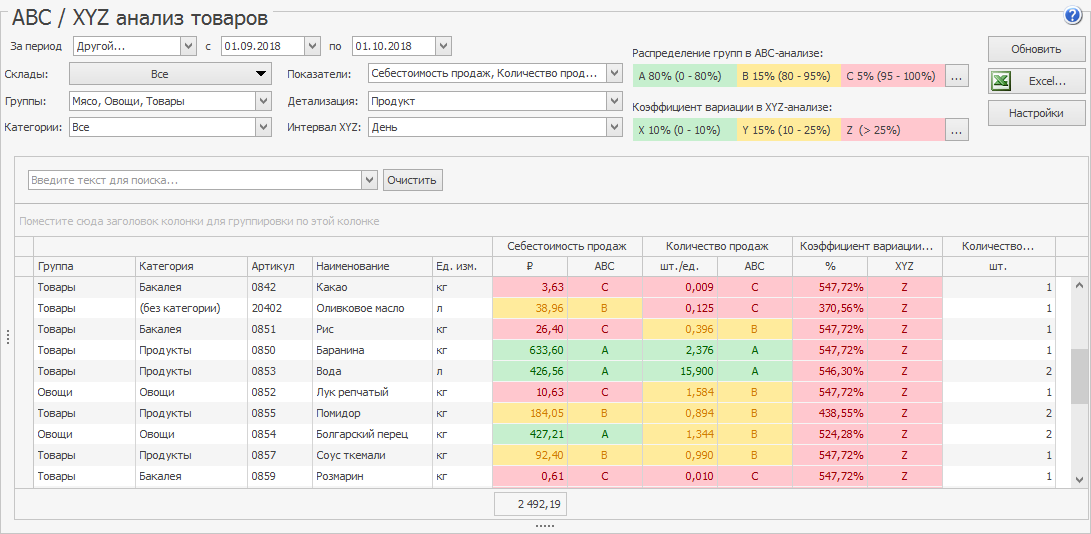
Таблица с первичными данными у нас примет такой вид.
Ассортимент и продажи магазина канцтоваров для XYZ-анализа
| Товар/Продано, шт. | Январь | Февраль | Март | Апрель | Май | Июнь |
| Авторучки | 150 | 140 | 120 | 150 | 140 | 140 |
| Маркеры | 120 | 120 | 120 | 100 | 110 | 110 |
| Тетради в линейку | 200 | 180 | 190 | 180 | 170 | 150 |
| Тетради в клетку | 170 | 180 | 180 | 170 | 170 | 160 |
| Общие тетради | 130 | 120 | 140 | 110 | 100 | 90 |
| Альбомы для рисования, А4 | 20 | 10 | 50 | 30 | 20 | 5 |
| Блокноты | 15 | 20 | 10 | 5 | 4 | 2 |
| Нотные тетради | 50 | 70 | 50 | 60 | 40 | 30 |
| Дневники | 200 | 100 | 50 | 20 | 40 | 0 |
| Пеналы | 100 | 80 | 70 | 50 | 10 |
Исходные данные для XYZ-анализа. Все цифры здесь и далее использованы для примера, с каким-либо реальным бизнесом возможны только случайные совпадения.
Все цифры здесь и далее использованы для примера, с каким-либо реальным бизнесом возможны только случайные совпадения.
Теперь задача — рассчитать, как меняется объем продаж по каждому товару от месяца к месяцу. Этот показатель измеряется в процентах и называется коэффициентом вариации. В голове этого делать не надо — умная электронная табличка сама все знает. От нас требуется только задать формулу:
Коэффициент вариации = СТАНДАРТОТКЛОНП ()/СРЗНАЧ()
В скобках указываем диапазон ячеек с данными о продажах по каждому товару. Например, (B3:h4).
А теперь самое главное — сортируем товар по группам согласно коэффициенту вариации:
- 0-10% — группа X, товары с самым устойчивым спросом
- 10 до 25% — группа Y, середнячки.
- 25+% — группа Z, товары со случайным спросом.
И вот, что у нас получилось.
Результаты XYZ-анализа. Товары распределились по группам по мере увеличения колебаний спроса по месяцам.
Самый устойчивый спрос на тетради в линейку, маркеры, авторучки, тетради в клетку и общие тетради. Коэффициент вариации по ним — в пределах 10%. И все они — наши лидеры, группа X.
Нотные тетради попали с коэффициентом вариации 20,66% в группу Y — середнячки.
Все остальное — аутсайдеры из группы Z с коэффициентом вариации больше 25%.
Как пользоваться информацией, которую дал XYZ-анализ
По завершении XYZ-анализа мы видим товары с самым стабильным спросом, середнячков по этому параметру и аутсайдеров. Информация о том, к какой группе относится товар — основа для принятия решений.
Товары из группы X — те самые, ради которых к вам идет основной поток покупателей. Поэтому они обязательно должны быть на прилавке/складе.
В группе Y собрались середнячки. Их присутствие на складе и прилавке остается на усмотрение руководителя. Закупать в таком количестве, как лидеров по спросу, нет смысла. На них спрос тоже есть, но погоды он не делает.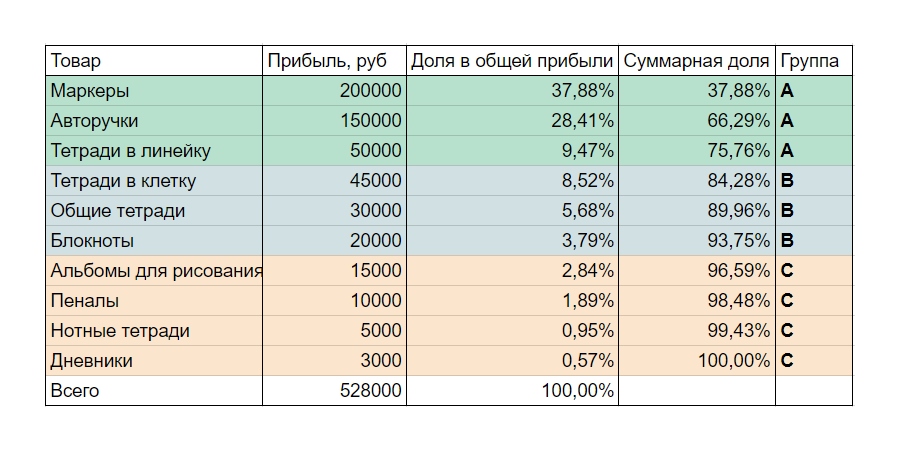
А вот от группы Z можно и отказаться или поставлять попавшие в нее товары по предзаказу. Спрос на этот товар случайный.
Вне зависимости от того, применяем ли мы только XYZ- или оба вида анализа, необходимо помнить — у XYZ-анализа есть подводный камень.
Подводный камень XYZ-анализа
При всем удобстве XYZ-анализа у него есть огромный недостаток. Коэффициент вариации сильно зависит от сезонности спроса. И это снижает точность прогнозирования.
Мы не случайно выбрали для примера канцелярку. Спрос на этот товар зависит от сезона: продажи активизируются в августе, в преддверии учебного года. А с началом летних каникул в июне — спад.
Поэтому если мы исключим из анализа статистику продаж по июню, получим совсем другие результаты.
Результат XYZ-анализа без учета сезонного падения спроса в июне — распределение товаров между группами отличается от варианта с учетом июньской статистики продаж. Разнятся и коэффициенты вариации одних и тех же товаров.
Чтобы прогноз был максимально точным, надо разбить период XYZ-анализа на сезоны. И каждый сезон анализировать отдельно. А свои высокие и низкие сезоны бизнесмены знают.
Проверка по деньгам
Все товары, которые вы подвергаете XYZ-анализу, полезно протестировать еще одним методом. Он позволяет выявить товары, которые в сумме приносят бизнесу наибольшую прибыль, это — АВС-анализ. В детали вдаваться не будем — это тема отдельной статьи. Скажем лишь главное. В основе АВС-анализа лежит принцип Паретто — 20/80: 20% товаров приносят бизнесу 80% прибыли. Результат АВС-анализа — распределение товаров на три группы:
- А — лидеры, на которых бизнес делает 80% выручки или прибыли;
- В — середнячки, которые приносят бизнесу еще 15%;
- С — аутсайдеры, суммарная доля которых в прибыли или выручке — оставшиеся 5%.
Анализировать один набор товаров обоими методами полезно, потому что по результатам группа X и группа А не всегда совпадают. И если товар из группы А одновременно находится в группе Z, то есть вносит лепту в основную прибыль бизнеса, но маловостребован — это повод для размышлений.
Разница между XYZ- и АВС-анализом — широта охвата. Оба относятся к инструментам стратегического планирования. Но АВС-анализ более оперативен, чем XYZ. Его можно сделать по итогам первого месяца работы и откорректировать планы на ближайший. А вот XYZ-анализ, который нужен, чтобы выявить колебания спроса от месяца к месяцу, проводить так часто смысла нет. Оптимально — по итогам минимум четырех месяцев с поправкой на сезонность. Если торгуете пляжными принадлежностями или кремом для загара, нет смысла сравнивать июньские продажи с январскими.
Для максимальной наглядности сделаем АВС-анализ по прибыли для товаров из нашего примера. Помесячно анализировать не нужно — достаточно общей суммы выручки или прибыли по каждому товару за тот же период, по которому мы делали XYZ-анализ.
Таблица примет вот такой вид:
Теперь мы видим, к какой группе по обоим видам анализа относится каждый товар.
А окончательным результатом XYZ-анализа и ABC-анализа должна стать вот такая таблица:
| А | B | C | |
| Х | Товары AX | Товары BX | Товары CX |
| Y | Товары AY | Товары BY | Товары CY |
| Z | Товары AZ | Товары BZ | Товары CZ |
Товары из категорий АХ, ВХ и AY (зеленые ячейки) должны быть на складе всегда.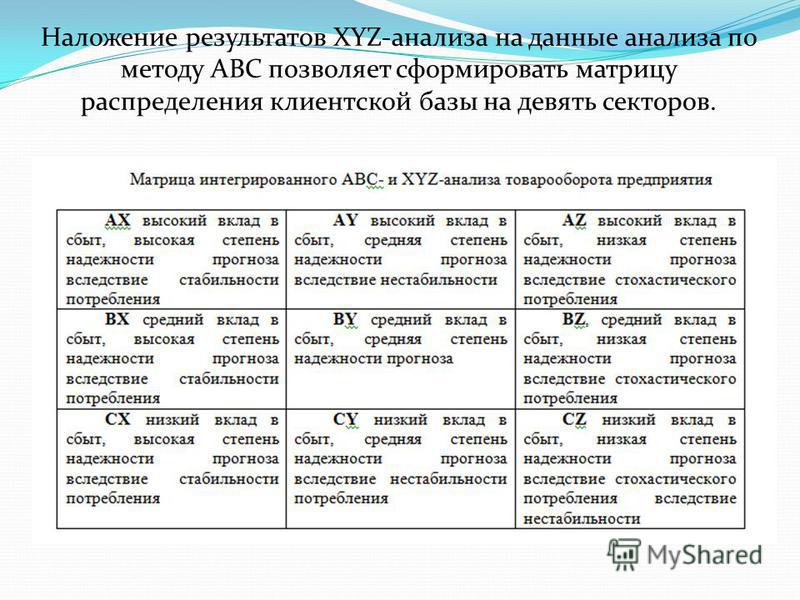 AZ, BY и CX (синие ячейки) — на усмотрение собственника. BZ, CY и CZ — держать не нужно или по минимуму.
AZ, BY и CX (синие ячейки) — на усмотрение собственника. BZ, CY и CZ — держать не нужно или по минимуму.
Остался финальный штрих — свести в эту итоговую таблицу канцтовары из нашего примера.
| Категория товара | А | В | С |
| X | Тетради в клетку. Тетради в линейку. Авторучки. | Маркеры. | |
| Y | Нотные тетради. | Общие тетради, пеналы. | |
| Z | Дневники. | Альбомы для рисования, А4. Блокноты. |
Теперь мы знаем — тетради в клетку, в линейку, авторучки и нотные тетради должны быть на складе всегда. Общие тетради, пеналы и маркеры — по усмотрению руководителя. А дневников, альбомов и блокнотов если и делать запасы, то минимальные.
На первый взгляд, мы только добавили себе головняков. По итогам XYZ-анализа было три группы. Провели АВС-анализ — их стало шесть. А теперь — и вовсе девять.
- Группа АХ — самые интересные товары. Тяжеловесы по всем параметрам — самые востребованные и приносящие львиную долю прибыли. Если их не будет достаточно на прилавке и на складе, просадка по выручке нам обеспечена.
- Группы ВХ — на этих товарах меньше зарабатываем, но они также востребованы. Их дефицит на складе и прилавке ударит по выручке. Не так болезненно, как в случае с тяжеловесами из группы АХ. Но тоже ощутимо.
