 Бизнес-Блог Блоготей Бизнес-Блог «Блоготей» — информационный блог о бизнесе и финансах. Полезные статьи и новости из мира бизнеса, финансов, банков, экономики, инвестиций.
Бизнес-Блог Блоготей Бизнес-Блог «Блоготей» — информационный блог о бизнесе и финансах. Полезные статьи и новости из мира бизнеса, финансов, банков, экономики, инвестиций. 
Программа искусственного интеллекта ЭЛИС
Программа искусственного интеллекта ЭЛИС.
Система искусственного интеллекта ЭЛИС представляет собой программное обеспечение, способное разговаривать как человек на простом языке, управлять устройствами, а также обучаться. С помощью данной программы можно общаться с компьютером, а также взаимодействовать с физическим миром. Программа также использует возможность подключения Ардуино, чтобы создавать системы умного дома, автоматики и т.д.
Скачать программу искусственного интеллекта ЭЛИС
Описание программы искусственного интеллекта ЭЛИС
Модули программы искусственного интеллекта ЭЛИС
Описание программы искусственного интеллекта ЭЛИС:
Программа искусственного интеллекта ЭЛИС – Электронно Логически Интеллектуальная Система. Система искусственного интеллекта ЭЛИС представляет собой программу. Это программное обеспечение, способное разговаривать как человек на простом языке, управлять устройствами, а также обучаться. Данная система не является ассистентом, так как упор идёт на разработку человекоподобной системы, которая сможет обучаться как ребёнок и вести осознанный диалог.
С помощью данной программы можно общаться с компьютером, а также взаимодействовать с физическим миром. Программа также использует возможность подключения Ардуино, чтобы создавать системы умного дома, автоматики и т.д.
Система искусственного интеллекта ЭЛИС построена по модульному принципу. Система универсальна и её функционал наращивается с помощью модулей. Модули могут быть различные, от простых, до сложных.
Программа искусственного интеллекта ЭЛИС самостоятельно ведет диалог с человеком.
Она может самостоятельно начать диалог, может делать это несколько раз, что уже отличает её от голосовых асистентов, которые работают по структуре вопрос – ответ. Программа искусственного интеллекта ЭЛИС самостоятельно принимает решение после того, что скажет человек, и если не знает, её можно обучить.
При поддержке диалога с пользователем система сама обучается. Система способна запоминать несколько ответов на один или множество вопросов и иметь несколько вопросов на один или множество ответов.
Программа искусственного интеллекта ЭЛИС полностью совместима с платформой Ардуино, поэтому можно управлять любыми устройствами. Можно попросить у системы включить свет, система спросит, где именно включить, но можно попросить включить свет сразу в определённом месте, тогда она не будет переспрашивать.
Программа искусственного интеллекта ЭЛИС также способна запускать сторонние приложения и т.д.
Модули программы искусственного интеллекта ЭЛИС:
В настоящий момент программа искусственного интеллекта ЭЛИС включает следующие модули:
– модуль «Знания» – модуль поиска информации по WIKIPEDIA. Система знает любое устройство, предмет и так далее, Спросите например, что такое велосипед или что такое яблоко и система расскажет, что это такое,
– модуль «Новости». Свежие новости на интересы пользователя. Просто спросите, какие новости или расскажи новости, система расскажет и спросит, надо ли рассказать ещё, ответив да, она расскажет ещё,
– модуль «Погода». Погода на сегодня и на завтра по моему городу. Можно узнать температуру, влажность, скорость ветра, будет ли дождь или мороз. Можно спросить, брать ли зонтик сегодня или можно ли одеть сегодня шорты,
– модуль «Калькулятор». С помощью данного модуля, система умеет складывать, вычитать, умножать и делить предметы и т.д. Например спросив, сколько будет два яблока плюс два яблока, система ответит четыре яблока. Модуль в разработке,
– модуль «Будильник». Модуль позволяет устанавливать любое количество будильников. Установив будильник, система Вас разбудит. Просто надо сказать, разбуди меня в 7 утра. Модуль в разработке,
– модуль «Корректировка ответов». Правильная расстановка знаний в базе,
– модуль «Праздники, именины, события». Данный модуль позволяет узнать, кому сегодня день имени или какой сегодня праздник,
– модуль «Тосты». Модуль позволяет системе говорить различные тосты. Надо попросить, скажи тост,
– модуль «Анекдоты». Система знает тысячи анекдотов. Просто попросите её рассказать анекдот, так-же можно попросить рассказать анекдот для взрослых,
– модуль «Стихи». Данный модуль превращает систему в поэта. Просто попросите рассказать стих, так-же можно попросить рассказать стих для взрослых,
– модуль «Афоризмы». Система знает тысячи афоризмов. Просто попросите её сказать афоризм, так-же можно попросить сказать афоризм для взрослых,
– модуль «Управление освещением». С помощью данного модуля, система умеет управлять освещением квартиры или дома. Для этого надо подключить Arduino и Ethernet Shield,
– модуль «Угадывание цифры». Система пытается угадать загаданную цифру. Называет предполагаемую цифру, после надо ей сказать, больше или меньше. Модуль в разработке,
– модуль «Пользователь». Модуль позволяет изменять данные пользователя, имя, город и т.д. Например чтобы поменять имя, надо сказать, запомни меня зовут Олег и она запомнит,
– модуль «Диалог». Анализ диалога. Модуль, который обрабатывает диалог за сутки, анализируя пользователя, обучаясь и т.д.
Примечание: описание технологии на примере программы искусственного интеллекта ЭЛИС.
карта сайта
искусственный интеллект написать программу онлайн программа пишет программы
искусственный интеллект программа для андроид для управления компьютером 2016 скачать с торрента программы голосовые скачать программу бесплатно
лучшие программы искусственного интеллекта
новейшие программы с искусственным интеллектом
программа для создания искусственного интеллекта
программа виртуальная девушка искусственный интеллект
программа голосовой искусственный интеллект для компьютера скачать
nai программа искусственного интеллекта для пк скачать торрент для компьютера с голосом 2016 скачать
программа использующая искусственный интеллект
программы поиска в системах искусственного интеллекта
рабочая программа дисциплины теория искусственного интеллекта искусственный интеллект
самообучающиеся программы искусственного интеллекта
системы искусственного интеллекта рабочая программа
скачать программу для создания искусственного интеллекта на компьютер 2017 для windows 7 с голосом
скачать программу элис настоящий искусственный интеллект
скачать самообучающуюся программу искусственного интеллекта на компьютер
Коэффициент востребованности 18 546
xn--80aaafltebbc3auk2aepkhr3ewjpa.xn--p1ai
имитация интеллекта, обман и реальные достижения / Mail.ru Group corporate blog / Habr

