 Бизнес-Блог Блоготей Бизнес-Блог «Блоготей» — информационный блог о бизнесе и финансах. Полезные статьи и новости из мира бизнеса, финансов, банков, экономики, инвестиций.
Бизнес-Блог Блоготей Бизнес-Блог «Блоготей» — информационный блог о бизнесе и финансах. Полезные статьи и новости из мира бизнеса, финансов, банков, экономики, инвестиций. 
Рейтинг самых популярных товаров на «Авито» в 2020 году
Коронакризис — так можно назвать ситуацию, с которой начался 2020 год, — заставил многих людей свернуть бизнес: Минтруда США сообщает, что период с 26 марта рабочих мест лишилось больше 6 миллионов человек. В России таких удручающих заявлений пока не делают, однако это еще не повод сидеть на месте ровно и отказываться от поиска запасных вариантов. На всякий случай советуем обратить внимание на C2C-сервисы: поняв, какие на том же «Авито» самые продаваемые товары и сыграв на этом, можно обеспечить себя финансовой подушкой. Разбираемся, что сейчас нужнее всего в России, и как на этом заработать.
Что чаще всего покупают в России
Издание «РБК» сообщает, что в марте-апреле 2020 года товарами вирусного спроса в розничной торговле стали гречневая крупа, сахар, рис, мука, туалетная бумага, мыло, влажные салфетки, мясные консервы и полуфабрикаты. Данные основаны на аудите компании Nielsen, проводящей независимые маркетинговые исследования.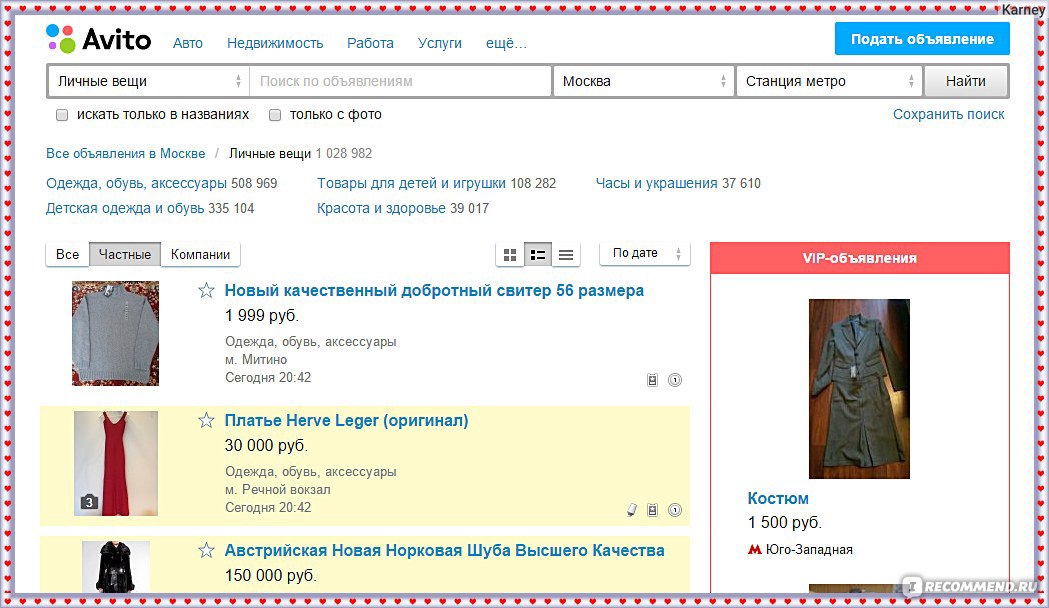
Как сейчас работают продавцы
Хотя шоурумы и магазины сейчас закрыты, фактически ретейлеры и покупатели перебрались онлайн — притом темпы работы возросли: в Центральном регионе — по сравнению с 2019 годом — примерно на 15%. Такой способ продажи позволяет ретейлеру оставаться на плаву, пользуясь для доставки товаров услугами курьеров, что, к слову, удобно для обеих сторон. Реализатор может не затрачивать средства на аренду помещения и оплату работы менеджеров, клиенту не приходится сталкиваться с социальной тревогой: он просто делает заказ, выбирает службу доставки — тот же привычный СДЭК и ждет. Возникают проблемы с посылкой — просто заказы отслеживает СДЭК через специальные сервисы — например, Posylka.