- Группа АY — устойчивого спроса нет. Но по деньгам, что приносят бизнесу, держатся в лидерах. Значит, есть смысл позаботиться и об их достаточном количестве.
- Группа АZ хоть и вошла в число лидеров по приносимым деньгам, мало влияет на прибыль или выручку в силу малой востребованности. Поэтому сочтет нужным руководитель от нее отказаться или сделать некоторый запас — не критично.
- Остальные — чем ближе к правому нижнему углу итоговой таблицы, тем меньше востребованность, доля в прибыли или выручке бизнеса.
 А значит — тем меньше надобность в их запасах и тем безболезненнее можно отказаться от этих товаров совсем или перейти к поставкам только под заказ.
А значит — тем меньше надобность в их запасах и тем безболезненнее можно отказаться от этих товаров совсем или перейти к поставкам только под заказ.
 А значит — тем меньше надобность в их запасах и тем безболезненнее можно отказаться от этих товаров совсем или перейти к поставкам только под заказ.
А значит — тем меньше надобность в их запасах и тем безболезненнее можно отказаться от этих товаров совсем или перейти к поставкам только под заказ.Чтобы определить, сколько товара из групп AX, AY и BX должно быть на складе, нужно учесть срок поставки с момента заказа и максимально возможные продажи за период поставки.
Вот такой инструмент помогает собственнику максимально точно планировать закупки. Пользуйтесь на здоровье.
Материалы по теме:
«Дикси» начнет следить за товаром с помощью компьютерного зрения
Анализ больших данных помогает нам выявлять «сомнительных» клиентов. И вот как
Как рассчитать стоимость вашего персонального проекта
Как индивидуальному предпринимателю сдать налоговую декларацию
XYZ анализ ассортимента товаров — что это такое, пример и метод расчета
Что такое XYZ анализ
Важной задачей, которую ставят перед собой собственники и руководители компаний, является определение спроса на конкретные товарные позиции и его стабильность. Это необходимо, с одной стороны, для обеспечения широкого ассортимента продукции, с другой – чтобы не допускать залеживания товаров на полках магазина или на складе. Для этих целей используют XYZ анализ.
Это необходимо, с одной стороны, для обеспечения широкого ассортимента продукции, с другой – чтобы не допускать залеживания товаров на полках магазина или на складе. Для этих целей используют XYZ анализ.
Цель XYZ анализа ассортимента товаров
XYZ анализ продаж предполагает разделение всего ассортимента продукции на три группы в зависимости от постоянства спроса на них: товары с постоянным спросом, с сезонным спросом и случайным спросом. Цель XYZ анализа заключается в четком определении спроса на каждую товарную позицию, что в свою очередь позволяет прогнозировать и оптимизировать складские запасы.
Несмотря на то, что чаще всего с помощью этого метода оценивают спрос на товары, с его помощью можно прогнозировать изменение и других показателей, так, например, XYZ анализ запасов позволяет прогнозировать необходимость в запасах предприятия, XYZ анализ незаменим в логистике. Также с помощью данного метода можно определять и такие показатели, как выручка, прибыль, объемы продаж и т.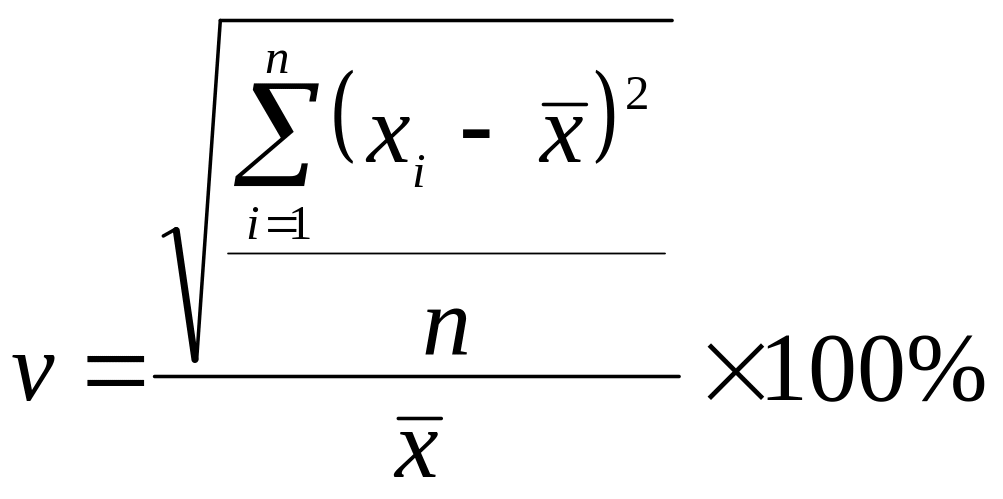 п.
п.
XYZ анализ можно проводить в эксель или в специальных программах, например «ФинДиректор Товары»
Метод XYZ анализа содержит следующие этапы
Первый этап XYZ анализа предполагает определение уровня спроса путем расчета коэффициента вариации по каждой группе товара. Коэффициент вариации определяется отклонением спроса на товар от среднего значения. Чем он выше, тем спрос на анализируемую группу товаров менее стабилен.
Второй этап XYZ анализа предполагает деление товаров на группы в соответствии со значениями коэффициента вариации. Деление происходит по следующим критериям:
Группа X – товары со стабильным спросом, коэффициент вариации находится в пределах от 0% до 10%;
Группа Y – товары с сезонным спросом, коэффициент вариации определен от 10% до 25%;
Группа Z – товары со случайным спросом, коэффициент вариации от 25% и выше.
Рассмотрим пример XYZ анализа товарного ассортимента в Excel
В таблице представлены объемы продаж по 7 товарам за 6 месяцев. Отдельно отметим, что XYZ анализ товаров стоит разбивать на сезоны, чтобы он был максимально точен. Каждый сезон необходимо анализировать отдельно.
Отдельно отметим, что XYZ анализ товаров стоит разбивать на сезоны, чтобы он был максимально точен. Каждый сезон необходимо анализировать отдельно.
Далее по каждому товару рассчитываем коэффициент вариации. Проводя XYZ анализ в экселе, это можно сделать с помощью специальных формул (формула при этом будет иметь вид =СТАНДОТКЛОН(B5:G5)/СРЗНАЧ(B5:G5) (диапазон ячеек охватывает продажи одного товара за 6 месяцев)).
В заключение отсортировываем товары по полученному значению коэффициента корреляции и присваиваем каждому соответствующую группу.
Название | Январь | Февраль | Март | Апрель | Май | Июнь | Коэффициент Вариации | Группа |
Товар 5 | 56 | 61 | 60 | 53 | 47 | 57 | 9 % | X |
Товар 7 | 85 | 82 | 62 | 67 | 87 | 73 | 13 % | Y |
Товар 2 | 12 | 20 | 20 | 19 | 18 | 20 | 17 % | Y |
Товар 1 | 35 | 47 | 34 | 29 | 37 | 30 | 18 % | Y |
Товар 6 | 90 | 115 | 178 | 132 | 157 | 123 | 24 % | Y |
Товар 4 | 3 | 6 | 8 | 10 | 6 | 3 | 46 % | Z |
Товар 3 | 5 | 6 | 20 | 37 | 18 | 6 | 81 % | Z |
Проведенный XYZ анализ ассортимента показал, что наиболее стабильным спросом пользуется Товар 5, только он в нашем примере попал в группу X.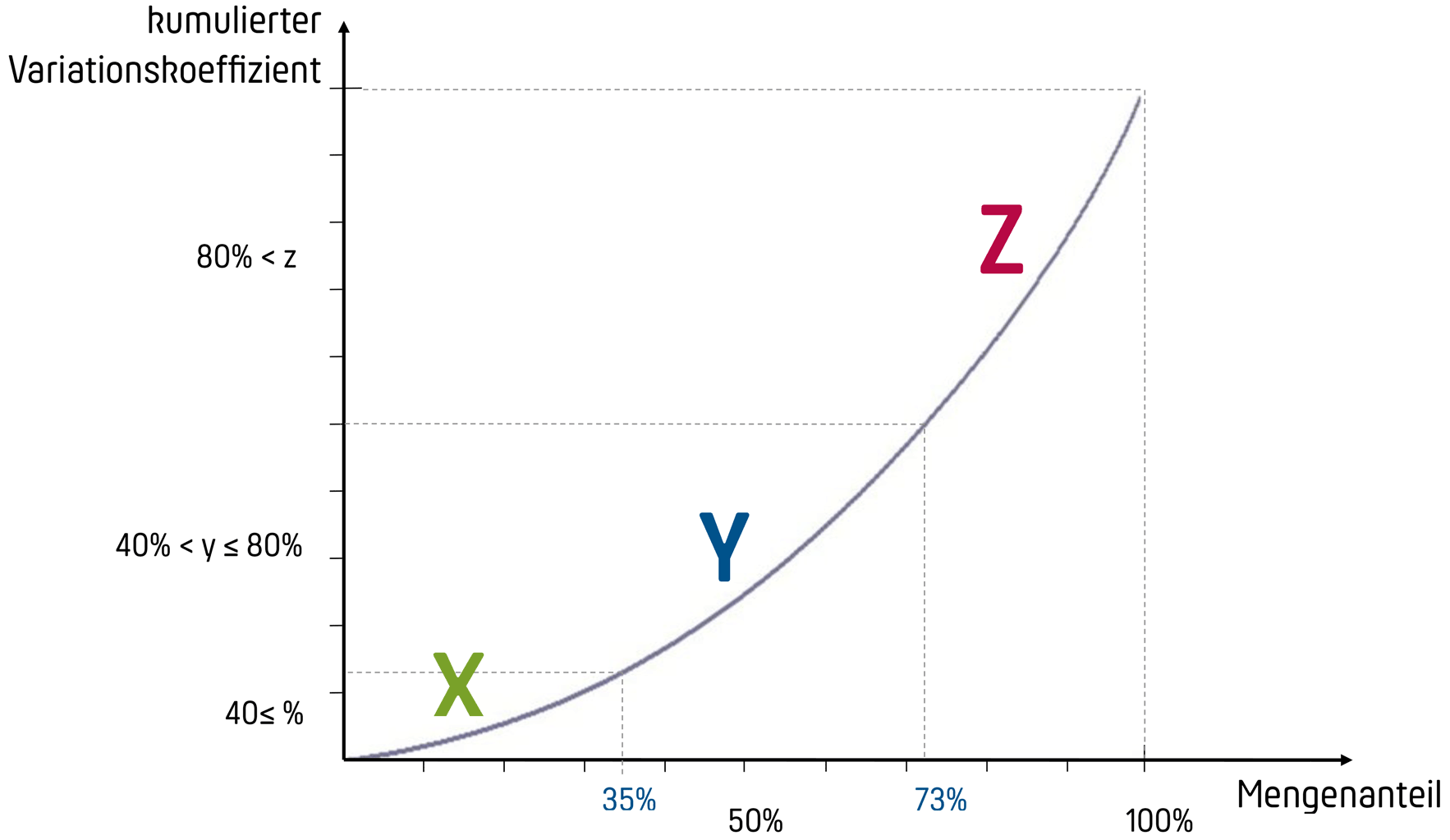 Это предполагает, что этот товар всегда должен быть на полках магазина и на складе. Это товар, из-за которого в магазин приходят покупатели.
Это предполагает, что этот товар всегда должен быть на полках магазина и на складе. Это товар, из-за которого в магазин приходят покупатели.
Товары из группы Y относятся к середнячкам, их не нужно закупать в таком объеме, как товары их группы Х, и хранить запасы на складе. Наличие их на полках определяется руководством магазина.
Товары из группы Z обладают случайным спросом, возможно, стоит подумать о работе с ними по предоплате.
XYZ анализ и ABC анализ
На практике XYZ анализ часто используется с ABC анализом, что очень полезно для планирования и формирования ассортимента. Товары из группы А не всегда совпадают с товарами из группы Х, менеджменту стоит задуматься, если товар из группы А (товар, который вносит основную долю в формирование прибыли) относится к группе Z.
При совместном анализе стоит учитывать и тот факт, что для XYZ анализа необходим более длительный период, как правило, это сезон, который длится несколько месяцев. ABC анализ же можно проводить по итогам одного месяца. Так, в результате такого анализа каждому товару присваивается своя группа как из XYZ анализа, так из ABC анализа. Например, если АВС анализ проводится по 1-му параметру, то получим следующее:
Так, в результате такого анализа каждому товару присваивается своя группа как из XYZ анализа, так из ABC анализа. Например, если АВС анализ проводится по 1-му параметру, то получим следующее:
| A | B | C |
X | AX | BX | CX |
Y | AY | BY | CY |
Z | AZ | BZ | CZ |
Наиболее предпочтительные для бизнеса те товары, которые попали в группы ближе к левому верхнему углу (AX, BX, AY), товары из нижнего правого угла таблицы – аутсайдеры.
АХ – самые востребованные и приносящие основную долю доходов товары. Их наличие на полках и складе должно быть гарантировано, если их не будет, не будет и большей части выручки.