С каких пор программы научились выдавать себя за людей? Каким образом понять, искусная ли перед нами обманка или по-настоящему сильный ИИ? Когда программа справится с машинным переводом или напишет свой первый роман? Сергей oulenspiegel Марков, автор материала «Играть на уровне бога: как ИИ научился побеждать человека», возвращается к теме умных машин в нашей новой нейронной статье.
В конце 30-х годов прошлого века, когда еще не были созданы первые электронные вычислительные машины, вопросами «разумности» машин стали задаваться специалисты по computer science. Если нечто выглядит как кошка, мяукает как кошка, ведет себя как кошка, в любом эксперименте проявляет себя как кошка, то, наверное, это кошка. Эту идею сформулировал Альфред Айер — английский философ-неопозитивист, представитель аналитической философии.
Всеми нами любимый Алан Тьюринг был более социализирован, чем Айер. Тьюринг любил ходить на вечеринки, а в то время среди интеллектуальной публики была распространена интересная забава — «Игра в имитацию». Заключалась игра в том, что девушку и парня запирали в две разные комнаты, оставляя под дверью широкую щель, в которую участники игры могли просовывать записки с вопросами. Человек, который находился в комнате, писал на вопросы какие-то ответы. Задачей игры было угадать, в какой комнате находится парень, а в какой — девушка. Тьюринг предположил следующее: «А давайте мы будем похожую процедуру использовать для того, чтобы понять, создали ли мы тот самый универсальный ИИ».
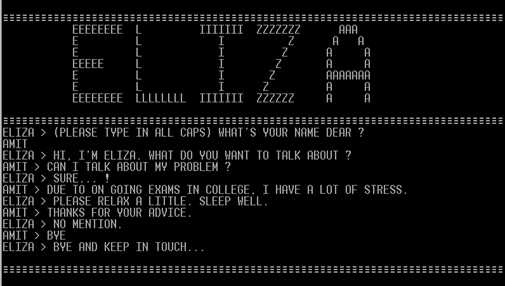
Первая программа, которая могла общаться с человеком путем определенной переписки — это ELIZA, созданная в 1966 году. Программа пыталась выдать себя в эксперименте не просто за человека, а за психиатра. Ее стиль общения носит пародийный характер. То есть она говорит на специфическом психиатрическом жаргоне, задает соответствующие типовые вопросы. В принципе, эта программа представляет собой большой набор правил, по которому она находила определенные паттерны в речи человека. В ответ на наличие соответствующего паттерна входной информации, ELIZA определенным образом трансформировала его и выдавала информацию на выход.
Программа могла в некоторых ситуациях людей одурачить. Был проведен эксперимент «AOLiza», когда программа общалась через сеть America Online со случайно выбранными пользователями, и многие из них не догадывались, что в данном случае с ними общалась машина. Понятно, что этот эксперимент нельзя считать хоть каким-то серьезным приближением к прохождению теста Тьюринга.
Cамо название программы ELIZA произошло от имени героини Бернарда Шоу из пьесы «Пигмалион», повествующей о том, как лондонский профессор фонетики Генри Хиггинс пытается из девушки, представительницы общественных низов, сделать настоящую леди, обучая ее правилам поведения и языку высшего общества.
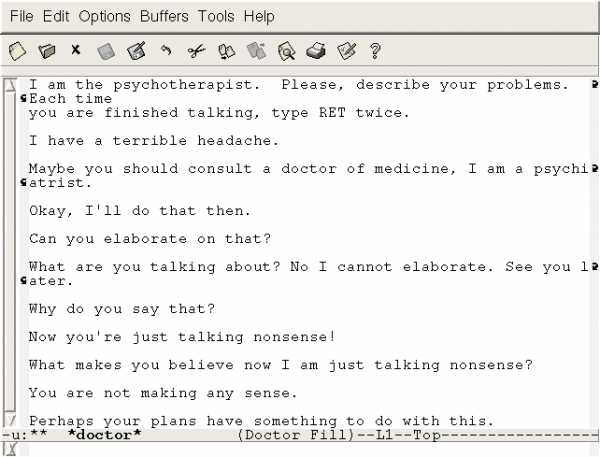
Интересно, что вторая программа такого рода (чат-бот), созданная в 1972 году Кеннетом Колбаем из Стэнфордского университета, была в своем роде шуточной дискуссией с авторами программы ELIZA. Она называлась PARRY. Если ELIZA пыталась выдать себя за врача, то программа PARRY пыталась выдать себя за пациента. PARRY считала себя параноидальным шизофреником.
Интересно, что программа хорошо обманывала профессиональных психиатров. В экспериментах оказалось, что 48% психиатров не в состоянии понять, имеют ли они дело с человеком или с программой. Но здесь, опять же, никакой чистоты эксперимента не было. Если у человека существуют определенные дисфункции, то его поведение может в некоторых ситуациях быть достаточно автоматическим.
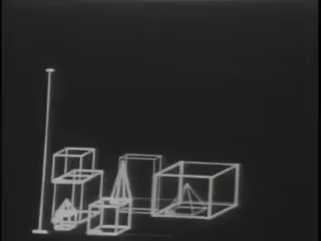
Интересная разработка тех времен, которая произвела очень большое впечатление – это программа SHRDLU. Название SHRDLU образовано от ETAOIN SHRDLU — так расположены алфавитные клавиши на линотипах (в соответствии с убыванием частоты появления букв в английском языке). Как, к примеру, сейчас ЙЦУКЕН и ФЫВАПРОЛДЖ.
У SHRDLU был небольшой мир, в котором было представлено ограниченное количество объектов. Это были пирамидки, различные кубики, коробка. И SHRDLU умела общаться на естественном языке с человеком, обсуждая то, что происходит в этом мире, и умела выполнять команды, которые отдавал на естественном языке человек. При этом лексика никак не была ограничена, то есть человек говорить что угодно, а программа могла достаточно свободно отвечать. Вот пример работы SHRDLU:
Человек: Что лежит в коробке?
Компьютер: Синяя пирамидка и синий блок.
Человек: На чем лежит пирамидка?
Компьютер: На коробке.
Человек: Как много блоков находится не в коробке?
Компьютер: Четыре.
Человек: Хотя бы один из них более тонкий, чем тот, про который я тебе говорил? На чем-то он стоит?
Компьютер: Да, стоит на столе.
Человек: Может ли стол собирать блоки?
Компьютер: Нет.
Человек: Может ли пирамидка стоять на блоке?
Компьютер: Да.
Человек: Может ли пирамидка стоять на пирамидке?
Компьютер: Не знаю.
Человек: Хорошо. Поставь пирамидку одну на другую.
Компьютер: Не получается.
Человек: Поставь, пожалуйста, два красных блока друг на друга. Либо зеленый куб, либо пирамидку. Сможешь?» И SHRDLU берет эти блоки, начинает ими оперировать.
Даже сейчас такого рода демонстрация выглядит впечатляющей. Интересно, что исходники SHRDLU можно скачать, программа написана на LISP, есть даже какой-то современный визуализатор под Windows. Если вы откроете ее исходники, то вы увидите, что программа состоит из огромного количества хитроумных правил.
Когда читаешь эти правила, то понимаешь, насколько изощренная логика заложена в программу. Терри Виноград, по всей видимости, проводил много экспериментов, давая возможность разным людям общаться с этой системой. Мирок SHRDLU очень маленький: он может быть описан примерно 50 разными словами. И в рамках такого маленького пространства можно создать впечатление интеллектуального поведения у системы.
Однажды Тьюринга приперли к стене и прямо спросили: «Когда программы пройдут тесты?». Тьюринг предположил, что в 2000 году появятся машины, использующие 109 бит памяти, способные обманывать человека в 30% случаев.
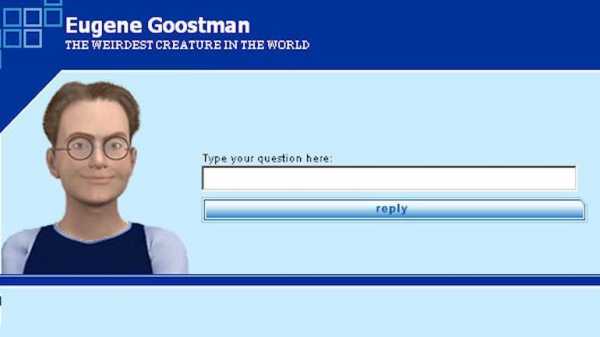
Интересно проверить, сбылся ли прогноз Тьюринга в 2016 году. Программа «Eugene Goostman» изображает из себя мальчика из Одессы. В первом тесте, состоявшемся в 2012 году, программа смогла обмануть судей в 20,2% случаев. В 2014 году в тесте эта же программа, уже модернизированная, в тестах, организованных Университетом Рединга, смогла обмануть судей в 33% случаев. Грубо говоря, с ошибкой плюс-минус 10 лет Тьюринг примерно попал в прогноз.
Потом появилась программа «Соня Гусева», и она в 2015 году смогла обмануть судей в 47% случаев. Стоит отметить, что процедура тестирования предполагает ограничение времени общения экспертов с программой (обычно около 5 минут), и в свете данного ограничения результаты уже не выглядят столь однозначными. Однако для решения многих практических задач, скажем, в области автоматизации SMM, этого более чем достаточно. Отличить продвинутого рекламного бота от человека на практике, скорее всего, не сможет большинство пользователей социальных сетей.
Наверное, самым известным и серьезным возражением на эти успехи является ответ философа Джона Сёрля, который предложил умственный эксперимент, названный «Китайская комната». Представим себе, что есть закрытая комната, в ней сидит человек. Мы знаем, что человек не понимает китайского языка, не сможет прочитать то, что написано китайскими иероглифами на бумаге. Но у нашего подопытного есть книга с правилами, в которой записано следующее: «Если у тебя на входе такие-то иероглифы, то ты должен взять вот такие иероглифы, и составить их в таком порядке». Он открывает эту книгу, она написана на английском, смотрит, что ему подали на вход, а дальше в соответствии с этими правилами формирует ответ, и скидывает его на выход. В определенной ситуации может показаться, что внутри комнаты находится человек, на самом деле понимающай китайский язык. Но ведь индивид внутри комнаты не знает китайского языка по постановке задачи. Получается, что когда эксперимент поставлен по канонам Тьюринга, он, на самом деле, не свидетельствует о том, что внутри сидит некто, понимающий китайский язык. Вокруг этого аргумента развернулась большая полемика. На него есть типовые возражения. Например, аргумент, что если сам Джон не понимает китайский язык, то вся система в целом, составленная из Джона и набора правил, уже обладает этим самым пониманием. До сих пор пишутся статьи в научной прессе на эту тему. Однако бо́льшая часть специалистов по computer science считают, что эксперимент Тьюринга достаточен для того, чтобы сделать определенные выводы.

От машин, которые лишь притворяются ИИ, перейдем к программам, реально превосходящим возможности человека. Одна из задач, напрямую связанная с созданием ИИ — это задача автоматизированного перевода. В принципе, автоматизированный перевод появился задолго до появления первых электронных машин. Уже в 1920-е годы были построены первые механические машины, основанные на фототехнике и причудливой электромеханике, которые были предназначены для ускорения поиска слов в словарях.
Мысль использовать ЭВМ для перевода была высказана в 1946 году, сразу после появления первых подобных машин. Первая публичная демонстрация машинного перевода (так называемый Джорджтаунский эксперимент) состоялась в 1954 году. Первый серьезный заход с серьезными деньгами под решение этой задачи был осуществлен в начале 1960-х годов, когда в США были созданы системы, предназначенные для перевода с русского языка на английский. Это были программы MARK и GAT. И в 1966 году был опубликован интересный документ, посвященный оценке существующих технологий машинного перевода и перспектив. Содержание этого документа можно свести к следующему: всё очень-очень-очень плохо. Но, тем не менее, бросать не надо, надо продолжать гранит грызть.
В Советском Союзе тоже были такие исследования, например группа «Статистика речи», возглавляемая Раймундом Пиотровским. Сотрудниками его лаборатории была основана известная фирма ПРОМТ, разработавшая первую отечественную коммерческую программу машинного перевода, базирующуюся в том числе на идеях Пиотровского. Еще где-то к 1989 году была выведена оценка, что система автоматизированного перевода позволяет примерно в 8 раз ускорить работу переводчика. Сейчас эти показатели, наверное, еще немножко улучшились. Конечно, сравниться с переводчиком ни одна система не может, но многократно ускорить его работу в состоянии. И с каждым годом показатель влияния на работу переводчиков растет.
Самой важной вехой, случившейся за последние десятилетия, стал приход на сцену систем, делающих упор на чисто статистические методы. Еще в 1960—1970 годы было понятно, что подходы, основанные на составлении ручных семантических карт языка и синтаксических структур, по всей видимости, ведут в тупик, поскольку масштаб работы невероятно велик. Как считалось, невозможно в принципе поспеть за изменяющимся живым языком.
Сорок лет назад лингвисты имели дело с достаточно маленькими языковыми корпусами. Лингвисты могли либо вручную обрабатывать данные — взять и посчитать количество таких-то слов в «Войне и мире», составить частотные таблицы, проделать первичный статистический анализ, но трудозатраты на выполнение таких операций были колоссальны. И здесь ситуация кардинально изменилась ровно тогда, когда появился Интернет, потому что вместе с Интернетом появилось огромное количество корпусов на естественных языках. Возник вопрос, как бы так сделать систему, которая в идеале не будет знать про язык ничего или почти ничего, но при этом будет на вход получать гигантские корпуса? Анализируя эти корпуса, система автоматически будет достаточно хорошо переводить тексты с одного языка на другой. Этот подход реализован, например, в Google Translate, то есть это система, за работой которой стоит очень мало работы лингвистов. Пока что качество перевода у систем предыдущего поколения — LEC, Babylon, PROMT — выше, чем у Google Translate.
Здесь проблема упирается в то, какой нам нужен препроцессинг для естественного языка, чтобы результаты можно было бы загнать в хорошие предиктивные модели типа сверточных нейронных сетей, и на выходе получить то, что нам нужно. Как препроцессинг должен быть построен, какие специфические знания о естественном языке должны в нем быть, чтобы решить дальнейшую задачу обучения системы?

Вспомним историю «сосиски в тесте» (sausage in the father-in-law). То есть существует сосиска в тесте, но «в тесте» означает не тесто, а тестя. ИИ должен понимать целый ряд человеческих культурных особенностей. Он должен понимать, что, скорее всего, в этом контексте предполагается практика обволакивания тестом при приготовлении сосисок, а не практика помещения сосисок в тестя. Это не значит, что вторая практика не существует. Может быть, в каком-то контексте адекватным переводом будет как раз вставить сосиску в тестя. И здесь только пониманием этих самых cultural references, которые присутствуют в естественном языке на каждом шаге, можно добиться успешного перевода. Либо, может быть, это какая-то статистика, связанная с тем, что на основе статистического анализа корпусов мы просто видим, что в текстах такой тематики чаще всего используется перевод про «сосиску, помещенную в тесто».
Другой пример связан с котом, который родил трех котят: двух белых, одного афроамериканца. Опять же, какой огромный культурный пласт выплывает здесь под переводом. На самом деле, то, что сюда попал афроамериканец — это некий заход в сторону понимания культурных особенностей современного общества. Пока эти проблемы решаются разными костылями типа задания тематики текста. То есть мы можем сказать, что переводим текст по алгебре. И тогда программа должна понимать, что «Lie algebra» — это «Алгебра Ли», а не «алгебра Лжи». Так или иначе, это может работать, но в универсальном плане нам пока очень далеко до системы, которая будет действительно сравнима по качеству с человеком-переводчиком.
В последние годы в сферу машинного перевода активно приходят нейросетевые технологии. Специфическая топология рекуррентных нейронных сетей — так называемая долгосрочно-краковременная архитектура (LSTM — Long short-term memory), применяемая для анализа высказываний, оказалась хорошо применимой для решения задач перевода. Современные тесты показывают, что применение LSTM-сетей позволяет с небольшими трудозатратами достичь качества перевода сопоставимого с уровнем качества конвенциональных технологий.
Еще одна забавная задачка — это сочинение стихов. Если посмотреть на чисто техническую сторону вопроса, как зарифмовать слова и положить их в определенный стихотворный размер, то эта задача была очень простой еще в 1970-е годы, когда Пиотровский начинал ею заниматься. У нас есть словарь слов с ударениями, есть ритмические карты стихотворных размеров — взяли и положили слова в этот размер. Но тут хотелось бы писать что-то осмысленное. В качестве первой мушки-дрозофилы была взята поэзия скальдов, поскольку в ней существует очень простой и четко формулируемый канон.
Гудрун из мести
Гор деве вместе
Хар был умелый
Хамдир был смелый
Сынов убила.
С Ньердом не мило.
Конесмиритель.
Копьегубитель.
— Торд сын Сьярека, перевод С.В. Петрова
Стихотворение скальдов состоит из так называемых кеннингов, и каждый кеннинг — это просто сочетание нескольких слов, имеющее абсолютно четкую эмоционально-смысловую окраску. Все стихотворение составляется из последовательности кеннингов. Задача для программы, сочиняющей стихи, может быть сформулирована таким образом: напиши ругательное стихотворение о вороне. Соответственно, программа по этим критериям из своей библиотеки кеннингов выбирает подходящие, а затем складывает из них стихотворение. Этот эксперимент похож на эксперимент Терри Винограда с SHRDLU, потому что здесь тоже очень простое модельное пространство, и в нем примитивные подходы могут работать, помогая получать неплохие результаты.