Как продавать на «Авито»
Ранее мы упомянули, что, хотя сейчас наблюдается повышенный спрос на определенные группы товаров, к ним лучше не прибегать, продавая их на «Авито»: издание Forbes сообщает, что сервис блокирует объявления, спекулирующие на коронавирусе. Сейчас к таким относятся только такие, где пользователи сбывают маски, курьерскую одежду или домашних животных для выгула, однако мы полагаем, что в дальнейшем список будет пополняться.
По состоянию на 2020 год найти рейтинг того, что хорошо продается на «Авито», проблематично — нет актуальных данных. Однако в октябре 2017 года агентство Data Insight вместе с «Авито» провела исследование «C2C в российском интернете. Интернет-торговля частными лицами», где представили примерный портрет покупателя, стратегию поведения продавца и желания клиента. Так, выяснилось, что типовой покупатель — женщина 23-34 лет со средним уровнем доходов. 80% ее покупок составляют Б/У вещи, к ним относятся.
— Обувь
— Детские коляски
— Велосипеды и другие спорттовары
— подержанные брендовые смартфоны
— услуги по вывозу мусора
— услуги ремонта
— аренда оборудования на время
— услуги по обслуживанию автотранспорта
Хотя возникает соблазн заработать на вирусных товарах, лучше обратить внимание на категории первой важности, которые останутся популярными даже после того, как спадет пик пандемии.
Как заработать на Авито: 5 реальных способов
Авито является крупнейшей площадкой частных объявлений в России. Ежеминутно на сайте совершается 100-120 сделок, поэтому нельзя упускать шанс создать здесь дополнительный источник дохода. Однако существует заблуждение, что для заработка в сети нужно вкладывать деньги. На Авито это необязательно: на сайте можно заниматься продажей своих и чужих товаров или выступать посредником, получая процент от сделки.
Перспективы заработка на Авито
Основу заработков на Авито составляют продажи. Продавцами выступают обычные люди, что вызывает доверие у покупателей. Помимо этого, преимуществами заработка на Авито являются:
Не нужно создавать площадку (сайт, группу в соцсетях и т.д.) для привлечения трафика;
Большая посещаемость сайта;
Необязательно привлекать платный трафик. Достаточно попадать в запрос целевого покупателя, чтобы успешно продать товар;
Ежеминутно заключают 100-120 сделок, что является хорошим показателем продаж;
Можно найти хорошую вещь по низкой стоимости, а затем перепродать ее, заработав на разнице цен.
Заработок на Авито помогает не только развить навыки продаж, но и обрести полезные контакты, которые могут пригодиться в будущем.
Алгоритм заработка на Авито
Следуя представленной ниже инструкции, любой желающий сможет уже через неделю или даже раньше получить первый доход на Авито.
1. Регистрация на сайте.
В этой процедуре нет ничего сложного: пользователю нужно ввести номер мобильного телефона, на который придет СМС с кодом активации, затем придумать логин и пароль.
2. Поиск товаров и анализ спроса.
Для первого заработка денег нужно поискать дома ненужные вещи. При этом они должны быть в удовлетворительном состоянии, иначе их не купят.
На Авито с высокой вероятностью можно продать товары из следующих категорий:
Бытовая техника;
Компьютеры и комплектующие;
Электроника;
Детские товары;
Автозапчасти;
Мебель;
Товары для пикника;
Строительные материалы;
Товары для творчества.
Искать товары на продажу также можно в группах, где участники предлагают отдать вещи даром или за символическую оплату (например, шоколадку).
Важный момент при продаже товара – оценка спроса на него. Чтобы проверить востребованность конкретной вещи, начинающий предприниматель может воспользоваться следующими способами:
Поискать объявления о продаже похожей вещи.
Создать пробное объявление. Звонки с вопросами о товаре станут лучшим ответом о востребованности продаваемой вещи.