BX – эти товары приносят магазину меньше дохода, но пользуются стабильным спросом. Они тоже всегда должны быть в наличии, их отсутствие также отразится на выручке, хоть и в меньшей степени.
AY – несмотря на отсутствие постоянного спроса, эти товары приносят существенный доход и, соответственно, должны быть в наличии.
Чтобы определить количество товара из групп AX, BX, AY, которое должно быть на складе, необходимо учитывать сроки поставки и максимально возможные объемы продаж.
Далее, чем ближе к правому нижнему углу, тем ниже востребованность этих товаров и их доля в выручке, соответственно, можно делать меньший запас этой продукции.
CZ – в эту группу, как правило, попадают новые товары, товары, которые поставляются под заказ, и т.п. Часть товаров из этой группы можно смело убирать из ассортимента, часть регулярно контролировать, т.к. именно из этой части формируются неликвидные и труднореализуемые запасы, из-за которых компания несет убытки.
Автоматизация XYZ анализа с помощью «ФинДиректор Товары» избавит вас от необходимости собирать данные и разбираться в формулах Excel, более того для каждой комбинации совместного XYZ и ABC анализа вы получите инструкцию к действию с рекомендациями по каждому товару и/или группе товаров.
Применение XYZ анализа для организации позволяет поддерживать оптимальный баланс между широким ассортиментом продукции и убытками из-за наличия невостребованных товаров. Это особенно актуально для компаний, у которых есть склады, ведь наличие товаров на складе связано с расходами для компании по логистике, хранению и т.п., также существуют риски окончания срока годности продукции. Прогнозирование и ведение точной и сбалансированной закупки должно быть приоритетной задачей для любого предприятий.
Хотите зарабатывать больше? Тогда регистрируйтесь в онлайн-сервисе «ФинДиректор Товары»
КУБ24 — ПОРЯДОК в ФИНАНСАХ
ФинДиректор – сервис по контролю и планированию
денег бизнеса. Помогает наводить порядок в финансах
и находить ТОЧКИ РОСТА
Еще больше полезного почитать
Метод касательных в XYZ-анализе: примеры на QlikView
Сегодня я продолжу начатую ранее тему по методу касательных. В этот раз применим его к методу анализа XYZ, который традиционно дополняет классификацию методом ABC, рассмотренный ранее. Как оказалось, общий алгоритм выделения групп методом касательных можно с успехом применять и при XYZ классификации – в конце статьи будут 2 qvw-документа с расчетом статистических и динамических коэффициентов вариации для выделения групп X, Y и Z.
Анализ XYZ – довольно популярный, наряду с ABC (вот, даже на заборе пишут=)), но его суть не все понимают, поэтому дам очень краткую справку. Кто в теме, смело пропускайте этот раздел.
XYZ-анализ классифицирует ресурсы компании в зависимости от стабильности их потребления и точности будущего прогнозирования. Чаще всего XYZ-анализ применяют к товарным запасам – группируют объекты анализа по мере однородности анализируемых параметров (по коэффициенту вариации), и таким образом выделяют:
- Категория X (коэффициент вариации 0 – 10%): товары с постоянным спросом и высокой точностью прогноза
- Категория Y (коэффициент вариации 10 – 25%): товары, продажи которых характеризуются колебаниями (например, сезонность) и средними возможностями прогнозирования
- Категория Z (коэффициент вариации свыше 25%): товары, потребность в которых носит случайный характер и точность прогнозирования невысокая.
Коэффициент вариации я тут привожу стандартный, в вашей компании разбивка по категориям X, Y, Z может немного отличаться.
Ну а формулы и более подробное описание анализа можно найти в Википедии.
Для чего и кем реально используется XYZ-анализ:
- Склад: В комбинации с АВС-анализом для оценки структуры склада по 9 (АX, AY, AZ, BX, BY, BZ, CX, CY,CZ, CN) или 12 группам (АX, AY, AZ, AN, BX, BY, BZ, BN, CX, CY,CZ, CN).
- Маркетинг: Выбор товара для промо-акций. Считается, что товары из групп AX, AY и BX дадут лучший ROI акции. В данной области ABC-XYZ-анализ хорошо дополняется анализом ассоциативных правил (но об этом в следующих статьях!)
- Закупки: для товаров группы Z используют повышенный коэффициент страхового запаса (safety stock).
Суть метода касательных для автоматизации распределения групп по XYZ я не буду повторять – подробно описывал его в статье Метод касательных в АВС-анализе. Основное отличие метода XYZ: для ABC мы строили кривую с накопительным итогом доли какого-либо фактора, для метода же XYZ строится кривая коэффициента вариации:
Для XYZ классификации полностью сохраняются все плюсы и минусы метода.
Ответ дам сразу – нет, все не так хорошо! Для XYZ-анализа очень важна корректная обработка данных. Нужно обязательно учитывать ситуации выбросов – например, промо-акции (аномально высокие продажи) или, наоборот, дефицит на складе (неудовлетворенный спрос). Поэтому если вы, не задумываясь возьмете необработанные данные продаж, скорее всего, получите слишком большую группу Z, в которую попадут товары с гораздо более прогнозируемым спросом.
Итак, чтобы получить реальную классификацию по XYZ, нужно обработать данные следующим образом:
- Из значений продаж убрать продажи по промо-акциям
- Из периодов выборки (как правило, это дни) убрать периоды с остатком на складе меньше, чем максимум продаж продукта (иначе из-за упущенных продаж, когда товара не было на складе, вы можете получить неверный коэффициент и неверно определить категорию товара)
- Оставшееся количество данных должно быть репрезентативным
При этом часть товаров у вас останется «за бортом», как товары с недостаточно репрезентативной выборкой – это могут быть новинки, товар с малым количеством дней на складе и т.д. Эти товары нужно проанализировать отдельно – выделять группу N, а не приписывать им группу Z.
Вам кажется, что в первом пункте мы что-то забыли? Да, и это сезонность!
Суть проблемы – практически во всех источниках деление на группы XYZ производится на основе коэффициента вариации, вернее называть его «статистическим коэффициентом вариации». Но давайте сравним две ситуации:
Как мы видим это два временных ряда с сезонной компонентой и без. Нетрудно увидеть, что использовать «статистический» коэффициент вариации во втором случае (когда сезонная компонента присутствует) может оказаться не совсем правильным ходом. В таком случае нам желательно делать расчет «динамического» коэффициента вариации, для расчета которого будет использоваться не мат.ожидание, а тренд, хотя бы линейный.
Тут можно скачать примеры скриптов XYZ-анализа в QlikView. Их я выполнил в двух вариантах:
- стандартный XYZ-анализ методом касательных
- XYZ-анализ с расчетом динамического коэффициента вариации.
Главным отличием является значение коэффициента вариации полученного двумя разными способами.
Статистический коэффициент вариации:
Где , σ — среднеквадратическое отклонение, M – мат.ожидание
Динамический коэффициент вариации:
Вариантов расчета такого коэффициента может быть много, я же буду использовать методы прогнозирования с переходом непосредственно к динамическому коэффициенту вариации.
где Mt+1 – прогнозное значение динамического ряда для периода t+1, в случае линейного тренда (без учета сезонности): Mt = a0 + a1*t.
σt+1 – среднее квадратическое отклонение динамического ряда:
Метод касательных для определения границ групп и динамический коэффициент вариации могут дополнять друг друга:
- Определяем критерий классификации, по которой будем проводить XYZ-классификацию
- Определяем коэффициенты линейного тренда (более сложные тренды, полиномиальный, экспонента и т.д. можно рассчитать по аналогии с линейным)
- Определяем среднее квадратическое отклонение динамического ряда по формуле выше
- Рассчитываем динамический коэффициент вариации
- Определяем границы групп экспертным методом или методом касательных
Внедрить алгоритм в свое приложение можно буквально в 2 шага:
1. Самое простое – пишем в скрипте:
$(Must_Include=xyz.txt);
Сам алгоритм метода касательных «спрятан» в подскрипт, который вызывается на выполнение командой $(Must_Include) или $(Include). Таким образом, мы можем включить алгоритм в любом месте скрипта, любое количество раз. В скрипте я комментировал каждый шаг, так что при необходимости разработчику или аналитику будет легко разобраться.
2. Перед тем, как написать команду выше, нам все же нужно немного поработать:
- сформировать таблицу, на которой будет проведена XYZ классификация:
- имя таблицы – Data_IN_XYZ,
- два поля – Object (объект классификации), Factor (критерий классификации).
«Внимание!» — данные в таблице Data_IN_XYZ – должны быть сгруппированными!!!
- на выходе мы получаем таблицу Data_OUT_XYZ со следующими полями:
- id – поле для сопоставления входных и выходных данных (поле Object в таблице Data_IN)
- Factor_coeff_var– коэффициент вариации
- XYZ_Group – группа X,Y,Z
- на выходе мы получаем таблицу Data_OUT_XYZ со следующими полями:
«Внимание!» — если необходимо использовать алгоритм XYZ классификации несколько раз в скрипте, то после каждого его применения не забывайте делать постобработку таблицы Data_OUT_XYZ. xyz.txt – содержит расчет СТАТИСТИЧЕСКОГО коэффициента вариации!
На всякий случай еще раз дублирую ссылку на скачивание примеров сриптов: XYZ-анализ стандартный и динамический в QlikView.
Всем ценной аналитики и до новых встреч!
XYZ-анализ — критика
XYZ-анализ — критика
XYZ-анализ и его применимость на практике. Точнее сказать, рассмотрим причины, по которым «известный и популярный метод» не выходит за страницы учебников и раздаточных материалов всевозможных бизнес-курсов (по логистике, маркетингу и прочему). Может быть, я не был бы столько категоричен, если бы метод XYZ рассматривался только как теоретический подход и, так сказать, направление мысли. Однако его упоминание во множестве учебниках и бизнес-курсах в качестве действующей и проверенной методологии вызывает рефлекс обманутого вкладчика. Не люблю, когда обманывают.
В двух словах напомню, что, несмотря на совершенно разную основу (анализируемый показатель), XYZ-метод часто используется как дополнение к ABC-анализу. Нередко можно встретить даже объединяющее название вроде ABC-XYZ-анализа. Тем не менее, XYZ-методология имеет самостоятельный математический аппарат. За буквами X, Y, Z скрывается степень прогнозируемости позиции (обычно товара при XYZ-анализе ассортимента). Уровень прогнозируемости может дать ценную информацию о характере динамики объекта исследования, которая в дальнейшем будет использована при принятии решений в его управлении. Если мы можем прогнозировать с высокой точностью, то это одно, а если понятия не имеем, что будет завтра, то – другое. В общем, умение не только прогнозировать, но и понимание самой возможности прогноза, – весьма полезные знания.
Уровень прогнозирования принято измерять таким показателем, как коэффициент вариации. Показатель этот сам по себе информативный и заслуженно занимает одно из почетных мест в системе статистических показателей. Он характеризует меру разброса данных вокруг средней величины и является относительным, то есть не привязан к единицам измерения самого явления. Казалось бы, здесь всё просто прекрасно и придраться не к чему. Однако но! Предлагаю на секунду вернуться к примеру, где наличие в динамике тенденции и сезонности резко увеличивает коэффициент вариации, тем самым снижая показатель прогнозируемости. То есть при некотором реальном уровне прогнозируемости (величине ошибки прогнозирования) колеблемость, рассчитанная по исходным данным, будет сообщать о худшей прогнозируемости, чем она есть на самом деле. Ошибка может иметь существенные последствия.
Пример расчёта коэффициентов вариации для XYZ-анализа
Теперь давайте перейдём к конкретным расчётам и примерам XYZ-анализа. Итак, коэффициент вариации отражает степень разбросанности данных вокруг их среднего значения и это якобы соответствует качеству возможных прогнозов. Чем больше колебания, тем хуже прогнозируемость, то есть ошибка прогноза. Рассмотрим в качестве примера два динамических ряда и измерим степень их прогнозируемости с помощью коэффициента вариации.
Есть товар А и товар Б с одинаковыми средними продажами (для чистоты эксперимента). Данные о динамике их продаж приведены в таблице ниже.
Товаров может быть пару сотен и даже тысяч, поэтому о наглядных графиках и предварительном визуальном анализе речи быть не может. На деле приходится работать именно с табличным видом информации и реальное представление о динамике бывает только хуже за счет огромного количества данных. У нас же в примере только 2 (два) ряда, и то на глазок ничего не видно. Единственным пока ориентиром может служить коэффициент вариации. Проведем необходимые расчёты в Excel для обоих динамических рядов. Средние значения продаж, как условились выше, одинаковые – по 77 единиц. Коэффициент вариации для товара А составил 19%, для товара Б – 35%. Следуя общепринятой интерпретации, динамика товара А прогнозируется лучше (с меньшей ошибкой), чем динамика товара Б, так как коэффициент вариации динамики его продаж значительно ниже. Далее, исходя из полученных расчётов, товар А, допустим, попадает в группу Y (лучше прогнозируется), товар Б – в группу Z (хуже прогнозируется). За этим следует установка нормативных запасов, что напрямую отражается на величине замороженных средств. Как видно, на товар Б придётся отвлечь относительно больше финансовых ресурсов, так как того потребует непредсказуемость его продаж, если судить по коэффициенту вариации. Что ж, пусть пока будет так. Теперь откроем занавес и посмотрим, какая картинка скрывается за числами продаж. Алле оп!