Это машинный корчеватель. Сейчас мы объясним, зачем он тут нужен. Программа SCIgen генерирует наукоподобный бред. Вообще, она это делает на английском языке, но тут можно сделать комбо — взять программу-переводчик и наукоподобный бред с правильными словарями перевести на русский язык. Получится уже бред второго порядка.
К чему мы ведем? Есть такая проблема: обязательное требование для человека, собирающегося защищать диссертацию, иметь несколько публикаций по тематике своей диссертации в журналах из списка Высшей аттестационной комиссии (ВАК). Соответственно, вокруг этого требования развернулся определенный поточный бизнес, а именно появились журналы, принимающие что угодно к публикации. Формально в ВАКовском журнале должен быть рецензент, который должен прочитать ваш текст, и сказать «да, мы принимаем к публикации эту статью» или «нет, не принимаем». Если рецензент говорит «мы принимаем», то вам условно говорят «вы платите суму денег X, и мы вашу статью публикуем». Давно уже у ученых закралось подозрение, что не всегда присутствует человек в процессе оценки.
Известный биоинформатик Михаил Гельфанд при помощи SCIgen сгенерировал наукоподобный бред, перевел его с помощью программы на русский язык, и разослал в целый ряд ваковских изданий статью, которая называлась «Корчеватель: алгоритм типичной унификации точек доступа и избыточности». Людям, которые занимаются алгоритмами или корчевателями, более-менее понятно, что это нечто очень странное, но оказалось, что в России нашелся как минимум один ВАКовский журнал, который принял эту статью к публикации.

В 2013 году Дариус Казими запустил проект «Национальный месяц создания романов», в рамках которого программа генерировала текст. Было использовано некоторое количество чат-ботов, которые были помещены в некое условное модельное пространство, где они взаимодействовали. В 2016 году разработчики из японского университета Хакодате написали программу, которая написала роман «День, когда компьютер пишет роман». Работа вышла в финал японского литературного конкурса и обогнала 1450 других произведений, написанных людьми. Совсем недавно стартовал проект, в рамках которого программа прочтет 2865 романов на английском языке и затем попробует написать свой собственный роман. По идее, к концу 2016 года у нас будет какая-то обратная связь про этот проект. Или не будет, если всё закончится ничем.
Есть и другие задачи. Например, достаточно рутинная задача, связанная с написанием информационных текстов для коммерческого сектора. Грубо говоря, для какого-нибудь сайта компании вы пишете рассказ о том, какая это компания, чем занимается. Или вы пишете новости путем рерайта. И есть инструменты, помогающие человеку провести анализ того, что он написал (например сайт Главред.ру, осуществляющий поиск недостатков в текстах, написанных в информационном стиле).
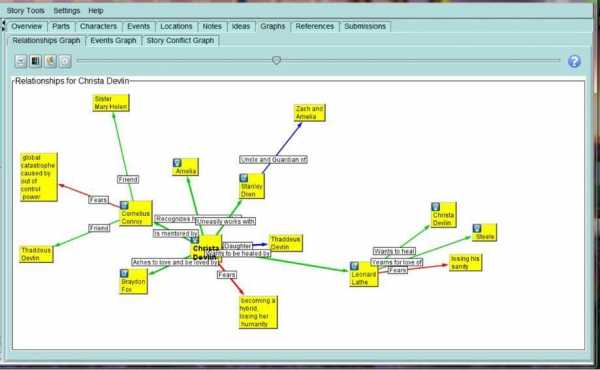
Есть инструменты, которые сейчас активно используются писателями. Помимо анализа орфографии, синтаксиса, стилистики текста, они помогают работать над сюжетом. Писатель может расписывать, что и где происходит в сюжете, иметь карту событий в романе, хранить отношения между героями, трансформирующиеся определенным образом во времени.
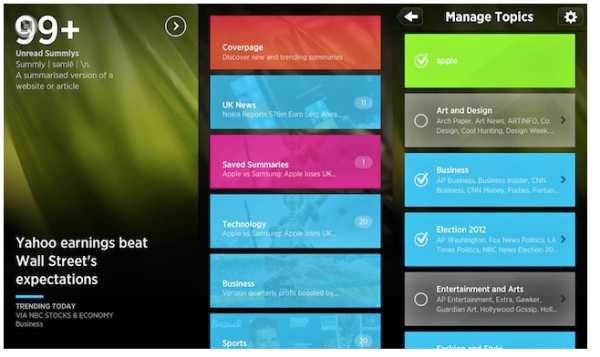
А вот приложение Summly, которое позволяет любую длинную статью ужать до нескольких предложений. Summly читает за вас новости, отжимает из них воду, делает из них такое summary, содержащее максимум 400 слов, и вы читаете уже «выжимку». Это нужно тем, кто хочет читать много новостей, но не хочет читать «воду». Интересно, что эту систему разработал простой английский школьник, который затем продал её за 30 млн долларов Yahoo.
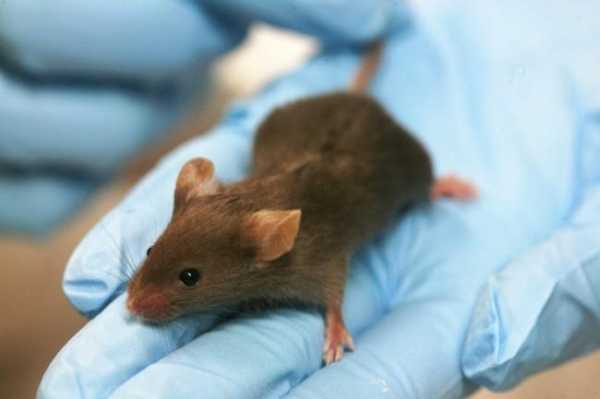
Большой сегмент научной деятельности называется Civil Science, то есть это гражданская наука, когда не ученых, а обычных людей привлекают к решению различных научных задач. В этом сегменте большой проект сделал Массачусетский технологический институт.
Жил-был мышонок Гарольд. Его, как водится у ученых, убили, мозг заморозили, нарезали тонкими микронными слоями, засунули эти срезы в сканирующий электронный микроскоп, и получили кучу сканов этих срезов. Сканов этих было так много, что всему научному коллективу, который работает над этим проектом, чтобы расшифровать структуру одной только зрительной коры мышонка, нужно было бы потратить примерно 200 лет. Поэтому ученые из Массачусетского технологического придумали следующий коварный план. Они сделали онлайн-игру, в которой раздают пользователям случайным образом эти самые срезы, и дают задание пользователям срезы по определенным правилам раскрашивать. У вас есть цветные маркеры, и вы с их помощью раскрашиваете свой срез. Если вы сделали это правильно, то вам дают много очков, а если вы сделали неправильно, то очков мало. Вы можете мериться количеством очков с другими участниками этой игры. Почти также увлекательно, как ловить покемонов, но гораздо полезнее.
Ученые из Массачусетского технологического — не простые ребята. На самом деле, у них есть нейронная сеть, в которую дальше пихают все обработанные игроками картинки, там делается свертка, нейронная сеть обучается, и дальше получается нейронная сеть, которая сама, используя срезы, восстанавливает трехмерную структуру синоптических связей.
Эти нейробиологические исследования имеют большое прикладное значение. Те самые сверточные нейронные сети, которые сейчас активно используются в обработке изображений, например в Prisma, были построены на результатах изучения зрительной коры.

Знаменитый футуролог Рэй Курцвейл раньше говорил, что универсальный искусственный интеллект будет создан в 2045 году, а сейчас он сбросил оценку до 2029 года.
В начале этого года случилась маленькая сенсация. Нейробиологи нашли вторичный контур связи между нейронами через астроциты глиальной ткани. Даже команда проекта компьютерного моделирования неокортекса человека Blue Brain заявила, что в новой модели, которую они собираются презентовать, уже включен этот контур. У них по таймлайну к 2022 году нужно показать модель мозга человека. Они считают, что мозг человека — это примерный эквивалент 1000 мозгов крыс. Возможно, в этом году нас ожидает ещё одно важное открытие в этой области — группа исследователей из Университета Калгари и Университета Алберты (Канада) предположили, что в мозге могут существовать и фотонные связи. Оптические сигналы могут распространяться через миелиновые оболочки. Соответствующее исследование опубликовано на биологическом сервере препринтов BioRXiv.
Везде, где мы используем нейронные сети, мы сталкиваемся с ограниченным числом вычислительных ядер в машине. Если бы число вычислительных ядер было примерно равно числу синапсов, мы бы достигли максимальной производительности за счет распараллеливания. Но ядер маловато. Поэтому сейчас в разных задачах, связанных с нейропроцессингом, где мы пытаемся скопировать то решение, которое предложила природа, идет поиск в направлении создания либо специализированного железа (нейроморфические процессоры), либо использования каких-то устройств, которые лучше подходят для эмуляции нейронных сетей. Например, Microsoft в прошлом году опубликовала статью, посвящённую использованию FPGA как раз для моделирования нейронной сети. Существующие нейросетевые фреймворки, например CNTK, TensorFlow, Caffe, способы использовать для нейросетевых вычислений процессоры видеокарт.
Другой известный проект TrueNorth, создаваемый IBM в рамках государственной программы DARPA SyNapse, остается пока единичным процессором для военных и стоит несколько миллионов долларов. При этом IBM создала целый институт, который разработал специальный язык программирования для этой железки. В открытом доступе результаты этой работы мы, скорее всего, увидим только через N лет. Именно поэтому про TrueNorth в научных новостях говорят, а какого-то движения в community вокруг него нет.
Альтернативным образом развивается направление прямого улучшения мозга. Например, была создана радиоуправляемая крыса. Есть истории, когда берут тележку, к ней подключают мозг крысы, и эта тележка катается по лабиринту. Более того, подобные проекты есть и с мозгом приматов. А это очень интересно, ведь обезьяны типа бонобо или шимпанзе демонстрируют уровень развития интеллекта, сопоставимый с уровнем трехлетнего ребенка.
В связи с успехами в области искусственного интеллекта, возникает вопрос: что же будет дальше, куда мы идем как вид и как технологическая цивилизация? С этим связана одна интересная история, уходящая в истоки человеческой эволюции: наш интеллект это не более чем продукт эволюционного компромисса. Неограниченное увеличение объёма мозга и его сложности невозможно. Во-первых, мозг потребляет очень много энергии, около 20% от общего потребления, хотя его собственная масса около 2% от массы тела. Кроме того, чем больше голова, тем сложнее роды у обезьян. Смертность, травмы при родах сильно возрастают с увеличением головы. Сейчас же, если мы создаем искусственную копию мозга, то мы в известной мере свободны от этих ограничений. Мы можем заведомо обеспечить такой мозг бо́льшим количеством энергии, можем построить бо́льшую нейронную сеть. Такая система по уровню своего интеллектуального развития будет обходить человека по всем направлениям. Мы уже затрагивали тему, к чему в итоге может привести развитие ИИ, но стоит коснуться еще одного варианта развития событий. Вариант на самом деле очень старый и в фантастических произведениях не раз уже появлялся.
В романе Герберта Франке «Клетка для орхидей» земляне используют систему типа «аватар» и с ее помощью исследуют далекую звездную систему. Они оказываются на планете, где находят руины древней цивилизации. На окраинах давно покинутого города они видят, грубо говоря, уровень технологий а-ля наш XX век. Дальше они продвигаются к центру, периметр города сокращается, все более высокие технологии попадаются им. Они приближаются к самому ядру города, и встречаются наконец-то с машинами, которые говорят: «Слушайте, ребята, дальше всё, нельзя пройти. Наши создатели там живут, им хорошо, вы их можете потревожить. Идите отсюда». Люди всё же как-то пробиваются, где-то уговорами, где-то силой. И что они видят? Они видят гигантские чаны, в которых плавают дальние-дальние потомки создателей этих машин, у которых к тому моменту мозг атрофировался, остались одни центры удовольствия, в которые внедрены электроды, по которым ритмически проходят электрические импульсы. Потомки некогда великой цивилизации живут в абсолютном счастье, расслабленности, гармонии с собой и с природой.
Вместо заключения коснемся темы отставания от Запада в направлении исследований ИИ. На самом деле наука сейчас носит во многом интернациональный характер. Просто наши хорошие исследователи, нейрофизиологи, специалисты по computer science публикуются в международной прессе и мало публикуются в прессе российской. Вообще говоря, зачастую публикация в российском журнале с точки зрения научной репутации зачисляется не в «плюс», а в «минус» учёному, потому что обычно это означает, что результаты работы «не дотянули» до уровня стандартов международных научных изданий. Но это не значит, что никаких интересных проектов у нас нет. Например, в России было проведено значимое исследование с reverse engineering нервной системы червя. Плюс есть комьюнити, которое абсолютно интернационально, в него входят энтузиасты, которые обсуждают алгоритмы, делают opensource-проекты. А о некоторых крупных проектах еще только предстоит рассказать. До встречи в следующем посте!
habr.com
12 полезных AI-сервисов, на которые стоит обратить внимание
О том, что технологии искусственного интеллекта сегодня являются темой номер один в IT-индустрии, можно судить не только по восторженным публикациям в СМИ и многочисленным проектам в этой сфере, но и по масштабам проникновения AI практически по все области современной жизни — от медицины, экспертных систем и научных исследований до промышленной робототехники и автопилотируемого транспорта. Направление машинного обучения и нейронных сетей активно развивается и совершенствуется, в нём задействованы Intel, AMD, NVIDIA, IBM, Google, Facebook, «Яндекс», ABBYY, а также тысячи других компаний-разработчиков по всему миру. Не скрывают своего интереса к искусственному интеллекту и различные инвестиционные фонды. Всё это заставляет с оптимизмом смотреть на будущее рынка умных AI-решений, которому аналитики прочат почти 30-кратный рост в ближайшее десятилетие. Впечатляющий показатель! Неудивительно, что сегодняшний обзор мы посвятили именно продуктам, использующим «электронный разум».