3. Создание привлекательного объявления.
На Авито главный критерий, которым руководствуются покупатели, – информативность. Нужно максимально подробно описать товар, не ограничиваясь техническими характеристиками. Покупатель наверняка поинтересуется, в каком состоянии вещь, почему ее продают. Лучше сразу об этом написать. Также стоит указать номер телефона и электронную почту для связи.
В объявление обязательно нужно загрузить реальные фотографии товара, сделанные при хорошем освещении. Не рекомендуется брать картинки из интернета, поскольку это отталкивает покупателей.
4. Прием заявок и показ товара.
Чаще всего заинтересованные покупатели звонят по телефону, но не стоит забывать проверять электронную почту. При общении нужно быть вежливым, открытым, отвечать на все вопросы, тогда с высокой вероятностью товар купят.
Если человек хочет посмотреть товар детально, не нужно этому препятствовать. Можно отправить дополнительные фотографии, организовать конференцию в Скайпе или лично встретиться.
5. Получение оплаты и закрытие сделки.
Если покупатель из того же города, что и продавец, то сделку можно заключить при лично встрече. В противном случае, товар можно выслать через доставку Авито или Почту России.
Такова общая схема создания дополнительного дохода на Авито. Теперь нужно сказать о 5 способах, которые гарантировано принесут прибыль.
5 способов заработка на Авито без вложений
О первом уже было сказано. Он заключается в том, чтобы продавать ненужные вещи, скопившиеся дома. Цену на такие товары выставляют с учетом торга.
Второй способ – посредничество. Наверняка, у друзей и знакомых тоже есть вещи, которые они хотели бы продать, но времени заниматься этим нет. Можно предложить услуги посредника за процент от сделки.
Помимо этого, некоторые предприниматели зарабатывают деньги на продаже чужих услуг. Суть способа в том, чтобы договориться с потенциальным клиентом об услуге, получить от него контакты и отдать их специалисту. А уже сам специалист связывается с клиентом и начинает работу. Как и в случае с вещами, оплата здесь – процент от закрытой сделки.
Суть способа в том, чтобы договориться с потенциальным клиентом об услуге, получить от него контакты и отдать их специалисту. А уже сам специалист связывается с клиентом и начинает работу. Как и в случае с вещами, оплата здесь – процент от закрытой сделки.
Третий способ – заработок с помощью CPA-сетей. Они представляют собой каталоги разных товарных предложений. За продажу товара начисляется процент. Чтобы начать зарабатывать с помощью партнерок на Авито, нужно:
Зарегистрироваться в проверенной CPA-сети;
Найти товары, пользующиеся спросом на Авито;
Создать привлекательные объявления. Для контактов использовать электронную почту;
Дождаться письма от потенциального покупателя;
Скинуть партнерскую ссылку, расписать преимущества товара и выгоду от покупки;
Если потенциальный клиент купит товар по ссылке, то посредник получит процент от сделки.
Поищите в каталогах товары, которые пользуются максимальным спросом у людей с Авито.
Четвертый способ – создание комиссионного магазина. Это посредничество в более крупном масштабе. Можно договориться с магазинами о продаже товаров на Авито или организовать продажу вещей от обычных людей за определенный процент.
Это посредничество в более крупном масштабе. Можно договориться с магазинами о продаже товаров на Авито или организовать продажу вещей от обычных людей за определенный процент.
Пятый способ – дропшиппинг. Работа по это схеме включает в себя:
Поиск оптовых поставщиков;
Выбор товара на продажу;
Создание объявления. Цена должна содержать торговую наценку, покрывающую расходы на доставку и посредничество;
Прием заявок и получение предоплаты;
Заявки передаются выбранному поставщику. Оформляется и оплачивается заказ по оптовой стоимости. Разница между ценой на Авито и ценой поставщика – прибыль;
Убедиться, что покупатели получили свои товары.
Авито предлагает большие возможности для получения дополнительного дохода с помощью продаж. Выбрав один из указанных способов, любой желающий сможет в короткие сроки получить первую прибыль и развиваться дальше.