Продажи товара А:
Продажи товара Б:
Вуаля!
Оба графика, как отчётливо видно, отличаются по своему характеру. Продажи А имеют спонтанный, случайный характер. Продажи Б, наоборот, подвержены ярко выраженным закономерностям роста и цикличности. На самом деле я всё сам придумал! Однако сделал это с умыслом, чтобы дать читателю образное представления о возможных отличиях в характере динамических рядов. На практике чаще получается что-то среднее: и тенденция может быть, и цикличность, и скачкообразные всплески или провалы в продажах.
Динамика А имеет хаотичный характер, и уловить какую-либо закономерность (кроме среднего значения) невозможно. В этом случае коэффициент вариации действительно отражает степень случайной разбросанности данных и, соответственно, уровень прогнозируемости. Зато динамика Б имеет ярко выраженную тенденцию (постоянный рост) и цикличность (периодические всплески), что вовсе не является случайностью, а наоборот, закономерностью, которая, скорее всего, будет наблюдаться в прогнозируемом периоде. Следовательно, прогноз может быть скорректирован с учетом наличия закономерностей в ряде, что уменьшит ошибку прогнозирования. Таким образом, реальный уровень прогнозируемости будет выше, чем показывает коэффициент вариации (без учёта тенденции и сезонности).
Корректировка данных для проведения XYZ-анализа
В статистике существуют методы, с помощью которых оцениваются и вычленяются тренд и цикличность. Я пока не буду расписывать, как именно это делается, так как для подробного изложения понадобится целая статья, возможно даже, три. Поэтому продемонстрирую результаты полученных расчётов.
Чисто тенденция на рисунке выглядит так.
Немного кривовато получилось, но не будем гнаться за красотой. Поверим специализированной компьютерной программе.
Циклическая компонента выглядит так.
Оба показанных выше графика отражают хорошо прогнозируемые составляющие динамики. После их вычленения из исходных данных нашему взору предстанет то, что невозможно прогнозировать, – случайная составляющая, которая отражает спонтанность продаж.
Это так называемая случайная компонента — в ней больше нет закономерностей, а только случайные и непредсказуемые колебания, которые и определяют реальный уровень прогнозируемости.
После устранения тенденции и цикличности из динамики продаж товара Б коэффициент вариации составил всего 5% (так как среднее значение случайных колебаний равно нулю, то для получения правильного показателя вариации стандартное отклонение случайной составляющей делится на среднюю исходных данных), что существенно меньше, чем такой же показатель для товара А. Вывод о степени прогнозируемости двух товаров становится противоположным, то есть товар Б можно прогнозировать гораздо более точнее, чем товар А. Следовательно, товарный запас для позиции Б оказался завышен, так как всплески и рост продаж были вполне предсказуемыми и держать большой страховой запас не было необходимости. Ошибка перетарки склада налицо. Вот вам и XYZ-анализ!
Из данных расчётов следует заключить, что без тщательного анализа и корректировки первоначальных данных использование XYZ-анализа может привести к неверной трактовке. Последствия не заставят себя ждать.
На самом деле наличие тренда и цикличности в динамике – давно известные факторы, которые искажают XYZ-анализ. Опытные аналитики даже предлагают средства для борьбы – через ту же корректировку данных. Однако здесь необходимо понимать следующее.
В примере выше была показана динамика с равномерным трендом и пятью циклами (например, сезонами) продаж. Равномерность тренда на протяжении такого длительного периода вряд ли возможна в реальной жизни. Скорее всего, он был бы либо непостоянным, что уже затрудняет его оценку, либо может измениться в любой момент, что так же не прибавляет уверенности в прогнозе. Либо такой длинный ряд вообще будет трудно найти, а по короткой динамике рассчитать тенденцию без существенной ошибки в принципе невозможно.
Эта же проблема касается и цикличности продаж. Если по пяти циклам ещё можно получить минимальную точность параметра, то найти такой динамический ряд бывает весьма трудно. Для этого часто не хватает накопленной статистики. Но даже если и хватает, то аналитики, которые советуют использовать XYZ-метод, часто рекомендуют ограничиться одним периодом для расчёта так называемого коэффициента сезонности — то есть цикличной компоненты. Не нужно забывать, что цикличность – это фактор закономерности, а не просто случайность. А разве можно закономерность оценить по одному, двум или даже трём наблюдениям? Отнюдь. Вероятность и величина ошибки будут очень большие. Поэтому для оценки и устранения цикличности требуется хотя бы 5 полных циклов. В случае, если цикличность определяется сезонностью, то данные потребуются за полные 5 лет. Не все предприятия могут похвастаться такой статистикой.
Проблемы при оценке закономерных компонент в динамике могут привести к ошибкам в расчётах. На выходе могут выйти данные, противоречащие элементарной логике. Ну, типа, страховой запас при ежемесячных поставках нужно поддерживать на уровне годового объёма продаж. Абсурд.
Как видно, для определения реального уровня прогнозируемости трудно обойтись одним только коэффициентом вариации. Нужно использовать дополнительные статистические методы анализа. Однако для их применения обычно требуется большое количество исходных данных (динамика за длительный период), что в реальности встречается не так часто, как хотелось бы. Кроме того, тщательный анализ динамики (например, как показано выше), потребует немало времени даже для одного ряда. Если их десять, может понадобиться несколько часов. Если их сто или тысяча, то к концу анализа за определенный месяц наступит следующий, и нужно будет начинать все заново. Короче, на подобные расчёты для большого множества позиций никогда не хватит времени. А автоматизировать тоже не получится, потому что велика доля ручного труда и человеческой логики. Компьютеры так ещё не умеют. Чай, искусственный интеллект не придумали. В то же время, ограничившись малым количеством значений (малой выборкой), неизбежно увеличивается ошибка рассчитываемых показателей, что зачастую ведёт к денежному и моральному ущербу.
Таким образом, XYZ-анализ больше подходит для грубой оценки данных или для определения направления анализа и действий, чем для практического ежедневного применения. Сам по себе XYZ-анализ в чистом виде можно использовать в условиях, приближенных к лабораторным, то есть при выполнении большого количества условностей. Ну, или при анализе очень маленького количества динамических рядов, когда есть возможность подумать над каждым. При большом ассортименте такой возможности, конечно, нет. По шкале практичности я ставлю данному методу три с минусом. Да и то, только потому, что у него есть крепкая математическая основа, и название красивое. Других преимуществ я не вижу.
Езепов Дмитрий
statanaliz.info
Перепечатка и перепостинг статьи вместе с этим текстом, указанием автора, и ссылки на первоисточник — приветствуются!
Как выполнить ABC и XYZ анализ онлайн в автоматическом режиме? – Science Portal
Закон Парето гласит: нужно осуществить несколько самых сложных действий, чтобы добиться эффективного результата в каком-либо деле, в то время как остальные усилия могут быть потрачены впустую. Чтобы не ошибиться с выбором поставленных задач в случае с многономенклатурной моделью управления запасами, воспользуйтесь сервисом для бесплатного проведения ABC-анализа и анализа XYZ – процедуры подробного прогнозирования рейтинга объема продаж розничной и оптовой продукции разного предназначения.
С помощью автоматического расчета логистики продавец сможет провести распределение на три категории, исходя из различных факторов, и узнать уровень спроса на каждый сегмент складских запасов. Пользуясь инструментом для анализа рентабельности ассортиментной группы товаров, менеджер магазина и сотрудники отдела продаж с легкостью выполнят свою главную задачу – привлекут большое число покупателей и поспособствуют развитию бизнеса за счет хорошей прибыльности. Обычно продавцы анализируют отдельно по товарообороту (реализованному количеству) и показателю получаемой выручки (реализованной торговой наценке).
Преимущества расчета эффективности с помощью ABC-анализа
Подобная аналитика рентабельности товарного ассортимента позволяет составить отчет о стабильности продаж, схем CRM и KPI, воронки продаж. Программное обеспечение разделит продукцию на критерии по степени убывания востребованности среди клиентов:
- A – самые важные товары на складе, которые приносят 50 % от общей прибыли.
- B – средние по важности продукты, их доля составляет 30 % результата.
- C – проблемные товары, доход от продажи которых приносит последние 20 % прибыли.
Совмещение ABC- и XYZ-анализа – система с более подробной товарной классификацией. Распределение элементов осуществляется по девяти группам. Также результатам анализа дается комплексная оценка, что помогает в ведении управленческого и складского учета.
ABC-анализ ассортимента представляет собой более эффективную и быструю процедуру, чем использование MS Excel. Вам не придется искать и изучать формулу матрицы, оформлять лист с расчетами и бояться сделать ошибку.
Особенности работы с программой
Для проведения факторного анализа и получения коэффициента вариации следует произвести следующие действия:
- Откройте файл формата .xlsx, используя таблицу Excel. Занесите в ее ячейки данные о продажах. Чтобы сделать это правильно, воспользуйтесь кнопкой «Шаблон».
- Выберите необходимое количество месяцев для анализа динамики.
- Введите желаемые границы диапазона двух категорий, проценты третьей определятся автоматически (например, A=50 %, B=40 %; значит, C=10 %).
- Загрузите подготовленные файлы.
Результаты анализа управления ассортиментной продукцией определят, к какой категории будет отнесен конкретный товар. Чтобы узнать подробнее о процессе обработки данных, нажмите на кнопки «О сервисе» и «Общие рекомендации».
Также вы можете выбрать в качестве метода анализа ассортимента XYZ и задать параметры для восьми из девяти групп.
Пример выполненных расчетов
Мы проанализировали следующие данные о продаже различных товаров:
- продукт 1 – 550, 340, 260, 470;
- продукт 2 – 250, 55, 140, 70;
- продукт 3 – 200, 150, 350, 320;
- продукт 4 – 400, 80, 300, 310;
- продукт 5 – 370, 120, 100, 120.
Сервис показал результаты, с которыми можно ознакомиться на изображении.
Объекты анализа были быстро обработаны и распределены на три категории в зависимости от введенных чисел.
При совместном анализе можно подробнее изучить значение каждого сегмента, нажав на кнопку «Пояснение по пересечению групп».
Методы ABC, XYZ. Задача на знание метода ABC
1. Методы ABC, XYZ. Задача на знание метода ABC.
МЕТОДЫ ABC, XYZ.ЗАДАЧА НА ЗНАНИЕ
МЕТОДА ABC.
Выполнила: студентка группы ДТУОБ-41
Белокрылова О.А.
2. Метод ABC
— ранжирование объектов анализа по разнымпараметрам.
ABC-анализ опирается на гипотезу о
том, что в реальности нередко 20%
элементов обеспечивают около 80%
результата (принцип Парето).
4. Порядок проведения анализа АВС
Формулирование цели анализаИдентификация объектов управления, анализируемых методом АВС
Выделение признака, на основе которого будет осуществлена классификация объектов
управления
Оценка объектов управления по выделенному классификационному признаку
Группировка объектов управления в порядке убывания значения признака
Построения кривой АВС
Разделение совокупности объектов управления на три группы: А, В, С
5. Метод определения границ с помощью касательной к кривой АВС
■ По оси ОХ откладываются объекты управления, впорядке убывания доли объекта в общем результате, в
процентах к общему количеству объектов управления.
■ По оси ОY откладывается доля вклада объекта в общем
результате, исчисленная нарастающим итогом и
выраженная в процентах.
■ Начало и конец графика соединяем прямой OD и
проводим касательную к кривой АВС, параллельную
линии OD.
■ Абсцисса точки касания (т. М) покажет границу между
группами А и В, а ордината укажет долю вклада группы
А в общий результат.
■ Соединяем т. М с т. D и проводим новую касательную к
графику АВС, параллельную линии MD.
■ Абсцисса точки касания (т. N) указывает границу между
группами В и С, а ордината показывает суммарный
вклад групп А и В в общий результат.
6. Метод определения границ с помощью петли АВС анализа
■ В качестве границ множеств А, В и С участки резкого изменениякривизны графика АВС.
■ Представим кривую АВС в виде композиции дуг трех окружностей:
дуга LM окружности О1, дуга MN окружности О2, дуга NP окружности
О3. Наибольший радиус имеет окружность О3, радиус окружности
О1 несколько короче. Существенно короче радиус окружности О2,
дуга которой MN находится в середине фигуры LMNP.