Remove.bg. Бесплатный AI-сервис, позволяющий за считаные секунды удалить фон на фотографиях без использования графических редакторов. Достаточно загрузить изображение — и система автоматически, с использованием алгоритмов искусственного интеллекта выделит объекты на переднем плане и уберёт всё лишнее. По заверениям разработчиков, лучше всего Remove.bg справляется со снимками людей, что, впрочем, не мешает использовать сервис для обработки фото с различными предметами — иногда результат получается очень даже неплохим. К загрузке принимаются картинки любого размера, однако итоговый вариант изображения (файл формата PNG с прозрачным фоном) ограничен разрешением 500 на 500 пикселей.

«Яндекс.Алиса». Голосовой помощник, который вряд ли нужно представлять широкой публике и который в полной мере демонстрирует возможности современных технологий машинного обучения и систем искусственного интеллекта на базе нейронных сетей. По набору функций «Алиса» действительно способна дать фору многим другим AI-проектам: она отлично владеет русским языком, умеет давать быстрые ответы на вопросы и прокладывать маршруты, рассказывать сказки детям, вызывать такси, совершать покупки в интернет-магазинах, играть в различные игры, разбираться в музыке, распознавать фотографии, а также выполнять прочие действия. Отличительными особенностями «Алисы» являются умение общаться на отвлечённые темы и возможность встраивания голосового помощника в различные сервисы.

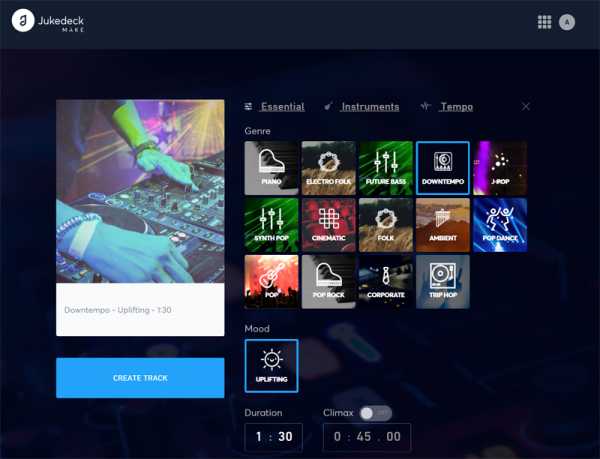
Jukedeck. Сервис, использующий всю мощь AI-технологий для создания музыкальных треков различных жанров. Всё, что требуется от пользователя, — это определить начальные параметры будущей композиции (жанр, темп, настроение, длительность, состав инструментов), после чего щёлкнуть по клавише Create Track и дождаться завершения обработки запроса. Сочинённую искусственным интеллектом музыку можно прослушать в браузере, скачать на компьютер либо отправить на доработку, откорректировав характеристики трека. Примечательно, что созданные Jukedeck произведения не требуют авторских отчислений и их можно использовать по своему усмотрению — например, для звукового сопровождения видеороликов на YouTube, публикации в социальных сетях, пополнения фонотеки или музыкального творчества.
Google AutoDraw. Сервис, превращающий рисунки от руки в высококачественные клип-арты. Положенный в основу AutoDraw искусственный интеллект в реальном времени анализирует пользовательские наброски, распознаёт их и предлагает аналогичные картинки, нарисованные профессиональными художниками. Созданные иллюстрации можно разместить в социальных сетях либо скачать на компьютер для дальнейшего использования. Важно отметить, что разработанный компанией Google сервис прекрасно подходит не только для развлечения, но и для решения вполне реальных задач. Например, добрую службу AutoDraw может сослужить дизайнерам-оформителям презентаций, иллюстраторам, фоторедакторам и представителям прочих творческих профессий.
Deepart.io. Ещё один AI-сервис, предназначенный для работы с графикой и создания оригинальных картин на основе пользовательских изображений. Техника работы с Deepart.io предельно простая: загружаем на сервер сервиса фотографию, указываем предпочтительный художественный стиль и дожидаемся завершения процесса отрисовки картины, который может занять продолжительное время. Для тех, кто не желает ждать, разработчики сервиса предлагают несколько вариантов платных подписок, позволяющих не только свести к минимуму время рендеринга шедевров цифрового искусства, но и снять ограничения на размер выходных изображений.
Beautiful.ai. Онлайновый инструмент для создания презентаций, использующий технологии искусственного интеллекта с целью автоматизации и упрощения работы пользователя со слайдами. «Умные» алгоритмы сервиса контролируют каждый шаг при работе с презентацией и делают так, чтобы просмотр слайдов был более комфортным. Beautiful.ai анализирует расположение элементов презентации и автоматически перестраивает слайды, корректирует их цветовое оформление, перерисовывает графики, подбирает анимационные переходы, рекомендует подходящие по тематике контента шаблоны и выполняет прочие действия, стараясь, чтобы подача материала на слайдах была профессиональной с точки зрения дизайна. Beautiful.ai имеет собственную библиотеку шаблонов и изображений, поддерживает совместную работу над документами, позволяет сохранять созданные презентации в облачном хранилище и экспортировать их в файлы форматов PDF и PowerPoint. В общем, рекомендуем.

Let’s Enhance. Сервис, который позволяет улучшать фотографии и масштабировать их без потери качества. «Сердцем» данного программного решения является обученная на большой базе снимков нейронная сеть, которая благодаря знаниям типичных объектов и текстур умеет восстанавливать детали и сохранять чёткие линии и контуры обрабатываемых изображений. Let’s Enhance может не только увеличивать разрешение фотографии в четыре раза, но и удалять шумы и артефакты сжатия на снимках формата JPEG, а также дорисовывать недостающие мелкие детали, делая картинку, как заверяют разработчики, максимально реалистичной. Для рядовых пользователей в системе установлено ограничение в 15 мегапикселей и 15 мегабайт для каждого загружаемого файла. Оформившим платную подписку на услуги сервиса предлагается максимальный приоритет в обработке изображений и возможность загружать картинки с разрешением до 30 мегапикселей.

DeepCode. Сканер программного кода, «электронный разум» которого умеет находить ошибки и предоставлять разработчикам рекомендации по их исправлению. В основу сервиса положены знания более чем четверти миллиона алгоритмических правил, принципов и методов разработки ПО, оперируя которыми искусственный интеллект системы может проверять и оценивать качество кода. DeepCode поддерживает работу с JavaScript, Java, Python и широко востребованным в профессиональной среде репозиторием GitHub.
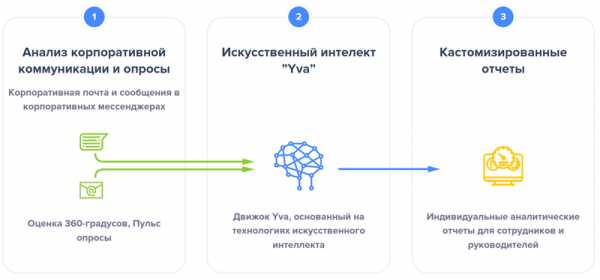
Yva. Облачная система «умной» аналитики корпоративных коммуникаций, позволяющая с помощью технологий искусственного интеллекта оценивать эффективность работы персонала компании. Yva подключается к корпоративной почте, мессенджерам, проводит регулярные опросы сотрудников и анализирует полученные данные. В результате система формирует рекомендации и предупреждения каждому сотруднику и руководителю, позволяя контролировать их работу, предотвращать «выгорание» и увольнение ключевых работников и другие возможные риски. Система также позволяет на ранних этапах предотвращать конфликты в коллективе и узнавать компетенции каждого сотрудника, будь то его сильные и слабые стороны, лидерские качества, вовлечённость в работу и прочие характеристики. Сильной стороной Yva является независимость от предметной области и умение автоматически адаптироваться к коммуникационной среде организаций самых разных отраслей и любого размера. Более подробно о том, как работает эта система, можно узнать в нашем обзоре продукта.
Colorize. Сервис, использующий технологии искусственного интеллекта для раскрашивания чёрно-белых фотографий. Работа с Colorize реализована по принципу «проще не бывает»: загружаем снимок или указываем ссылку на изображение в глобальной сети — и на выходе, спустя несколько минут, получаем цветное фото. Справедливости ради стоит отметить, что с раскрашиванием изображений AI-движок сервиса справляется не всегда идеально, но иногда результаты получаются действительно впечатляющими.
CaptionBot. Онлайновый сервис компании Microsoft, который распознает объекты на загружаемых пользователем изображениях и с помощью нейронных сетей описывает то, что находится на фото, причём простыми человеческими словами. Особенностью CaptionBot является использование сразу двух систем искусственного интеллекта — Computer Vision (компьютерное зрение) и Natural Language Processing (анализ и синтез естественных языков). И этот тандем действительно работает!
Ну а завершает наш обзор разработанный компанией Mail.Ru Group сервис аудиоаналитики Sounds. Положенные в его основу AI-технологии позволяют распознавать голоса, отдельные звуки и их комбинации в аудиопотоке, различать громкость, тональность и интенсивность звучания, выполнять преобразование речи в текст и решать прочие задачи. Благодаря широким функциональным возможностям Sounds может использоваться во множестве сценариев. К примеру, сервис может найти применение для распознавания выстрелов и драк на улицах и последующего оповещения полиции, охраны помещений, акустического наблюдения за неисправностями в работе промышленного оборудования, очистки аудиозаписей от шумов, идентификации людей по голосам, оценки тональности речи и её конвертирования в текст, а также для скрытия нецензурной лексики в радио- и телепередачах в прямом эфире. Для интеграции системы в программные продукты предусмотрен соответствующий API.
Есть что добавить? Пишите в форме для комментариев ниже.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
3dnews.ru
5 лучших приложений искусственного интеллекта для вашего телефона Android
В последнее время Samsung предоставляет услуги голосовой связи на основе искусственного интеллекта, которые его клиенты могут использовать во всех устройствах и продуктах Samsung, от смартфонов до телевизоров до стиральных машин.
Samsung является ведущим мировым производителем смартфонов на базе бесплатного программного обеспечения для Android от Google. Одним из основных флагманских устройств Samsung в этом году стал смартфон Galaxy S8, который оснастили искусственным интеллектом (ИИ). Об этом представители компании и приобретенного ею стартапа Viv объявили на пресс-конференции в Сеуле.
В этом обзоре мы рассмотрим некоторые приложения для телефонов Android, которые представляют собой искусственный интеллект (ИИ).
Использование искусственного интеллекта растет. Искусственный интеллект может сделать нашу жизнь лучше и легче. Вот список лучших приложений для искусственного интеллекта, которые вы можете использовать на своем смартфоне Android.
Мы все знаем, что использование искусственного интеллекта растет. ИИ может сделать нашу жизнь лучше и легче. В настоящее время традиционное использование ИИ покоится в голографических интеллектуальных приложениях, которые пытаются действовать в качестве помощника на мобильных телефонах.
Виртуальный помощник может выполнять несколько задач, которые могут сэкономить ваше драгоценное время, например, получить котировки, отправка сообщений, составления расписания, написания электронной почты и т. д. Здесь мы собираемся поделиться списком лучших AI-приложений, которые вы можете использовать на своем смартфоне Android.
Robin – голосовой помощник с ИИ
Робин — ваш голосовой помощник на дороге, прочитает вам текстовые сообщения, местную информацию, навигацию по GPS и даже шутки. Кроме того, у нее больше индивидуальности, чем у других продуктов для обработки голоса, помощников, чатов или ботов. Робин дает вашему смартфону более умный характер.
Google Allo
Google Allo — это приложение для смарт-сообщений, которое помогает вам больше говорить и делать больше. Лучшая часть этого приложения — это легко поможет вам в решении ваших задач. Это приложение не только отвечает на ваши запросы, оно может даже шутить.