■ Проведем касательную к кривой LMNP в её начальной точке L и
восстановим нормаль из точки касания в направлении центра
окружности О1. Длина нормали должна быть больше радиуса
окружности О2, но меньше радиусов окружностей О1 и О3.
■ Переместим касательную из начала в конец кривой LMNP. Конец
нормали при этом начертит фигуру lmnp. На участках lm и np конец
нормали движется в одном направлении с касательной, а на
участке mn – во встречном. Точки на кривой lmnp, в которых конец
нормали меняет направление движения, соответствуют точкам
изменения кривизны основной фигуры – LMNP.
7. Разделение на группы А, В и С с помощью петли АВС анализа
■ Проведем касательную к кривой АВС в её начальнойточке и восстановим нормаль, обращенную вправо от
кривой. Проведем касательную от начала кривой до
конца графика АВС.
■ Длину нормали подберем так, чтобы она не доставала до
множества центров кривизны, соответствующих
начальному и конечному участкам графика, но чтобы
выходила за пределы срединного облака центров
кривизны.
■ Продвинем касательную от начала кривой до конца
графика АВС.
■ Когда конец нормали выйдет из «срединной облачности»,
значение границ перестанут меняться с изменением
длины нормали. Данные значения границ следует принять
для дифференциации на группы А, В и С.
8. Принцип классификации
ГруппаДоля в ресурсах, %
Доля в результате, %
А
20
80
В
30
15
С
50
5
9. Метод XYZ
■ Принцип дифференциации ассортимента в процессе анализа XYZ –весь ассортиментделят на три группы в зависимости от равномерности спроса и точности
прогнозирования:
Группа «X» — товары, спрос на которые равномерный, или может незначительно колебаться.
Объем реализации по товарам, включенным данную группу, хорошо прогнозируется.
Группа «Y» — товары, объем потребления которых колеблется (товары с сезонным характером
спроса). Возможности прогнозирования спроса по товарам данной группы – средние.
Группа «Z» — товары, спрос на которые возникает лишь эпизодично, какие-либо тенденции
отсутствуют. Прогнозировать объемы реализации товаров группы «Z» сложно.
10. Порядок проведения анализа XYZ
Определение коэффициентов вариации по отдельным позициям ассортиментаГруппировка объектов управления в порядке возрастания коэффициента
вариации
Построение кривой XYZ
Разделение совокупности объектов управления на три группы: X, Y, Z
■ Признаком, на основе которого конкретную
позицию ассортимента зачисляют в группу X, Y или
Z, выступает коэффициент вариации спроса (v) по
этой позиции:
где xi – i-тое значение спроса по оцениваемой
позиции;
–
Х – среднее значение спроса по оцениваемой
позиции за период n;
n – величина периода, за которых проведена
оценка.
■ Величина коэффициента вариации изменяется в
пределах от нуля до бесконечности.
12. Возможный вариант дифференциации ассортимента на группы X, Y и Z
ГруппаИнтервал
X
0≤v
Y
10%≤v
Z
25%≤v
13. Кривая анализа XYZ
14. Комбинация АВС- и XYZ-анализа
АB
высокая потребительская
стоимость
средняя потребительская
стоимость
X-материал
высокая степень надежности
прогноза потребления
высокая потребительская
стоимость
Y-материал
средняя степень надежности
прогноза потребления
высокая потребительская
стоимость
Z-материал
низкая степень надежности
прогноза потребления
С
низкая потребительская
стоимость
высокая степень
высокая степень надежности надежности прогноза
прогноза потребления
потребления
средняя потребительская
низкая потребительская
стоимость
стоимость
средняя степень
средняя степень надежности
надежности прогноза
прогноза потребления
потребления
средняя потребительская
низкая потребительская
стоимость
стоимость
низкая степень
низкая степень надежности
надежности прогноза
прогноза потребления
потребления
Объединение данных о соотношении количества и стоимости
АВС-анализа с данными соотношения количества и структуры
потребления XYZ-анализа позволяет получить ценные
инструменты планирования, контроля и управления для
системы снабжения в целом, и управления запасами в
частности.
16. Задача на знание метода АВС (в EXCEL)
■ Составим учебную таблицу с 2столбцами и 15 строками.
Внесем наименования
условных товаров и данные о
продажах за год.
■ Отсортируем данные выручки в
таблице «По убыванию».
■ Добавляем в таблицу итоговую
строку. Нам нужно найти общую
сумму значений в столбце
«Выручка».
■ Рассчитаем долю каждого элемента в общей
сумме. Создаем третий столбец «Доля» и
назначаем для его ячеек процентный формат.
Вводим в первую ячейку формулу:
=B2/$B$17 и «Протягиваем» до последней
ячейки столбца.
■ Посчитаем долю нарастающим итогом.
Добавим в таблицу столбец «Накопленная
доля». Для первой позиции она будет равна
индивидуальной доле. Для второй позиции –
индивидуальная доля + доля нарастающим
итогом для предыдущей позиции. Вводим во
вторую ячейку формулу: =C3+D2.
«Протягиваем» до конца столбца. Для
последних позиций должно быть 100%.
■ Присваиваем позициям ту или иную группу.
До 80% — в группу А. До 95% — В. Остальное –
С. Чтобы было удобно пользоваться
результатами анализа, проставляем напротив
каждой позиции соответствующие буквы.
18. Спасибо за внимание!
Обработка данных XYZ
Обработка данных XYZ
Возможности обработки данных XYZ на данный момент достаточно ограничены. Большая часть анализа должна производиться после преобразования их в изображение — основной тип данных, для которого Gwyddion предлагает большой выбор функций их обработки.
Основные операции с данными XYZ в настоящий момент включают в себя объединение двух наборов точек, доступное в меню → . Объединение позволяет избежать создания точек с в точности совпадающими пространственными координатами. Вместо этого их значения усредняются – что включается опцией Усреднить совпавшие точки.
Растеризация
→
Gwyddion отлично работает с данными, снятыми на правильной сетке, т.е. данными изображения. Чтобы применить его функции обработки данных к нерегулярным данным XYZ, эти данные необходимо интерполировать на правильную сетку. Другими словами, данные нужно растеризовать.
Пользователю доступен выбор нескольких методов интерполяции, задаваемых опцией Тип интерполяции:
- Округление
Этот вариант интерполяции аналогичен интерполяции округлением для правильных сеток. Интерполированное значение в точке на плоскости равно значению ближайшей точки в наборе точек XYZ. Это означает. что проводится триангуляция Вороного и каждая ячейка Вороного «заполняется» значением ближайшей точки.
- Линейная
Этот вид интерполяции аналогичен линейной интерполяции для правильных сеток. Интерполированное значение в точке рассчитывается из значений трёх вершин треугольника триангуляции Делоне, содержащего точку. Поскольку три вершины определяют плоскость в пространстве уникальным образом, значение в точке определяется этой плоскостью.
- Поле
Значение в точке будет взвешенным средним всего набора точек XYZ, где вес обратно пропорционален четвёртой степени расстояния. Поскольку для каждой интерполированной точки рассматриваются все точки данных XYZ, этот метод может оказаться очень медленным.
- Среднее
Метод получения значений пикселей на лету используя комбинацию простого округления и переноса соседних значений. В плотных местах, где большое количество точек XYZ попадает в каждый пиксель, значение, присваиваемое пикселю будет некоторым вариантом взвешенного среднего точек. В местах с редким расположением точек, где относительно большие области не содержат точек XYZ, значение пикселя переносится с соседних пикселей, которые содержат точки XYZ. Основной особенностью данного метода интерполяции является то, что он всегда будет быстрым, в то же время нередко получается весьма неплохой результат интерполяции.
Первые два типа интерполяции основаны на тесселяции Вороного и триангуляции Делоне, которые плохо определены для наборов точек, где более двух точек лежит на одной линии и более трёх лежит на окружности. если это происходит, триангуляция может дать сбой и будет показано сообщение об ошибке.
Значения вне выпуклой оболочки множества точек XYZ на плоскости описываются опцией Тип внешней части:
- Граничный
Набор точек не меняется никоим образом и значения на выпуклой оболочке просто расширяются на бесконечность.
- Зеркальный
Набор точек дополняется точками, «отраженными» относительно сторон ограничивающего параллелепипеда.
- Периодический
Набор точек дополняется периодически повторяющимися точками из окрестности противоположной стороны ограничивающего параллелепипеда.
Горизонтальные и вертикальные размеры в пикселях для результирующего изображения задаются как Горизонтальный размер и Вертикальный размер в разделе Разрешение.
Нередко результирующее изображение должно иметь квадратные пиксели. Это может быть достигнуто нажатием кнопки Сделать пиксели квадратными. Данная функция не пытается сделать пиксели квадратными в процессе редактирования разрешения и диапазонов размеров чтобы не менять значения, которые вы хотели бы сохранить. Поэтому перевод в квадратные пиксели надо включить в явном виде этой кнопкой.
Возможно растеризовать только часть данных XYZ и также построить часть их окружения. Область для растеризации изображения управляется диапазонами, задаваемыми в разделе Физические размеры диалогового окна. Кнопка Сбросить диапазоны устанавливает область в прямоугольник, целиком содержащий данные XYZ. Также можно выбрать область для построения на изображении предпросмотра, естественно предполагая, что она лежит внутри показываемой сейчас на экране области.
Если данные XYZ представляют собой изображение, т.е. точки формируют регулярную сетку, ориентированную вдоль осей декартовой системы координат, и каждая точка в прямоугольной области представлена только один раз, функция растеризации может сразу построить соответствующее изображение. Это можно сделать используя кнопку Создать изображение сразу которая появляется вверху диалогового окна в данном случае.
Выравнивание
→
→
Основная функция является той же самой, что и Исправить нуль для данных изображения. Она смещает все значения таким образом, чтобы их минимум стал равен нулю.
удаляет среднюю плоскость изображения. Эта функция предлагает два подхода. Вычитание полностью эквивалентно вычитанию плоскостидля изображений и представляет собой простое вычитание средней плоскости, которая определяется с помощью обычного метода наименьших квадратов.
Поворот удаляет среднюю плоскость реальным вращением облака точек, операцией которая может быть точно реализована только для данных XYZ (соответствующая функция Выровнять поворотом для изображений является приближенной). Более того, функция гарантирует что средняя плоскость будет горизонтальной после поворота, что соответствует удалению средней плоскости методом наименьших квадратов расстояний до этой плоскости (в отличие от вертикальных расстояний для изображений). Естественно, поскольку поворот смешивает пространственные координаты и значения данных, он будет возможен только если z является той же самой физической величиной, что и x, и y (предполагается, что геометрическими размерами).
Вращение меняет координаты x и y точек, потенциально делая данные XYZ несовместимыми с другими данными в файле. Включая Обновить X и Y всех совместимых данных можно обновить пространственные координаты во всех остальных наборах данных XYZ в файле, чтобы они соответствовали пространственным координатам в текущем после поворота. Значения z во всех остальных данных естественно остаются неизменными.
Аппроксимировать форму
→
Эта функция также доступна для изображений. Описание различий между вариантами функции для изображений и данных XYZ можно найти в разделе Аппроксимировать форму для изображений.
Аппроксимация методом наименьших квадратов геометрическими фигурами и другими предопределёнными функциями всего набора данных может использоваться различными способами: для удаления общей формы, такой как сферическая, измерения геометрических параметров или создания идеализированных данных, соответствующих несовершенной реальной топографии. Также возможно использовать данный модуль для генерации искусственных данных если ничего не аппроксимировать и задать все геометрические параметры явным образом, хотя это всё равно требует обеспечить входные данные, которые будут задавать координаты XY точек.
Простейший вариант использования требует выбрать тип формы для аппроксимации, задаваемый как Тип функции, и нажать следующие три кнопки в заданном порядке:
- Оценка
Автоматическая начальная оценка параметров. Обычно первоначальной оценки достаточно чтобы перейти к аппроксимации. Если она слишком отличается от правильной может понадобиться подстроить некоторые из параметров вручную чтобы помочь аппроксимации методом наименьших квадратов найти правильный минимум. Для некоторых функций оценка использует случайную выборку из входных данных чтобы не занимать слишком много времени. Вследствие этого она является невоспроизводимой и нажатие этой кнопки снова может привести к несколько другой начальной оценке параметров.
- Быстрая аппроксимация
Аппроксимация методом наименьших квадратов используя случайную выборку входных данных. Для большого набора входных данных работает гораздо быстрее, чем полная аппроксимация, при этом в большинстве случаев она сходится к набору параметров, достаточно близких к конечным. Позволяет быстро проверить будет ли метод наименьших квадратов сходиться к ожидаемому минимуму — и одновременно получить начальный набор параметров ближе к минимуму для последующей полной аппроксимации.
- Аппроксимация
Полная аппроксимация методом наименьших квадратов используя полный набор данных. Может занять некоторое время, особенно для больших наборов входных данных и медленно вычисляемых функций.
Остаточная разница на одну точку в методе наименьших квадратов показана под вкладками как Среднеквадратичная разница. Она рассчитывается заново при каждом перерасчёте предпросмотра, т.е. не только после аппроксимации, но и после оценки и после подстройки параметров вручную.
Основные элементы управления на первой вкладке также позволяют выбрать, что будет выводиться в результате аппроксимации: либо аппроксимированная форма, либо разница между исходными данными и ней, либо оба.
Изображение предпросмотра может показывать либо входные данные, либо аппроксимирующую форму, либо разницу между ними двумя — что обычно оказывается наиболее полезным вариантом. Разница может быть показана с адаптированной шкалой цвета, где красный обозначает входные данные выше аппроксимирующей формы, синие ниже аппроксимации. Этот режим включается опцией Показывать различия с адаптированной шкалой цвета.
Вкладка Параметры показывает значения всех параметров аппроксимации и их ошибок и позволяет осуществлять точный контроль за ними. Каждый параметр может быть свободным или зафиксированным. Зафиксированные параметры не меняются никакими аппроксимирующими и оценивающими функциями, они сохраняют то значение, которое вы ввели. Когда вы меняете значение параметра вручную, изображение предпросмотра не перерасчитывается заново — необходимо нажать Пересчитать изображение чтобы обновить его. Кнопка Вернуться к предыдущим значениям позволяет вернуться к предыдущему набору параметров. Для оценки, аппроксимации или изменения вручную это означает набор значений параметров до того, как выполняемая операция их изменила. Для возврата к предыдущим это означает набор параметров до возврата — поэтому повторные нажатия на эту кнопку будут менять параметры между двумя последними наборами.
Вкладка Матрица корреляции показывает после успешной аппроксимации матрицу корреляции параметров. Коэффициенты корреляции, которые очень близки к единице (по модулю) будут подсвечены.
И наконец, вкладка Производные величины показывает различные полезные значения, рассчитанные из параметров аппроксимации. Некоторые функции не содержат производных величин, некоторые имеют несколько таких. Большая часть производных величин представляет собой параметры, которые могут оказаться более интересны для вас, чем действительные параметры аппроксимации, но плохо подходят для аппроксимации вследствие проблем с устойчивостью численного решения. Производные величины показываются с оценкой ошибок, рассчитанной используя законы распространения ошибок (включая корреляции параметров).
Типичным примером является кривизна сферической поверхности против её радиуса кривизны. В то время, как радиус является более привычным, он меняется от бесконечности до минус бесконечности когда поверхность меняется между выпуклой и вогнутой (т.е. когда становится очень близкой к плоской), что делает его неподходящим в качестве параметра аппроксимации. Кривизна, напротив, является нулевой для плоской поверхности. Следовательно, кривизна используется как параметр аппроксимации и радиус кривизны показывается как производная величина.
рекрутеров Google говорят, что использование «формулы XYZ» в вашем резюме повысит ваши шансы получить работу в Google
Более двух миллионов человек ежегодно подают заявки на работу в Google, что более чем в 20 раз превышает количество сотрудников компании в любой момент времени.
С таким объемом имеет смысл, что Google проактивно пытается сказать соискателям, что им следует делать, чтобы повысить свои шансы быть замеченными в стаде.
Среди его инструментов — серия видеороликов и статей на YouTube, в которых подробно описываются передовые методы составления резюме (они представлены ниже вместе с двумя статьями бывшего старшего вице-президента Google по кадровым операциям).
Вот некоторые из наиболее важных советов по резюме, которые предлагает компания, включая простую формулу из трех частей, которую, по словам Google, кандидаты всегда должны использовать. Даже если вы не хотите работать в Google, обратный инжиниринг их ожиданий может дать вам несколько умных идей относительно того, как попросить кандидатов подать заявку на вакансии в вашем бизнесе.
1. Базовое форматирование
Google очень редко запрашивает или даже просматривает сопроводительное письмо, поэтому на резюме много внимания.Вначале главное правило — упростить форматирование и обеспечить удобочитаемость вашего резюме. Это включает в себя такие вещи, как:
- Форматирование вашего резюме в формате pdf. В 2019 году это кажется легкой задачей, но руководства Google повторяют этот совет несколько раз, поэтому мы должны предположить, что не все делают это автоматически.
- Пропуск цели. (Они знают, какова ваша цель: получить эту конкретную работу.)
- Используйте черный текст, а шрифт и размер должны быть чистыми, простыми и последовательными.
- Проверка на наличие опечаток. Это так важно, мы повторим еще раз: проверьте на наличие опечаток.
- Использование маркированного списка. (Как вам мета-совет, если вы читаете его в виде маркера?) Не включайте длинные строки описательного текста. Поставьте себя на место человека-рецензента, который, вероятно, читает десятки резюме за раз.
- Убедитесь, что вы указали свою контактную информацию. Да, это кажется очевидным, но убедитесь, что ваше имя и адрес электронной почты хорошо видны. Если вы подаете заявку на технические должности, укажите ссылку на Github (подробнее об этом ниже).
2. Настройка
Вы должны написать новое, адаптированное резюме для каждой вакансии, на которую вы претендуете. Также рекрутеры Google советуют хранить его на одной странице.
Исключением является то, что если вы подаете заявку на должность технического или инженера, у вас есть законное право иметь большое количество соответствующих проектов для включения в список, и это может привести вас на вторую страницу.
Но почти для любого другого типа позиции одна страница является правилом.
Это также означает, что вы должны быть безжалостным редактором. Если у вас много относительного опыта, вы захотите описать все это как можно лаконичнее, но при этом донести свое сообщение.
Один конкретный совет заключается в том, что если какой-либо пункт в вашем резюме переносится на одно или два слова во вторую строку, найдите способ писать короче, чтобы он оставался на одной строке. Предлагаемое пространство составляет максимум одной страницы.
3. Используйте формулу X, Y и Z
В этом суть совета Ласло Бока, бывшего старшего вице-президента Google по кадровым операциям.Вы хотите придерживаться формата маркированного списка, который мы обсуждали, и выражать свой опыт очень конкретным образом.
Google описывает это как: «Выполнено [X], измеренное [Y], выполняя [Z]». Но чтобы было легче запомнить, давайте сократим его до X-Y-Z.
Это означает, что вы хотите сосредоточиться на достижениях — количественных результатах и влиянии, которое вы в результате оказали. Вероятно, проще всего это объяснить, используя несколько примеров из видео самих рекрутеров Google на YouTube.
Например, представьте заявителя, который хочет ясно дать понять, что он или она является членом престижной группы. Вот правильный способ, лучший способ и лучший способ описать это в резюме, согласно Google:
- ОК: «Член общества лидерства завтрашнего дня»
- Лучше: «Выбран как один из 275 для этого 12 -месячная программа повышения квалификации для талантливых и талантливых людей ».
- Best: «Выбран в качестве одного из 275 участников по всей стране для этой 12-месячной программы профессионального развития за высокие достижения в различных талантах, основанных на лидерском потенциале и академической успеваемости.«
Вот еще один пример, на этот раз для технической должности, на которой кандидат хочет указать, что он или она заняли второе место на хакатоне.
- OK:« Занял второе место на хакатоне ».
- Лучше:» Занял второе место из 50 команд на хакатоне. «
- Лучшее:» Занял второе место из 50 команд на хакатоне в NJ Tech, работая с двумя коллегами над разработкой приложения, которое синхронизирует мобильные календари.
(В данном случае последнее, «лучшее» — это моя собственная интерпретация; Google на самом деле не предлагает третьего предложения.Но я надеюсь, что суть ясна.)
Вот последний пример, предназначенный для бизнес-заявителя, который хочет показать, сколько он или она внес в качестве службы поддержки клиентов:
- ОК: «Увеличил доход для малого и среднего бизнеса. клиентов «.
- Лучше: «Увеличил доход для клиентов малого и среднего бизнеса на 10% кв / кв»
- Лучше: «Увеличил выручку для 15 клиентов малого и среднего бизнеса на 10% кв / кв за счет сопоставления новых функций программного обеспечения как решений их бизнес-целей».
Одно замечание о жаргоне: используйте сокращение вроде «QoQ» (для квартала за кварталом), только если вы на 100 процентов уверены, что рецензент резюме точно поймет, что вы имеете в виду.
4. Расширенное форматирование
Помимо основных проблем форматирования, таких как сохранение на одной странице и использование маркированных списков, есть несколько более сложных проблем форматирования, которые следует учитывать.
Вы должны быть уверены, что все организовано так, как это привыкли видеть рекрутеры и рецензенты. Правила включают:
- образование до получения опыта, если вы студент или относительно недавний выпускник, или
- опыт до образования (в обратном хронологическом порядке), если вы проработали более одной или двух должностей. .
Для недавних выпускников Google требует указать школу, степень, специализацию, средний балл успеваемости, а также месяц и год выпуска. Но чем дальше вы от колледжа, тем меньше информации о колледже и университете вы должны включать.
«Как правило, чем недавно вы учились в университете, тем больше подробностей вы должны указать здесь», — говорит технический рекрутер Google Джереми Онг в одном из видеороликов.
Единственное предостережение, и, честно говоря, это не то, к чему стремится Google, — это то, как поступить с годом окончания учебы, если вы являетесь старшим соискателем.
Есть момент, когда Google, вероятно, не хочет знать ваш возраст, чтобы уменьшить шансы когда-либо защищаться от иска о дискриминации по возрасту. Очевидно, что размещение вашего резюме о том, что вы закончили колледж в 1990 году, предполагает, что вам уже за 40.
Однако помимо этого сосредоточьтесь на вещах, которые наиболее важны для должности, и не бойтесь сокращать старые должности и достижения. особенно если они не актуальны.
Если у вас длинная история работы, которая может подтолкнуть вас к превышению рекомендованной максимальной длины в одну страницу, вы можете добавить небольшой дополнительный раздел, в котором будет упоминаться, что у вас есть другой, менее актуальный опыт, не вдаваясь в подробности.
5. Для технических кандидатов
Если вы подаете заявление на работу в техническом или инженерном секторе, есть несколько дополнительных советов.
Во-первых, добавьте ссылку на Github или ее эквивалент в верхней части своей контактной информации. (Иронично, поскольку Microsoft владеет Github с прошлого года.)
Кроме того, они хотят видеть ваши языки программирования на видном месте. И когда вы перечисляете проекты и опыт — либо в отдельном разделе, либо как часть вашей истории занятости, — включайте языки программирования, которые вы использовали для каждого проекта.
Очевидно, что это все для первого шага процесса найма — резюме и заявки — и у Google есть другие видео по более поздним этапам, например, как подготовиться к определенным типам собеседований.
Но даже как человек, который вряд ли пойдет на работу в Google или любую другую компанию в ближайшее время, я нашел полезным с точки зрения информации, которую нужно запрашивать при приеме на работу и собеседовании.
Вот ссылки, которые я обещал, в том числе две статьи Бока (здесь и здесь) и два ключевых видео на YouTube, Как работать в Google — Советы по резюме и Создайте свое резюме для Google: Советы и советы .
Мнения, выраженные здесь обозревателями Inc.com, являются их собственными, а не мнениями Inc.com.
Сложный разговор? Используйте метод XYZ.
«Моя шея», менеджер сказал: «находится на гильотине».
У этого менеджера возникла проблема с влиянием. В нем участвовала команда проекта, которая ему не подчинялась, но он отвечал за результаты.
Я тренировал его во время семинар, о чем говорить.
Его первый набросок: «Когда проект идет плохо, я чувствую себя обезумевшим, из-за моей шеи. . . »
лет назад я узнал и затем модифицированный метод изложения вашего случая из прекрасной книги Роберта Болтона «Навыки людей».
Формат (измененный) звучит так: «Когда происходит X, я чувствую Y из-за Z».
X — это проблема; Y ваш реакция; Z, влияние на бизнес.
Давайте рассмотрим гильотинированный XYZ менеджера:
X: «Когда проект проваливается.”
Plus : Его X избегает атаки или обвиняя. Он не сказал: «КОГДА ВЫ ВИНТИТЕ проект ».
Минус : Что он имеет в виду под «Проект идет плохо?»
Я представляю себе испорченную еду — она закопана в офисном холодильнике, как археологическая реликвия.
Вы задаетесь вопросом, какая группа продуктов питания могла это, возможно, принадлежало?
Лучше не удивляться, либо о еде, либо о сообщениях.
Давайте конкретизируем .Что за Менеджер действительно имел в виду: «Когда мы не успеваем в срок».
Хорошо, скажи так.
Y: «Я расстроен».
Plus : сказать, что вы чувствуете говорит другому человеку, что проблема важна.
Минус : «Обезумевший» слишком эмоционально для бизнеса. Это как говоря: «Когда мы пропускаем дедлайн, Я ЧУВСТВУЮ, ЧТО ВЫ ЗАБРОШЕННЫМ».
Это тяжело.
Что подходит для бизнеса эмоция? Попробуй «обеспокоен».”