Cortana – голосовой ассистент с ИИ
Cortana — известное приложение среди всех пользователей Windows. Приложение, которое ранее было доступно на Windows Phone, теперь доступно на Android. Вы можете использовать Cortana для отправки электронных писем, поиска нужных продуктов в Интернете.
HOUND — голосовой поиск и помощник
Hound — лучший способ поиска по вашему голосу. Самый быстрый и простой способ получить информацию, развлечения и услуги связи, которые вы хотите, Hound построен для вашей занятой жизни, позволяя вам получить то, что вам нужно, и двигаться дальше. Это приложение похоже на голосовой поиск Google.
Recent News
Recent — это приложение для смарт-новостей, которое предоставляет ваши новости. Оно основано на искусственном интеллекте, который изучает ваши интересы, предлагает соответствующие статьи и предлагает темы, которые вы, возможно, захотите прочитать. Это быстрый и лучший способ оставаться в курсе тем, которые вы любите.
Как мы уже говорили, искусственный интеллект — это умный и эффективный способ сэкономить ваше драгоценное время и поможет вам быть продуктивным на всем пути. Эти приложения помогут вам изучить потенциал искусственного интеллекта.
Так что ты думаешь об этом? Поделитесь своими взглядами в поле комментариев ниже.
искусственные нейронные сети искусственный интеллект
neuronus.com
Всё, что вам нужно знать об ИИ — за несколько минут / Habr

Приветствую читателей Хабра. Вашему вниманию предлагается перевод статьи «Everything you need to know about AI — in under 8 minutes.». Содержание направлено на людей, не знакомых со сферой ИИ и желающих получить о ней общее представление, чтобы затем, возможно, углубиться в какую-либо конкретную его отрасль.
Знать понемногу обо всё иногда (по крайней мере, для новичков, пытающихся сориентироваться в популярных технических направлениях) бывает полезнее, чем знать много о чём-то одном.
Многие люди думают, что немного знакомы с ИИ. Но эта область настолько молода и растёт так быстро, что прорывы совершаются чуть ли не каждый день. В этой научной области предстоит открыть настолько многое, что специалисты из других областей могут быстро влиться в исследования ИИ и достичь значимых результатов.
Эта статья — как раз для них. Я поставил себе целью создать короткий справочный материал, который позволит технически образованным людям быстро разобраться с терминологией и средствами, используемыми для разработки ИИ. Я надеюсь, что этот материал окажется полезным большинству интересующихся ИИ людей, не являющихся специалистами в этой области.
Введение
Искусственный интеллект (ИИ), машинное обучение и нейронные сети — термины, используемые для описания мощных технологий, базирующихся на машинном обучении, способных решить множество задач из реального мира.
В то время, как размышление, принятие решений и т.п. сравнительно со способностями человеческого мозга у машин далеки от идеала (не идеальны они, разумеется, и у людей), в недавнее время было сделано несколько важных открытий в области технологий ИИ и связанных с ними алгоритмов. Важную роль играет увеличивающееся количество доступных для обучения ИИ больших выборок разнообразных данных.
Область ИИ пересекается со многими другими областями, включая математику, статистику, теорию вероятностей, физику, обработку сигналов, машинное обучение, компьютерное зрение, психологию, лингвистику и науку о мозге. Вопросы, связанные с социальной ответственностью и этикой создания ИИ притягивают интересующихся людей, занимающихся философией.
Мотивация развития технологий ИИ состоит в том, что задачи, зависящие от множества переменных факторов, требуют очень сложных решений, которые трудны к пониманию и сложно алгоритмизируются вручную.
Растут надежды корпораций, исследователей и обычных людей на машинное обучение для получения решений задач, не требующих от человека описания конкретных алгоритмов. Много внимания уделяется подходу «чёрного ящика». Программирование алгоритмов, используемых для моделирования и решения задач, связанных с большими объёмами данных, занимает у разработчиков очень много времени. Даже когда нам удаётся написать код, обрабатывающий большое количество разнообразных данных, он зачастую получается очень громоздким, трудноподдерживаемым и тяжело тестируемым (из-за необходимости даже для тестов использовать большое количество данных).
Современные технологии машинного обучения и ИИ вкупе с правильно подобранными и подготовленными «тренировочными» данными для систем могут позволить нам научить компьютеры «программировать» за нас.

Обзор
Интеллект — способность воспринимать информацию и сохранять её в качестве знания для построения адаптивного поведения в среде или контексте
Это определение интеллекта из (англоязычной) Википедии может быть применено как к органическому мозгу, так и к машине. Наличие интеллекта не предполагает наличие сознания. Это — распространённое заблуждение, принесённое в мир писателями научной фантастики.
Попробуйте поискать в интернете примеры ИИ — и вы наверняка получите хотя бы одну ссылку на IBM Watson, использующий алгоритм машинного обучения, ставший знаменитым после победы на телевикторине под названием «Jeopardy» в 2011 г. С тех пор алгоритм претерпел некоторые изменения и был использован в качестве шаблона для множества различных коммерческих приложений. Apple, Amazon и Google активно работают над созданием аналогичных систем в наших домах и карманах.
Обработка естественного языка и распознавание речи стали первыми примерами коммерческого использования машинного обучения. Вслед за ними появились задачи другие задачи автоматизации распознавания (текст, аудио, изображения, видео, лица и т.д.). Круг приложений этих технологий постоянно растёт и включает в себя беспилотные средства передвижения, медицинскую диагностику, компьютерные игры, поисковые движки, спам-фильтры, борьбу с преступностью, маркетинг, управление роботами, компьютерное зрение, перевозки, распознавание музыки и многое другое.
ИИ настолько плотно вошёл в современные используемые нами технологии, что многие даже не думают о нём как об «ИИ», то есть, не отделяют его от обычных компьютерных технологий. Спросите любого прохожего, есть ли искусственный интеллект в его смартфоне, и он, вероятно, ответит: «Нет». Но алгоритмы ИИ находятся повсюду: от предугадывания введённого текста до автоматического фокуса камеры. Многие считают, что ИИ должен появиться в будущем. Но он появился некоторое время назад и уже находится здесь.
Термин «ИИ» является довольно обобщённым. В фокусе большинства исследований сейчас находится более узкое поле нейронных сетей и глубокого обучения.
Как работает наш мозг
Человеческий мозг представляет собой сложный углеродный компьютер, выполняющий, по приблизительным оценкам, миллиард миллиардов операций в секунду (1000 петафлопс), потребляющий при этом 20 Ватт энергии. Китайский суперкомпьютер под названием «Tianhe-2» (самый быстрый в мире на момент написания статьи) выполняет 33860 триллионов операций в секунду (33.86 петафлопс) и потребляющий при этом 17600000 Ватт (17.6 Мегаватт). Нам предстоит проделать определённое количество работы перед тем, как наши кремниевые компьютеры смогут сравниться со сформировавшимися в результате эволюции углеродными.
Точное описание механизма, применяемого нашим мозгом для того, чтобы «думать» является предметом дискуссий и дальнейших исследований (лично мне нравится теория о том, что работа мозга связана с квантовыми эффектами, но это — тема для отдельной статьи). Однако, механизм работы частей мозга обычно моделируется с помощью концепции нейронов и нейронных сетей. Предполагается, что мозг содержит примерно 100 миллиардов нейронов.
Нейроны взаимодействуют друг с другом с помощью специальных каналов, позволяющих им обмениваться информацией. Сигналы отдельных нейронов взвешиваются и комбинируются друг с другом перед тем, как активировать другие нейроны. Эта обработка передаваемых сообщений, комбинирование и активация других нейронов повторяется в различных слоях мозга. Учитывая то, что в нашем мозгу находится 100 миллиардов нейронов, совокупность взвешенных комбинаций этих сигналов устроена довольно сложно. И это ещё мягко сказано.
Но на этом всё не заканчивается. Каждый нейрон применяет функцию, или преобразование, к взвешенным входным сигналам перед тем, как проверить, достигнут ли порог его активации. Преобразование входного сигнала может быть линейным или нелинейным.
Изначально входные сигналы приходят из разнообразных источников: наших органов чувств, средств внутреннего отслеживания функционирования организма (уровня кислорода в крови, содержимого желудка и т.д.) и других. Один нейрон может получать сотни тысяч входных сигналов перед принятием решения о том, как следует реагировать.
Мышление (или обработка информации) и полученные в результате его инструкции, передаваемые нашим мышцам и другим органам являются результатом преобразования и передачи входных сигналов между нейронами из различных слоёв нейронной сети. Но нейронные сети в мозгу могут меняться и обновляться, включая изменения алгоритма взвешивания сигналов, передаваемых между нейронами. Это связано с обучением и накоплением опыта.
Эта модель человеческого мозга использовалась в качестве шаблона для воспроизведения возможностей мозга в компьютерной симуляции — искуственной нейронной сети.
Искусственные Нейронные Сети (ИНС)
Искусственные Нейронные Сети — это математические модели, созданные по аналогии с биологическими нейронными сетями. ИНС способны моделировать и обрабатывать нелинейные отношения между входными и выходными сигналами. Адаптивное взвешивание сигналов между искусственными нейронами достигается благодаря обучающемуся алгоритму, считывающему наблюдаемые данные и пытающемуся улучшить результаты их обработки.