Вы можете быть обеспокоены тем, что проект опаздывает, обеспокоен тем, что клиенты будут недовольны, обеспокоен тем, что в момент отчаяния, вы, вероятно, съедите таинственную пищу из фрига и умрете от пищевое отравление.
«Обеспокоенные» обложки все это с изяществом и без забот.
Z: «Потому что моя шея на кону».
Plus : Подлинный.
Минус : влияние на бизнес должен быть больше любой части вашего тела, независимо от того, выглядите вы или нет хороший.
Лучше: «Потому что на кону наша репутация», или «потому что, если мы пропустим крайний срок, это вредит нашим клиентам».
Давайте объединим эти XYZ : «Когда мы пропускаем крайний срок, меня беспокоит влияние на наши клиенты.»
Обратите внимание, что вы не наложили решение. Это следующий шаг — диалог.
Совет : нужно влиять другие? Убедитесь, что ваше сообщение хранится их обручили.
П.С. Лучшие коммуникаторы на практике.Обратите внимание на эти два бостонских мастерских плюс . . .
(семинар ½ дня) Сила присутствия: максимизируйте свое личное влияние , 30 марта (13-16: 30)
(2-дневный семинар — ограниченное количество / 7 человек) Динамическая речь: услышать, запомнить и получить результаты , 4–5 мая (21–17 часов)
Но, может быть, вы предпочитаете быструю и удивительно интересную книгу:
У ВАС 8 СЕКУНД: секреты общения для отвлеченного мира , названная одной из лучших книг о бизнесе года малоизвестной, но явно блестящей канадской газетой.Доступен в печатном виде, в розжиге, в аудио.
«Практичный и забавный, это отличное чтение для всех, кто хочет иметь большее влияние на работе. Хеллман овладел искусством общения, и он откроет вам секреты . Настоятельно рекомендуется.»
— Тим Сэгер, исполнительный вице-президент и главный директор по исследованиям и разработкам, iRobot
ПОЛ HELLMAN консультирует и говорит на международном уровне, как донести вашу точку зрения — быстро, сосредоточенный, мощный.За дополнительной информацией обращайтесь по телефону 508-879-0934 или по электронной почте. [email protected]
П.С. . Нажмите здесь , чтобы получить эти быстрых советов.
© Авторское право 2020 Пол Хеллман. Все права защищены
XYZ Управление запасами
Что это?
XYZ-анализ — это способ классифицировать товарно-материальные запасы в соответствии с изменчивостью их спроса.
- X — Очень небольшое изменение: X позиций характеризуются стабильным оборотом с течением времени.Будущий спрос можно надежно спрогнозировать.
- Y — Некоторые вариации: хотя спрос на товары Y нестабилен, колебания спроса в определенной степени можно спрогнозировать. Обычно это происходит потому, что колебания спроса вызваны известными факторами, такими как сезонность, жизненный цикл продукта, действия конкурентов или экономические факторы. Точно спрогнозировать спрос сложнее.
- Z — наибольший разброс: спрос на товары Z может сильно колебаться или возникать спорадически. Отсутствуют тенденции или предсказуемые причинные факторы, делающие невозможным надежное прогнозирование спроса.
Следующие диаграммы иллюстрируют характеристики трех классов.
Классы имеют большое значение для управления запасами. Из-за низкой волатильности спроса управление запасами класса А обычно можно полностью автоматизировать. А из-за предсказуемости спроса запасы с низким буферным запасом могут поддерживаться либо самой организацией, либо поставщиком, что снижает затраты на хранение.
Для товаров класса B может потребоваться больше буферных запасов, или может потребоваться большее ручное вмешательство в процесс управления запасами, который в противном случае был бы автоматизирован.Согласование с поставщиками JIT может быть труднее согласовать для запасов класса B, поскольку поставщики могут не иметь опыта для прогнозирования спроса, который будет у самой организации.
Поскольку практически невозможно предсказать спрос на товарные запасы класса C, политика может заключаться в пополнении запасов на заказ.
Изменчивость спроса на товарные запасы может быть выражена как коэффициент вариации. Шаги для классификации товаров по степени волатильности спроса:
- Определите элементы для включения в анализ.
- Рассчитайте коэффициент вариации для каждого элемента.
- Отсортируйте элементы, увеличивая коэффициент вариации, и накапливайте.
- Согласуйте и установите границы между совокупными коэффициентами вариации.
Чтобы XYZ-анализ работал, важно понимать и применять соответствующий временной интервал для оценки волатильности спроса. Например, если спрос на товары носит сезонный характер, вычисление волатильности за месяц может оказаться неприемлемым. В качестве альтернативы, если жизненные циклы продуктов короткие, расчет нестабильности товаров со спорадическим спросом может означать, что товары, хранящиеся на складе, устареют.
Стоимость товаров также может влиять на политику управления запасами. Например, некоторые товары класса A могут быть дорогими, и организация может не захотеть полагаться на полностью автоматизированное пополнение запасов. С другой стороны, некоторые предметы класса C могут иметь очень низкую стоимость. Таким образом, может быть более рентабельным (и улучшающим обслуживание клиентов) вручную устанавливать буферы и автоматизировать пополнение для поддержания буферов, а не пополнять их по заказу. Комбинирование подходов ABC с XYZ — полезный способ размышления о политике управления запасами.
Какие преимущества дает этот подход?
- Повышает точность прогнозирования.
- Снижает дефицит, что:
— Повышает стабильность и эффективность производства.
— Повышает удовлетворенность клиентов. - Увеличивает отток запасов.
- Уменьшает устаревание складских запасов.
- Разъясняет уровни обслуживания для товаров с нестабильным спросом.
Осуществление управления запасами XYZ? Вопросы для рассмотрения
- Есть ли надежная и доступная информация о стоимости и спросе по каждой позиции?
- Будут ли ваши системы и процессы управления запасами способствовать эффективному внедрению и использованию подхода XYZ?
- Были ли подсчитаны затраты и выгоды от внедрения и эксплуатации XYZ и убедительно ли экономическое обоснование?
- Было ли оценено и запланировано влияние перехода на XYZ на возможности?
| Действия, которые необходимо предпринять / Dos | Действия, которых следует избегать / чего нельзя делать |
|
|
| Связанные и похожие практики, которые необходимо учитывать | |
|
Беседы по вопросам подотчетности: метод XYZ — советы и инструкции
Позвольте мне предоставить вам простой, но мощный сценарий, который вы можете использовать в качестве шаблона для неудобных разговоров, когда вам нужно придерживаться границ… не ходя по яичной скорлупе.
Он называется методом X, Y, Z и состоит из трех частей: Когда вы выполняли X в ситуации Y, я чувствовал Z.
Это может звучать примерно так; «Когда вчера вечером вы пришли домой через час после комендантского часа, я забеспокоился». Или привести другой пример; «Когда ты вчера после школы оставил пальто на полу в гостиной, я почувствовал разочарование».
Вы не хотите сказать что-то вроде: «Когда ты вчера после школы оставил пальто на полу в гостиной, мне показалось, что ты не уважаешь мое время.»
Так что в этом плохого?
Проблема в том, что сказать, что вы не уважаете и не цените мое время, не разделяете чувства, а делаете утверждение. Вы высказываете предположение о мыслях, чувствах и намерениях вашего ребенка. Ваш ребенок, не уважающий ваше время, может быть одним из возможных объяснений того, почему он решил бросить пальто посреди гостиной и оставить его там, но это не единственное объяснение. Могли быть и другие. Представьте, что вы приходите ко мне и говорите: «Я сейчас голоден», а я отвечаю: «Нет, это не так.Вы просто устали ». Как я мог знать, что вы думаете и чувствуете в своем собственном разуме и теле? Как я мог, как сторонний наблюдатель, быть достаточно высокомерным, чтобы думать, что я знаю о вашем внутреннем опыте больше, чем вы? Единственный человек, который когда-либо жил в вашем собственном разуме и теле, — это вы. Та же идея применима к вашему ребенку и любому другому человеческому существу в этом отношении. У вас могут быть теории и вопросы, но, в конце концов, разум вашего ребенка — это черный ящик Невозможно с уверенностью знать, что внутри него, а что нет.Вы не можете точно знать, почему ваш ребенок делает то, что он делает, его мысли, чувства, убеждения, мотивации. Все, что вы действительно знаете наверняка, — это то, что наблюдается снаружи, поведение или то, что было сказано, и вы можете составить историю о том, почему вы думаете, что такое поведение произошло, но это история, и это история, которая может или не может быть правдой.
Проще говоря, утверждение «я чувствую» никогда не должно содержать слова «ты». «Ты» часто воспринимается как обвинительный. Поэтому обычно запускается режим защиты.Точно так же, если вы скажете: «Я расстроен», никто не сможет с этим спорить. Вот как ты себя чувствуешь. А поскольку вы единственный человек, который когда-либо жил в своей голове, вы должны быть окончательным и окончательным авторитетом в том, что вы думаете или чувствуете. С другой стороны, с историями и предположениями легко поспорить. Итак, ваш ребенок может ответить, сказав; «Нет, нет, нет. Дело не в том, что я не уважаю твое время, просто я забыл». Подводя итог, я чувствую, что утверждения, в которых говорится, что я разочарован или обеспокоен, или какое-то другое особое слово эмоции — это хорошо.Сказать: «Я чувствую себя идиотом» — нехорошо.
Разве так неловко разговаривать? Оставаться нейтральным и спокойным, описывая вещи консервативным, чисто фактическим языком?
да. Это очень неудобно. Обычно люди так не разговаривают в обычном повседневном разговоре. Ваш ребенок, вероятно, задастся вопросом, какие странные уроки воспитания вы посещаете? Да, вероятно, они будут, но в том-то и дело.
Это должно звучать немного странно и немного неловко, потому что странные вещи прерывают естественный поток.Они привлекают наше внимание и заставляют нас сесть и обратить внимание на то, что мы на самом деле говорим или делаем. Когда мы говорим экспромтом, говоря все, что приходит в голову в пылу момента, есть большие шансы, что наше разочарование, наши ядовитые внутренние истории и наш сарказм просочатся наружу и сорвут разговор еще до того, как у него появится шанс начаться. Так что да, ваш ребенок может приподнять бровь и подумать, что вы какой-то странный. Они могут даже пожаловаться, что вы похожи на робота-терапевта, но это гораздо лучший результат по сравнению с рискованной альтернативой взрывного конфликта, обидных чувств и испорченных отношений.Со временем эти коммуникативные модели начнут становиться для вас более естественными, и тогда вы сможете говорить непредсказуемо, без необходимости так неукоснительно следовать этому сценарию X, Y, Z. Но когда вы только начинаете, вам нужна практика, поэтому, пожалуйста, неукоснительно следуйте сценарию. Убедитесь, что вы действительно усвоили основы, прежде чем начинать импровизировать и слишком много что-то менять. Думайте об этом как о тренировочных колесах на велосипеде. Они помещены туда, чтобы вы не разбились и не поранились.Когда-нибудь, при наличии достаточной практики, вы сможете снять тренировочные колеса и свободно кататься. Но до тех пор тренировочные колеса служат ценной и необходимой цели.
Хотите больше? Это отрывок из нашего 8-недельного курса «План подотчетности». Получите дополнительную информацию о курсе и зарегистрируйтесь здесь.
Получите работу с X-Y-Z резюме — Центр управления карьерой
Для будущих выпускников колледжей поиск работы — непростая задача со множеством неконтролируемых переменных.Независимо от степени тщательной подготовки, отличных учеников все равно можно упустить из виду по неизвестным причинам. Один из способов убедиться, что студенты встанут на верную ногу в поиске работы, — это профессионально составленное резюме.
Создание увлекательного резюме означает оттачивание конкретных достижений, что для некоторых может оказаться сложной задачей. Но тщательное руководство карьерными службами может превратить написание резюме из нервирующего в поучительное.
Формат X-Y-ZЕсть много формул для успешного написания резюме.Google, один из самых желанных работодателей нашего времени, недавно поделился руководством по созданию ярких резюме для тех, кто хочет присоединиться к их команде. Google рекламирует формат резюме X-Y-Z, описывая его как выполненное [X], измеренное [Y], путем выполнения [Z]. Лучше сократить до X-Y-Z резюме.
По сути, этот формат — это легкий для чтения, краткий и практичный способ понять суть достижений соискателя. Однако у будущих выпускников колледжа не так много достижений, чтобы рассказать о том, почему они подходят для этой роли.
Вот как вы можете помочь студентам выделиться, составив резюме, ориентированное на достижения, используя формат резюме X-Y-Z:
Оценить опыт и измерить достиженияТеперь, когда у учащегося была возможность оценить свой опыт — X в этом уравнении для написания резюме — пришло время измерить его (Y). Это измерение должно иметь цифру, чтобы рекрутер или менеджер по найму быстро поняли ситуацию.Попросите вашего ученика просмотреть свой список опытов или достижений и вывести его на следующий уровень, добавив критерий успеха, который в конечном итоге приведет его к Z.
В своем резюме ваш ученик мог указать свою избранную должность в качестве председателя по найму женского общества. Побуждайте учащихся к достижению таких достижений на новом уровне, оттачивая успех в числовых показателях. Вот пример формата резюме X-Y-Z:
- Good: Кресло для набора персонала, Alpha Chi Omega
- Лучше: Первая сестра была выбрана председателем по найму два года подряд на основе разработки весьма успешной программы найма.
- Лучшее: Первая сестра была выбрана председателем по подбору персонала два года подряд на основе разработки весьма успешной программы подбора персонала, которая увеличила набор на 45% за один семестр.
Добавленные детали измерения и сравнения направят усилия ваших студентов на поиск того, как их работа отличает их от других кандидатов. С мышлением X-Y-Z даже небольшие достижения могут превратиться в нечто большее.
Форматирование — это всеПри составлении резюме X-Y-Z учащиеся должны сосредоточиться на кратком обзоре всего, чего они достигли.Ваши ученики могут столкнуться с проблемами, когда дело касается деталей и длины того, что они пытаются выразить. Это быстро исправляется тщательным форматированием.
Студенты должны использовать маркированный список для раздела своего опыта. Каждый пункт должен начинаться с глагола действия, такого как создано , разработано или разработано — эти слова обеспечивают немедленную ясность для читателя и помогают выделить достижения.
Опять же, структура предложения в формате X-Y-Z должна выглядеть так: глагол действия, достижение, измерение, детали того, что вы сделали для достижения своей цели.Данные и сравнения обеспечивают контекст и поток. Вот пример правильного форматирования:
- Трижды отмечен званием сотрудника месяца в 2019 году за отличные навыки обслуживания клиентов и достижение 100% удовлетворенности по результатам 50 опросов клиентов после транзакции.
Студенты также должны адаптировать свое резюме для каждой вакансии, на которую они претендуют. Это может включать реорганизацию их раздела опыта или добавление и удаление вещей, которые могут быть более актуальными для роли.
В целом, формат резюме X-Y-Z поможет вашим ученикам выделиться из толпы и быстро понять их различные достижения.
____________________
ОБ АВТОРЕ:Вал Матта
Валь Матта является совладельцем и руководителем отдела развития бизнеса в CareerShift, комплексном решении для поиска работы и управления карьерой для компаний, аутплейсмент-компаний, соискателей и университетских центров карьеры. Вы можете связаться с ней и командой CareerShift в Facebook, LinkedIn и Twitter, LinkedIn.
ABC XYZ Analyze для оптимизации вашего инвентаря
Анализ ABC XYZ имеет основополагающее значение для оптимизации ваших запасов .Метод ABC — очень хорошее начало, но этого недостаточно для управления запасами, и я объясню на примерах, почему.
(ABC XYZ Analyze video / Пожалуйста, активируйте субтитры автоматики на английском языке)
Метод ABC недостаточно
Если вы никогда не слышали о классификации ABC, я советую вам сначала ознакомиться с нашей статьей или видео по этому поводу. Я подробно объясню вам, что такое анализ ABC и как его настроить, с примерами для загрузки в Excel.Преимущество этого ABC-анализа заключается в том, чтобы сосредоточить ваше время и энергию на продуктах, которые представляют ваши самые большие продажи , но также и являются наибольшим запасом для вашей компании.
Анализ ABC — очень хорошее начало, но мы часто находим 2 классических ошибки в компаниях:
- Во-первых: код A является сильной продажей, поэтому вы должны обеспечить большой охват запасов, чтобы не пропустить ни одной продажи.
- Второе: наоборот, мой код A — это сильная продажа, и, поскольку это сильная продажа, мы считаем, что продажи очень стабильны.В результате мы обеспечиваем очень низкий уровень покрытия запасов.
Эти два утверждения неверны, потому что все зависит от неопределенности продаж.
Пример: ABC XYZ Analyze
У вас есть десять товаров, 2 товара, код A. Первый товар 1 обеспечивает чрезвычайно стабильный ежемесячный оборот, а второй — эквивалентный общий оборот, но с совершенно другим ежемесячным оборотом. Из-за этого, конечно, у вас низкий риск по первому предмету и вы можете назначить низкое покрытие запасов.С другой стороны, по статье 2 у вас очень высокая волатильность, и поэтому вам нужно будет увеличить запасы, чтобы покрыть этот риск (см. Ниже).
В этом весь смысл анализа ABC XYZ, с одной стороны, вы будете классифицировать по объему с помощью анализа ABC, а с другой стороны, вы будете классифицировать по неопределенности с помощью анализа XYZ, и поэтому этот метод очень полезен в управлении запасами, чтобы выявлять продукты, подверженные риску, будь то риски дефицита или затоваривания, чтобы определить правильное покрытие запасов и правильный страховой запас.Наконец, он широко используется в промышленности для оптимизации объемов производства на основе объемов и неопределенности.
Какова цель анализа ABC XYZ?
Что такое неопределенность?
Это факт, что мы не прогнозируем спрос и не прогнозируем продажи продукта. Часто характеризуется нестабильностью продаж. Несколько типов продуктов: очень стабильные и очень предсказуемые продукты (X). Тогда у вас будут менее стабильные, но все же вполне предсказуемые продукты (Y). Наконец, у вас есть продукты, которые являются совершенно нестабильными и совершенно непредсказуемыми продуктами (Z).
Резюме этого анализа ABC XYZ представляет собой матрицу из девяти категорий . С одной стороны у вас есть продукты ABC, а с другой — продукты XYZ. Затем каждый продукт идентифицируется как:
- AX : большие объемы, стабильные
- AY : большие объемы, немного менее стабильные и, следовательно, более изменчивые
- AZ : большие объемы, очень изменчивые
- BX : средние объемы, стабильные
- BY : средние объемы, летучие
- BZ : средние объемы, очень летучие
- CX : низкие объемы, стабильные
- CY : низкие объемы, летучие
- CZ : низкие объемы, очень летучие
Как классифицировать ABC XYZ в Excel?
Во-первых, вам нужно смешать исторические данные с вашими прогнозами, например, исторические данные за 6 месяцев и прогнозы за 6 месяцев.Если у вас есть только истории, это тоже хорошо. Я также советую вам мыслить в терминах стоимости, а не количества.
У вас есть ABC-анализ, а для XYZ-анализа вам понадобится коэффициент вариации. Есть разные способы рассчитать этот коэффициент вариации. Я объясню вам один из них, он очень простой. Вы возьмете стандартное отклонение ряда и, следовательно, последних месяцев.
Стандартное отклонение — это среднее отклонение от среднего значения.Чем нестабильнее ваш ряд, тем выше будет стандартное отклонение. Вы разделите целое на среднее значение той же серии, и поэтому, в конце концов, чем стабильнее ваш продукт, тем ближе процент к нулю.
Благодаря этим процентам вы сможете использовать Excel IS для определения ваших XYZ на основе процентов. Эта автоматическая формула позволит вам определить ваши продукты AX, AY, AZ…
Как использовать эту классификацию в управлении запасами?
Если ваши продукты AX или BX , они очень стабильны, вам не нужно много запасов , вам нужно низкое покрытие запасов, потому что риск нехватки низок.
Когда ваши продукты составляют AY или BY , вы можете взять среднее покрытие запасов , потому что риск находится под контролем. Если ваши продукты AZ или BZ , то есть очень неопределенный с большими объемами, вам понадобится более широкий охват запасов (если стоимость запасов не слишком высока), потому что риск нехватки очень высок. Наконец, у вас низкие продажи. По определению, вам не нужно много инвентаря.
Риск низок для CX , но, как правило, эти продукты очень редки, потому что при низких продажах продажи , как правило, очень неопределенны. Тогда у вас есть продукты CY , такие небольшие запасы с контролируемым риском, которые по-прежнему требуют небольшого покрытия запасов. И, наконец, последние, которые представляют большинство продуктов, — это продукты CZ . У вас есть высокий риск затоваривания, особенно не складывайте эти продукты в большом количестве или вообще не складывайте их. Эти продукты CZ представляют собой большую часть избыточных запасов, и я советую вам иметь некоторые из этих продуктов только в наличии на заказ.
Заключение ABC XYZ Анализ
Подводя итог с точки зрения покрытия запасов, вот вымышленный пример и то, что я бы сделал. Вы можете увидеть большой охват высоких продаж с большой неуверенностью, чтобы не пропустить продажи. Вы можете оптимизировать и сократить охват инвентаря по продуктам с низкой неопределенностью, что позволит мне значительно увеличить денежный поток.
Наконец, при низких продажах, даже если у меня есть большая неуверенность, я не советую вам иметь много запасов, потому что это низкие продажи, и поэтому они будут генерировать больше запасов, чем потерянные продажи.
Я надеюсь, что благодаря этой статье вы поняли важность использования классификации XYZ в управлении запасами. Для тех, кто хочет пойти дальше, вы можете получить доступ к другим примерам с почти 2000 статьями за 52 недели. Сначала я покажу вам, как полностью автоматизировать анализ ABC.
Затем я возвращаюсь к коэффициенту вариации, а также к тому, как правильно определять переменные для определения XYZ, как иметь автоматический отчет, который показывает количество продуктов при изменении стоимости, как автоматически обновлять охват вашего инвентаря в соответствии с вашим классификация элементов с помощью формул и, наконец, я расскажу вам об альтернативном методе расчета неопределенности.
Скачать Excel ABC XYZ Анализировать и идти дальше
Если вы хотите узнать, как реализовать свою первую классификацию ABC XYZ шаг за шагом с бизнес-примером и шаблоном Excel, откройте для себя наш новый онлайн-курс ABC XYZ здесь
(PDF) Значение интегрированного многокритериального метода ABC-XYZ для процесса управления запасами
М. Стоянович и др. Значение интегрированного многокритериального метода ABC-XYZ для
Процесс управления запасами
Управление запасами представляет собой очень важный сегмент бизнеса
, проводимого современными предприятиями, и как таковой имеет решающее значение для успеха предприятия
. деловые операции.Именно по этой причине требуется тщательный мониторинг
, а также постоянное улучшение в соответствии с современными стандартами
. Уровень запасов продукции, имеющейся на предприятии, должен составлять
в соответствии с потребностями рынка, то есть с оценкой спроса на конкретный период
. Целью управления запасами является определение количества из
запасов продукции, достаточного для непрерывного удовлетворения требований рынка
и снижения затрат, связанных с хранением запасов.
Первым шагом в определении ожидаемого спроса является сбор и
систематизация частей информации о предыдущей продаже и движении товаров
по цепочке поставок. Торговые предприятия имеют в своем ассортименте большое количество товаров (
), поэтому существует необходимость в классификации таких товаров и создании системы, в которой движение запасов будет регистрироваться и контролироваться
.Затем необходимо определить методологию управления запасами.
В этой работе представлена методология, основанная на периодическом обзоре и оценке запасов продукции
и ожидании спроса, а также сделано предложение
в отношении деятельности и темпов выполнения запасов, полученных на основе
. основа классификации ABC-XYZ. Работа состоит из обзора литературы
,, методической части, а также практического примера.
Предмет исследования — анализ товарно-материальных запасов Win Win Shop d.o.o.
(общество с ограниченной ответственностью) предприятие розничной сети на территории Сербии.
Компания ведет бизнес на территориях Боснии и Герцеговины,
Черногории и Сербии. В настоящее время в Сербии действует 101 розничный магазин. В ассортименте компании
большой выбор IT-оборудования, AV-оборудования,
бытовой техники, небольших бытовых гаджетов, устройств видеонаблюдения,
часов, ювелирных изделий, детских игрушек, медицинских приборов и многих других устройств.Win Win
Shop стремится сохранить и продвинуть свои позиции на рынке. Она стремится к
улучшить свою основную деятельность, которая подразумевает сектор ИТ, а также занять позицию
лидера в других бизнес-нишах для других продуктов в предложении.
Его основная цель — дать клиентам как можно больше за вложенные
денег, ценив их время и лояльность. Win Win является партнером
самых известных мировых брендов и производителей, таких как: HP (ноутбуки, компьютеры, серверы
, принтеры, мониторы, картриджи с тонером…), Asus (ноутбуки, нетбуки, мониторы, материнские платы
, графические карты…), Acer (ноутбуки, нетбуки, планшеты и мониторы),
Del (ноутбуки и мониторы), Toshiba (ноутбуки и мониторы), Lenovo (ноутбуки),
MSI (ноутбуки, материнские платы, графические карты…), Fujitsu (ноутбуки), Samsung HP
(ноутбуки, планшеты, мобильные телефоны, мониторы, принтеры, тонеры…), ViewSonic
(мониторы и планшеты) и многие другие.
Цель — сделать максимально выгодное предложение во всех сегментах ведения бизнеса,
отличные цены, рассрочка платежа, большой выбор, широкое предложение из
технических товаров.