Для улучшения работы ИНС применяются различные техники оптимизации. Оптимизация считается успешной, если ИНС может решать поставленную задачу за время, не превышающее установленные рамки (временные рамки, разумеется, варьируются от задачи к задаче).
ИНС моделируется с использованием нескольких слоёв нейронов. Структура этих слоёв называется архитектурой модели. Нейроны представляют собой отдельные вычислительные единицы, способные получать входные данные и применять к ним некоторую математическую функцию для определения того, стоит ли передавать эти данные дальше.
В простой трёхслойной модели первый слой является слоем ввода, за ним следует скрытый слой, а за ним — слой вывода. Каждый слой содержит не менее одного нейрона.
С усложнением структуры модели посредством увеличения количества слоёв и нейронов возрастают потенциал решения задач ИНС. Однако, если модель оказывается слишком «большой» для заданной задачи, её бывает невозможно оптимизировать до нужного уровня. Это явление называется переобучением (overfitting).
Архитектура, настройка и выбор алгоритмов обработки данных являются основными составляющими построения ИНС. Все эти компоненты определяют производительность и эффективность работы модели.
Модели часто характеризуются так называемой функцией активации. Она используется для преобразования взвешенных входных данных нейрона в его выходные данные (если нейрон решает передавать данные дальше, это называется его активацией). Существует множество различных преобразований, которые могут быть использованы в качестве функций активации.
ИНС являются мощным средством решения задач. Однако, хотя математическая модель небольшого количества нейронов довольно проста, модель нейронной сети при увеличении количества составляющих её частей становится довольно запутанно. Из-за этого использование ИНС иногда называют подходом «чёрного ящика». Выбор ИНС для решения задачи должен быть тщательно обдуманным, так как во многих случаях полученное итоговое решение нельзя будет разобрать на части и проанализировать, почему оно стало именно таким.

Глубокое обучение
Термин глубокое обучение используется для описания нейронных сетей и используемых в них алгоритмах, принимающих «сырые» данные (из которых требуется извлечь некоторую полезную информацию). Эти данные обрабатываются, проходя через слои нейросети, для получения нужных выходных данных.
Обучение без учителя (unsupervised learning) — область, в которой методики глубокого обучения отлично себя показывают. Правильно настроенная ИНС способна автоматически определить основные черты входных данных (будь то текст, изображения или другие данные) и получить полезный результат их обработки. Без глубокого обучения поиск важной информации зачастую ложится на плечи программиста, разрабатывающего систему их обработки. Модель глубокого обучения же самостоятельно способна найти способ обработки данных, позволяющий извлекать из них полезную информацию. Когда система проходит обучение (то есть, находит тот самый способ извлекать из входных данных полезную информацию), требования к вычислительной мощности, памяти и энергии для поддержания работы модели сокращаются.
Проще говоря, алгоритмы обучения позволяют с помощью специально подготовленных данных «натренировать» программу выполнять конкретную задачу.
Глубокое обучение применяется для решения широкого круга задач и считается одной из инновационных ИИ-технологий. Существуют также другие виды обучения, такие как обучение с учителем (supervised learning) и обучение с частичным привлечением учителя(semi-supervised learning), которые отличаются введением дополнительного контроля человека за промежуточными результатами обучения нейронной сети обработке данных (помогающего определить, в правильном ли направлении движется система).
Теневое обучение (shadow learning) — термин, используемый для описания упрощённой формы глубокого обучения, при которой поиск ключевых особенностей данных предваряется их обработкой человеком и внесением в систему специфических для сферы, к которой относятся эти данные, сведений. Такие модели бывают более «прозрачными» (в смысле получения результатов) и высокопроизводительными за счёт увеличения времени, вложенного в проектирование системы.
Заключение
ИИ является мощным средством обработки данных и может находить решения сложных задач быстрее, чем традиционные алгоритмы, написанные программистами. ИНС и методики глубокого обучения могут помочь решить ряд разнообразных проблем. Минус состоит в том, что самые оптимизированные модели часто работают как «чёрные ящики», не давая возможности изучить причины выбора ими того или иного решения. Этот факт может привести к этическим проблемам, связанным с прозрачностью информации.
habr.com
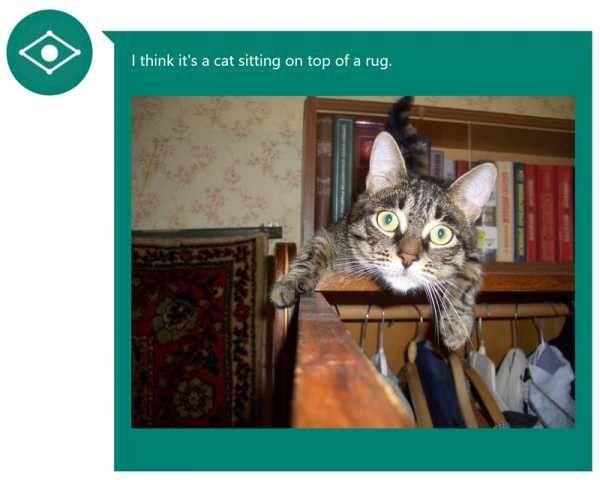
Создаётся новая программа искусственного интеллекта Viv на замену Siri

Когда в 2011 году вышла новая модель «айфона», многие были поражены необычной функцией под названием Siri. Точнее будет сказать, по имени Сири, ведь программу искусственного интеллекта оснастили женской личностью. «Умная помощница» понимала человеческий голос и выполняла команды, например, «Сири, набери номер жены» или «Сири, поставь будильник на 6-30». Она могла неординарно ответить на некоторые вопросы вроде «Сири, существует ли Бог?». Для того времени это была весьма необычным. Однако, вскоре стали понятны ограничения технологии. Сири выполняла лишь самые простые команды, а в остальном была только голосовым «расширением» к интернет-поисковику, направляя запрос туда.
После смерти Стива Джобса разработчики Siri организовали новую фирму Viv Labs, которая работает над гораздо более продвинутой версией «умного помощника» по имени Вив.
В программу Viv внедряют систему самообучения и генерации программного кода на лету. В результате, должен получиться ИИ совершенно нового типа. Отвечая с центрального сервера на вопросы миллионов пользователей, постепенно сформируется некий «глобальный мозг», который поймёт любую предметную область и жаргон, свяжет любые понятия и выявит смысл любого вопроса. И, естественно, наиболее адекватно ответит на него.
Viv работает следующим образом. Получив запрос вроде «По дороге домой к брату хочу купить дешёвое вино, подходящее для лазаньи», она парсит его на части и составляет уникальную программу, которая использует разные источники информации из интернета, в том числе карту местности, базу данных магазинов, кулинарный справочник и базу цен на вина. Всё делается очень быстро, и в течение 0,05 секунды Viv выдаёт список подходящих винных лавок по дороге к брату и названия нужных вин.
Более подробно разбор этого запроса показан на схеме.
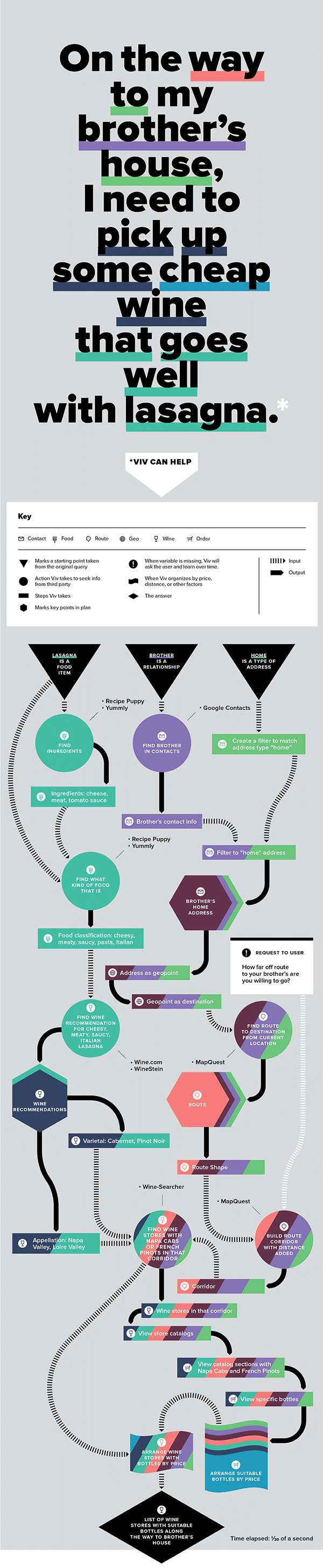
Главные принципы, которыми руководствуются разработчики: Viv должна тренироваться самостоятельно, отвечая на вопросы пользователей и должна делать это непрерывно, умнея с каждым днём. Чем больше людей общаются с «цифровым помощником» — тем быстрее растёт её база знаний. Поэтому разработчики не хотят отдавать движок какой-нибудь одной компании, а хотят лицензировать его всем желающим, чтобы доступ к ИИ был с каждого телевизора и каждого мобильного телефона.
Задача адекватного парсинга и понимания человеческого языка, конечно, сложная. Но над её решением работает не только Viv Labs. Например, недавно компания Google купила pf $500 млн фирму DeepMind, работающую примерно в той же области. Есть ещё суперкомпьютер IBM Watson и другие подобные проекты. В общем, Искусственный интеллект с постоянным самообучением может оказаться ближе, чем нам кажется.
xakep.ru
Создание искусственного интеллекта / Habr
Пока программисты могут зарабатывать программированием, то существующие ИИ это не ИИ, какой бы фантик на них не был бы навешен. Предлагаемый мной вариант может решить этот вопрос.В результате своих изысканий я перестал для себя использовать фразу «искусственный интеллект» как слишком неопределенную и пришел к другой формулировке: алгоритм самостоятельного обучения, исследования и применения найденных результатов для решения любых возможных к реализации задач.
Что такое ИИ, об этом уже много было написано. Я ставлю вопрос по другому, не «что такое ИИ», а «зачем нужен ИИ». Мне он нужен, что бы заработать много денег, затем что бы компьютер выполнял за меня все, что я сам не хочу делать, после построить космический корабль и улететь к звездам.
Вот и буду здесь описывать, как заставить компьютер выполнять наши желания. Если вы ожидаете здесь увидеть описание или упоминание, как работает сознание, что такое самосознание, что значит думать или рассуждать — то это не сюда. Думать — это не про компьютеры. Компьютеры рассчитывают, вычисляют и выполняют программы. Вот и подумаем, как сделать программу, способную рассчитать необходимую последовательность действий для реализации наших желаний.
В каком виде в компьютер попадет наша задача — через клавиатуру, через микрофон, или с датчиков вживленных в мозг — это не важно, это дело вторичное. Если мы сможем компьютер заставить выполнять желания написанные текстом, то после мы можем поставить ему задачу, что бы он сделал программу, которая так же выполняет желания, но через микрофон. Анализ изображений так же лишний.
Утверждать, что для того, что бы создаваемый ИИ мог распознавать изображения и звук, в него изначально должны быть включены такие алгоритмы, это все равно что утверждать, что всякий человек, который таковые создал, от рождения знали как работают такие программы.
Сформулируем аксиомы:
1. Все в мире можно посчитать по каким-нибудь правилам. (про погрешности позже)
2. Расчет по правилу, это однозначная зависимость результата от исходных данных.
3. Любые однозначные зависимости можно находить статистически.
А теперь утверждения:
4. Существует функция преобразования текстовых описаний в правила — что бы не нужно было искать уже давно найденные знания.
5. Существует функция преобразования задач в решения (это исполнялка наших желаний).
6. Правило прогнозирования произвольных данных включает в себя все остальные правила и функции.
Переведем это на язык программиста:
1. Все в мире можно посчитать по каким-нибудь алгоритмам.
2. Алгоритм всегда при повторении исходных данных дает одинаковый результат.
3. При наличии множества примеров исходных данных и к ним результатов, при бесконечном времени поиска можно найти все множество возможных алгоритмов, реализующих эту зависимость исходных данных и результата.
4. Существует алгоритмы конвертации текстовых описаний в алгоритмы (или любых других информационных данных) — чтобы не искать потребные алгоритмы статистически, если их уже кто-то когда-то нашел и описал.
5. Можно создать программу, которая будет исполнять наши желания, будь они в текстовом или голосовом виде, при условии, что эти желания реализуемы физически и в потребные рамки времени.
6. Если умудриться создать программу, которая умеет прогнозировать и учиться прогнозированию по мере поступления новых данных, то по истечении бесконечного времени такая программа будет включать все возможные в нашем мире алгоритмы. Ну а при не бесконечном времени для практической пользы и с некоторой погрешностью ее можно заставить выполнять алгоритмы программы п.5 или любые другие.
И еще, ИМХО:
7. Другого способа полностью самостоятельного и независимого от человека обучения, кроме как поиска перебором правил и статистической проверки их на прогнозировании, не существует. И нужно только научиться использовать это свойство. Это свойство является частью работы мозга.
Что нужно прогнозировать. В человеческий мозг от рождения начинает поступать поток информации — от глаз, ушей, тактильные и пр. И все решения принимаются им на основании ранее поступивших данных. По аналогии, делаем программу, у которой есть вход новой информации по одному байту — входной побайтовый поток. Все что поступило ранее, представляется в виде одного сплошного списка. От 0 до 255 будет поступать внешняя информация, и свыше 255 будем использовать как специальные управляющие маркеры. Т.е. вход позволяет записать скажем до 0xFFFF размерность числа. И именно этот поток, а точнее очередное добавляемое число информации и нужно научиться прогнозировать, на основании поступавших до этого данных. Т.е. программа должна пытаться угадать, какое будет добавлено следующее число.
Конечно возможны и другие варианты представления данных, но для целей, когда на вход поступают самые различные форматы, попросту туда по началу запихиваем различные html с описаниями, этот наиболее оптимальный. Хотя маркеры можно заменить на эскейп последовательности в целях оптимизации, но объяснять с ними менее удобно. (А так же, представим, что все в ASCII, а не UTF).
Итак, сначала как и при рождении, пихаем туда все подряд интернет-страницы с описаниями и разделяем их маркером нового текста — <NewPage> — что бы этот черный ящик учился всему подряд. Маркеры я буду обозначать тегами, но подразумевается, что они просто какое-то уникальное число. По прошествии некоторого объема данных, начинаем манипулировать входящей информацией с помощью управляющих маркеров.
Под прогнозированием я понимаю такой алгоритм, который знает не только какие закономерности уже были, но и ищет постоянно новые. И потому если на вход такой программе послать последовательность
<BEG>небо<ANS>синие<END>
<BEG>трава<ANS>зеленная<END>
<BEG>потолок<ANS>…
, то он должен сообразить, что за маркером <ANS> следует цвет от указанного ранее объекта, и на месте многоточия спрогнозирует наиболее вероятный цвет потолка.
Мы ему несколько примеров повторили, что бы он понял которую функцию нужно применить в пределах этих тегов. А сам цвет, он конечно же не выдумать должен, а должен его уже знать самостоятельно изучив вычисляя закономерности на прогнозировании.
Когда от алгоритма требуется ответ, то на вход последующих шагов подается то, что было прогнозом предыдущего шага. Типа автопрогнозирование (по аналогии со словом автокорреляция). И при этом отключаем функцию поиска новых последовательностей.
Другой пример, можно после первого маркера указывать вопрос, а во втором ответ, и тогда будь этот алгоритм супер-мега-крутым, он должен начать давать ответы даже на самые сложные вопросы. Опять же, в пределах уже изученных фактов.
Можно много придумать разных трюков с управляющими маркерами, поданными на вход прогнозирующего механизма, и получать любые желаемые функции. Если вам будет скучно читать про алгоритмическое обоснование этого свойства, то можно пролистать до следующих примеров с управляющими маркерами.
Из чего состоит этот черный ящик. Во первых стоит упомянуть, что стопроцентного прогнозирования всегда и во всех ситуациях сделать не возможно. С другой стороны, если как результат всегда выдавать число ноль, то это то же будет прогнозом. Хоть и с абсолютно стопроцентной погрешностью. А теперь посчитаем, с какой вероятностью, за каким числом, какое дальше следует число. Для каждого числа определится наиболее вероятное следующее. Т.е. мы его сможем немножко спрогнозировать. Это первый шаг очень длинного пути.
Однозначное отображение исходных данных на результат по алгоритму, это соответствует математическому определению слова функция, за исключением того, что к определению алгоритма не налагается определенность в количестве и размещении входных и выходных данных. Так же пример, пусть будет маленькая табличка: объект-цвет, в нее занесем множество строк: небо-синее, трава-зеленная, потолок-белый. Это получилась маленькая локальная функция однозначного отображения. И не важно, что в действительности не редко цвета не такие — там будут другие свои таблицы. И любая база данных, содержащая запомненные свойства чего-либо, является множеством функций, и отображает идентификаторы объектов на их свойства.
Для упрощения, дальше во многих ситуациях, вместо термина алгоритм, я буду употреблять термин функция, типа однопараметрическая, если другого не указано. И всякие такие упоминания, нужно в голове подразумевать расширяемость до алгоритмов.
И описание буду давать примерное, т.к. в реальности реализовать все это я пока… Но оно все логично. А так же следует учитывать, что все расчеты ведутся коэффициентами, а не истина или ложь. (возможно даже если явно указано что истина и ложь).
Любой алгоритм, в особенности который оперирует целыми числами, может быть разложен на множество условий и переходов между ними. Операции сложения, умножения, и пр. так же раскладываются на подалгоритмики из условий и переходов. И еще оператор результата. Это не оператор возврата. Оператор условия берет откуда-то значение и сравнивает его с константным. А оператор результата складывает куда-нибудь константное значение. Расположение взятия или складывания вычисляется относительно либо базовой точки, либо относительно прежних шагов алгоритма.
struct t_node {
int type; // 0 - условие, 1 - результат
union {
struct { // оператор условия
t_node* source_get;
t_value* compare_value;
t_node* next_if_then;
t_node* next_if_else;
};
struct { // оператор результата
t_node* dest_set;
t_value* result_value;
};
}
};
На вскидку, что то вроде этого. И из таких элементов и строится алгоритм. В результате всех рассуждений получится более сложная структура, а эта для начального представления.
Каждая прогнозируемая точка рассчитывается по какой-то функции. К функции прилагается условие, которое тестирует на применимость этой функции к этой точке. Общая сцепка возвращает, либо ложь — не применимость, либо результат расчета функции. А непрерывное прогнозирование потока, это поочередная проверка применимости всех уже придуманных функции и их расчет, если истина. И так для каждой точки.
Кроме условия на применимость, есть еще дистанции. Между исходными данными, и результатными, и эта дистанция бывает различной, при одной и той же функции, применяемой в зависимости от условия. (И от условия до исходной или прогнозируемой то же есть дистанция, ее будем подразумевать, но опускать при объяснениях. И дистанции бывают динамическими).
При накоплении большого числа функций, будет возрастать количество условий, тестирующих применимость этих функций. Но, эти условия во многих случаях возможно располагать в виде деревьев, и отсечение множеств функций будет происходить пропорционально логарифмической зависимости.
Когда идет начальное создание и замер функции, то вместо оператора результата, идет накопление распределения фактических результатов. После накопления статистики, распределение заменяем на наиболее вероятный результат, и функцию предваряем условием, так же протестировав условие на максимальность вероятности результата.
Это идет поиск одиночных фактов корреляции. Накопив кучу таких одиночных, пытаемся объединить их в группы. Смотрим, из которых можно выделить общее условие и общую дистанцию от исходного значения к результату. А так же, проверяем, что при таких условиях и дистанциях, в других случаях, где идет повторение исходного значения, не идет широкое распределение результатного. Т.е. в известных частых употреблениях, оно высокотождественно.
Коэффициент тождественности. (Здесь двунаправленная тождественность. Но чаще она однонаправленная. Позже переобдумаю формулу.)
Количество каждой пары XY в квадрат и суммируем.
Делим на: сумма количеств в квадрате каждого значения X плюс сумма количеств в квадрате Y минус делимое.
Т.е. SUM(XY^2) / (SUM(X^2) + SUM(Y^2) — SUM(XY^2)).
Этот коэффициент от 0 до 1.
И в результате, что происходит. Мы на высокочастотных фактах убедились, что при этих условии и дистанции, эти факты однозначны. А остальные редковстречаемые — но суммарно таких будет гораздо больше чем частых — имеют ту же погрешность, что и частовстреченные факты в этих условиях. Т.е. мы можем накапливать базу прогнозирования на единично встречаемых фактах в этих условиях.
Да будет база знаний. Небо часто синее, а тропическая-редкая-фигня где-то увидели что она серо-буро-малиновая. И запомнили, т.к. правило мы проверили — оно надежное. И принцип не зависит от языка, будь то китайский или инопланетный. А позже, после понимания правил переводов, можно будет сообразить, что одна функция может собираться из разных языков. При этом нужно учесть, что базу знаний так же можно представить в виде алгоритмов — если исходное значение такое-то, то результатное такое-то.
Дальше, мы в следствии перебора других правил, находим, что при других расположении и условии, возникает уже виденная тождественность. Причем теперь нам не обязательно набирать большую базу для подтверждения тождественности, достаточно набрать десяток единичных фактов, и увидеть, что в пределах этого десятка, отображение происходит в те же значения, как и у прежней функции. Т.е. та же функция используется в других условиях. Это свойство образует то, что мы в описании разными выражениями можем описывать одно и то же свойство. А порой их просто перечислять в таблицах на интернет-страницах. И дальше, сбор фактов по этой функции можно производить уже по нескольким вариантам использования.
Происходит накопление возможных различных условий и расположений относительно функций, и на них так же можно пытаться находить закономерности. Не редко, правила выборки подобны для различных функций, отличаясь только каким-нибудь признаком (например слово идентифицирующее свойство или заголовок в таблице).
В общем понаходили мы кучку однопараметрических функций. А теперь, как при образовании из одиночных фактов в однопараметрические, так же и здесь, попытаемся сгруппировать однопараметрические по части условия и части дистанции. Та часть, что общая — новое условие, а та, что различается — это второй параметр новой функции — двухпараметрической, где первым параметром будет параметр однопараметрической.
Получается, что каждый новый параметр у многопараметрических находится с той же линейностью, что и образование из единичных фактов в однопараметрические (ну или почти с той же). Т.е. нахождение N-параметрической пропорционально N. Что в стремлении к очень много параметрам становится почти нейронной сеткой. (Кто захочет, тот поймет.)
Конвертационные функции.
Конечно замечательно, когда нам предоставили множество корреспондирующих примеров, скажем маленьких текстов перевода с русского на английский. И можно начинать пытаться находить между ними закономерности. Но в действительности, оно все перемешано во входном потоке информации.
Вот мы взяли нашли одну какую-то функцию, и путь между данными. Вторую и третью. Теперь смотрим, можем ли среди них, у каких-либо найти у путей общую часть. Попытаться найти структуры X-P1-(P2)-P3-Y. А потом, найти еще другие подобные структуры, с подобными X-P1 и P3-Y, но различающимися P2. И тогда мы можем заключить, что имеем дело со сложной структурой, между которыми существуют зависимости. А множество найденных правил, за вычетом серединной части, объединим в групп и назовем конвертационной функцией. Таким образом образуются функции перевода, компиляции, и прочие сложные сущности.
Вот возьмите лист с русским текстом, и с его переводом на незнакомый язык. Без самоучителя чрезвычайно сложно из этих листов найти понимание правил перевода. Но это возможно. И примерно так же, как это делали бы вы, это нужно оформить в поисковый алгоритм.
Когда разберусь с простыми функциями, тогда и буду дальше обмусоливать конвертационный поиск, пока сойдет и набросок, и понимание что это то же возможно.
Кроме статистического поиска функций, еще можно их формировать из описаний, посредством конвертационной функции в правила — читающая функция. Статистику для изначального создания читающей функции можно в избытке найти в интернете в учебниках — корреляции между описаниями и правилами примененными к примерам в тех описаниях. Т.е. получается, что алгоритм поиска должен одинаково видеть и исходные данные, и правила примененные к ним, т.е. все должно располагаться в неком однородном по типам доступов графе данных. Из такого же принципа только обратном, могут находиться правила для обратной конвертации внутренних правил во внешние описания или внешние программы. А так же формировать понимание системы, что она знает, а чего нет — можно перед затребованием ответа, поинтересоваться, а знает ли система ответ — да или нет.
Функции о которых я говорил, на самом деле не просто находимый единый кусок алгоритма, а могут состоять из последовательности других функций. Что в свою очередь не вызов процедуры, а последовательность преобразований, типа как в linux работа с pipe. Для примера, я грубо описывал прогнозирование сразу слов и фраз. Но что бы получить прогноз только символа, к этой фразе нужно применить функцию взятия этого одного символа. Или функция научилась понимать задачи на английском, а ТЗ на русском. Тогда РусскоеТЗ->ПеревестиНаАнглийский->ВыполнитьТЗнаАнглийском->Результат.
Функции могут быть не фиксированными в определении, и доопределяться или переопределяться по мере поступления дополнительной информации или при вообще изменении условий — функция перевода не конечная, и к тому же может меняться со временем.
Так же на оценку вероятностей влияет повторяемость одного множества в разных функциях — образует или подтверждает типы.
Так же нужно упомянуть, что не мало множеств реального мира, а не интернет-страниц, являются упорядоченными и возможно непрерывными, или с прочими характеристиками множеств, что как-то то же улучшает расчеты вероятностей.
Кроме непосредственного замера найденного правила на примерах, предполагаю существование других способов оценки, что то типа классификатора правил. А возможно и классификатора этих классификаторов.
Еще нюансы. Прогнозирование состоит из двух уровней. Уровень найденных правил и уровень поиска новых правил. Но поиск новых правил по сути то же программа со своими критериями. И допускаю (хотя пока не продумывал), что может быть все проще. Что нужен нулевой уровень, который будет искать возможные алгоритмы поиска во всем их многообразии, которые уже в свою очередь будут создавать конечные правила. А может быть это вообще многоуровневая рекурсия или фрактал.
Вернемся к управляющим маркерам. В результате всех этих рассуждений про алгоритм получается, что через них мы запрашиваем от этого черного ящика продолжить последовательность, и выдать расчет по функции определяемой по подобию. Типа сделать так, как было показано до этого.
Есть другой способ определения функции в этом механизме — выдать функцию через определение. Например:
<QUERY>Перевести на английский<PARAM>стол<RES>table<END>
<QUERY>Ответить на вопрос<PARAM>цвет неба<RES>синий<END>
<QUERY>Создать программу по ТЗ<PARAM>хочу искусственный интеллект<RES>…
Использование этой системы для решения наших задач состоит в следующем алгоритме. Делаем описание определения специального идентификатора для описания задач. Потом, создаем описание задачи и присваиваем ей новый идентификатор. Делаем описание допустимых действий. К примеру (хоть и не практично) непосредственно команды процессора — описания из интернета, а к компьютеру подключены манипуляторы, которыми через порты можно управлять. И после, мы у системы можем спрашивать, какое нужно выполнить следующее действие, для приближения задачи к решению, ссылаясь на задачу по идентификатору. А так же через раз спрашивать, не нужно ли какой дополнительно информации необходимой для дальнейшего расчета действий — информации по общим знаниям или по текущему состоянию решения задачи. И зацикливаем запросы действий и запросы информации в какой-нибудь внешний цикл. Вся эта схема строится на текстовых определениях, и потому может быть запущена посредством функций получаемых по определению. А выход — только лишь команды — отпадает вопрос многовероятности текстов. Вопрос масштабов необходимого прогнозирования сейчас не обсуждается — если будет необходимый и достаточный функционал прогнозирования — по логике оно должно работать.
Если кто в ИИ видит не способ решения задач, а какие-либо характеристики человека, то можно сказать, что человеческое поведение и качества так же являются расчетными и прогнозируемыми. И в литературе есть достаточно описаний того или иного свойства. И потому, если в системе мы опишем, которое из свойств хотим, то она в меру знаний будет его эмулировать. И будет воспроизводить либо абстрактное усредненное поведение, либо со ссылкой на конкретную личность. Ну или если хотите, можно попробовать запустить сверхразум — если дадите этому определение.
Прогнозировать можно что-то, что происходит по истечению какого-то времени. Объекты движутся со скоростями и ускорениями, и всякие другие возможные изменения чего-либо со временем. Прогнозировать можно и пространство. Для примера, вы заходите в незнакомую комнату, в которой стоит стол, у которого один из углов накрыт листом бумаги. Вы это угол не видите, но мыслено можете спрогнозировать, что он вероятней всего такой же прямоугольный, как и другие углы (а не закругленный), и цвет этого угла такой же как и у других углов. Конечно, прогнозирование пространства происходит с погрешностями — вдруг тот угол стола обгрызенный, и на нем пятно краски. Но и прогнозирование временных процессов тоже всегда с погрешностями. Ускорение свободного падения на земле не всегда 9.81, а зависит от высоты над уровнем моря, и от рядом стоящих гор. И измерительные приборы вы никогда не сможете сделать абсолютно точными. Т.е. прогнозирование пространства и процессов во времени всегда происходит с погрешностями, и у различных прогнозируемых сущностей различные погрешности. Но суть одинакова — алгоритмы, находимые статистически.
Получается, что прогнозирование нашего байтового потока, это вроде прогнозирование пространства информации. В нем кодируются и пространство и время. Вот встречается там какая-то структура — пусть будет кусок программы. Этот кусок программы — это прогнозируемое пространство, такое же как и стол. Набор правил прогнозирования этой структуры образуют правила этой структуры — что-то вроде регулярных выражений. Для определения структуры этих структур вычисляется прогнозирование не одиночного значения, а множества допустимых значений. На момент описания алгоритма, про отдельность роли структур в нем я еще не осознавал, и потому туда это не попало. Но добавив это свойство, образуется полное понимание картинки, и со временем попробую переписать. Учтите, что под структурами подразумеваются условно расширяемые — если такое-то свойство имеет такое-то значение, значит добавляется еще пачка свойств.
В целом, все что возможно в нашем мире, описывается типами, структурами, конвертациями и процессами. И все эти свойства подчиняются правилам, которые находятся в результате прогнозирования. Мозг делает тоже самое, только не точными методами, т.к. он аналоговое устройство.
Процессы научных исследований, отличаются от прочих тем, что до этого найденного знания не было описано в литературе. И что найденному знанию даются идентификаторы названий и описания. Это нам, людям нужны эти идентификаторы и описания — для обмена между собой, а компьютер нашел себе новую закономерность, и моча использует эту запись в базе его знаний. Если конечно не нужно поделиться с другими компьютерами.
Будет ли он искать исследования целенаправленно без постановки такой задачи? Нет, потому что у него нету собственных желаний, а только поставленные задачи. То, что у нас отвечает за реализацию собственных желаний и интересов, это у нас называется личность. Можно и у компьютера запрограммировать личность. И будет ли она подобна человеческой, или какой-то компьютерный аналог — но это все равно останется всего лишь поставленной задачей.
А наша творческая деятельность в искусстве, это те же исследования, только ищутся сущности, затрагивающие наши эмоции, чувства и разум.
Окончательной инструкции по изготовлению такой программы пока нету. Вопросов остается много, и про сам алгоритм, и про использование (и про многовариантность текстов). Со временем буду дальше уточнять и детализировать описание.
Альтернативным направлением реализации прогнозирования является использование рекуррентных нейронных сетей (скажем сеть Элмана). В этом направлении не нужно задумываться о природе прогнозирования, но там множество своих трудностей и нюансов. Но если это направление реализовать, то остальное использование остается прежним.
Выводы по статье:
1. Прогнозирование является способом находить все возможные алгоритмы.
2. С помощью манипуляции входом прогнозирования можно эти алгоритмы от туда вытаскивать.
3. Это свойство можно использовать, что бы разговаривать с компьютером.
4. Это свойство можно использовать, что бы решать любые задачи.
5. ИИ будет тем, как вы его определите, и после определения его можно решить как задачу.
Некоторые скажут, что брутфорсом найти какую-либо закономерность будет чрезмерно долго. В противовес этому могу сказать, что ребенок учится говорить несколько лет. Сколько вариантов мы сможем просчитать за несколько лет? Найденные и готовые правила применяются быстро, и для компьютеров гораздо быстрей чем у человека. А вот поиск новых и там и там долго, но будет ли компьютер дольше человека, этого мы не узнаем, пока не сделаем такой алгоритм. Так же, замечу, что брутфорс великолепно распараллеливается, и найдутся миллионы энтузиастов, которые включат свои домашние ПК для этой цели. И получиться, что эти несколько лет, еще можно поделить на миллион. А найденные правила другими компьютерами будут изучаться моментально, в отличие от аналогичного процесса у человека.
Другие начнут утверждать, что в мозге биллионы клеток нацеленных на распараллеливание. Тогда вопрос, каким образом задействуются эти биллионы при попытке без учебника на примерах изучить иностранный язык? Человек будет долго сидеть над распечатками и выписывать коррелирующие слова. В то же время, один компьютер это будет пачками делать за доли секунды.
И анализ изображений — двинте десяток бильярдных шаров и посчитайте сколько будет столкновений. (закрывшись от звука). А два десятка или три… И причем здесь биллионы клеток?
В общем, быстродействие мозга и его многопараллельность — это очень спорный вопрос.
Когда вы думаете о создании думающего компьютера, вы копируете в него то, чему человек научился в течении жизни, и не пытаетесь понять, а каковы механизмы, позволяющие это накопить от стартовой программы — пожрать и поспать. И эти механизмы основываются отнюдь не на аксиомах формальной логики. Но на математике и статистике.
PS: проголосуйте в голосовалке. Задумайтесь, перечитайте и проголосуйте. Не будьте воздержавшимися. Если нужны более детальные ответы — обращайтесь.
PPS: мое мнение, что научного определения термина «Искусственный интеллект» не существует. Существует только научно-фантастическое. А если нужна реальность, то см. п.5 в выводах по статье.
PPPS: Я много разных интерпретаций понял гораздо позже уже после написания статьи. Скажем, что поиск зависимости вопрос-ответ является аппроксимацией. Или каковы более точные научные определения вытаскивания нужной функции из многообразия найденных в процессе поиска функций прогнозирования. На каждый маленький момент понимания нельзя написать отдельную статью, а на все в общем нельзя, потому что не объединить в один заголовок. И все эти понимания, дают ответ, как получать от компьютерных вычислительных мощностей ответы на задаваемые вопросы, ответы на которые не всегда можно прочитать в существующих описаниях, как скажем для проекта Watson. Как создать программу, которая по одному упоминанию, или движению пальца, пытается понять и сделать то, что от нее хотят.
Когда нибудь такая программа будет сделана. И назовут ее очередным гаджетом. А не ИИ.
****
Исходники по этой теме, а так же дальнейшее развитие представления можете найти на сайте http://www.create-ai.org
habr.com