Как определить спрос на товар
Современный мир – это рынок. На каждом шагу продажи – услуги, товары. Даже устройство на работу – это продажа. Человек продает себя за зарплату, указанную в договоре. Но чтобы правильно и продуктивно продавать, нужно изучить спрос на конкретный товар или услугу. Это делается для понимания того, насколько товар или услуга востребована в данный момент.
На каждом шагу продажи – услуги, товары. Даже устройство на работу – это продажа. Человек продает себя за зарплату, указанную в договоре. Но чтобы правильно и продуктивно продавать, нужно изучить спрос на конкретный товар или услугу. Это делается для понимания того, насколько товар или услуга востребована в данный момент.
Как определить спрос на товар или услугу в интернете
Реализовать себя можно и через интернет, как и запустить бизнес. Но прежде чем начать продавать и вкладывать деньги, нужно понять, насколько актуально предложение. Если оно не пользуется спросом или это новинка рынка, то велики риски уйти в убыток. Поэтому каждый стартапер должен знать, как определить спрос на свой товар или услуги в сети.
Анализ спроса на продукт или услугу проводится для понимания того, будут ли продажи успешными. Делается это еще до запуска бизнеса, на стадии планирования и составления бизнес-плана. Изучение спроса поможет понять, насколько предложение востребовано, стоит ли увеличить затраты, отказаться от идеи, скорректировать что-то до запуска. Именно спрос и рождает бизнес. Без спроса не будет продаж, и значит вся история будет приносить только убытки. А во время запуска бизнеса немаловажно следить за тем, какие именно из услуг или товаров имеют спрос, и им уделять наибольшее внимание. Например, благодаря crm системе для учебных школ можно отслеживать, какие именно курсы имеют наибольший спрос и прибыль.
Именно спрос и рождает бизнес. Без спроса не будет продаж, и значит вся история будет приносить только убытки. А во время запуска бизнеса немаловажно следить за тем, какие именно из услуг или товаров имеют спрос, и им уделять наибольшее внимание. Например, благодаря crm системе для учебных школ можно отслеживать, какие именно курсы имеют наибольший спрос и прибыль.
Определение спроса складывается из нескольких этапов:
- Тщательное исследование рынка.
На этом этапе изучается спрос в целом на конкретный товар и его аналоги, предложения конкурентов, насколько занята ниша, средняя цена, которая позволит примерно посчитать как прибыль, так и убытки. Общая ситуация, сложившаяся на рынке, даст возможность узнать, какие идеи уже были воплощены, насколько успешно они продвигаются, стоит ли запускать что-либо похожее. Сделав подробный анализ, можно уже понять перспективы своего предложения и принять окончательное решение о том, стоит ли запускать его на рынок, или нужно пересмотреть продукт или услугу.
- Целевая аудитория
Не всегда обращают внимание начинающие бизнесмены на этот крайне важный момент. Кому будет интересно то, что он предлагает? И от этого уже понимать, где предлагать? Определенно глупо идти с автозапчастями на “мамские” форумы, как и с детскими игрушками — в сообщество байкеров. Необходимо собрать максимум сведений о будущих клиентах: возрастная группа, пол, какое у них образование, достаток потенциального клиента. Естественно, немалую роль играет и вид продаж. Будет это торговая точка или интернет-магазин. Опять же, нужно правильно соотнести свои амбиции и пожелания с тем, что есть на самом деле. Другими словами, тщательно проанализировать спрос и предложение, а также факторы, их определяющие. - Выяснение потребностей клиентов в форме опроса.
На этом этапе вся необходимая информация идет из первых рук. Выявляются первостепенные потребности и покупательская способность людей. Так бизнесмену, решившему зайти на рынок с экзотическими соусами, будет важна информация, какие вкусы покупателям интересны, какие сочетания они хотели бы попробовать, за какую цену они готовы купить данный продукт и как часто. Таким образом, это будет еще один способ понимания, стоит ли выходить на рынок с имеющимся предложением, или же стоит отказаться или доработать идею. Особенно такой этап важен для новинки рынка, на которую сложно изучить спрос без выхода «в поля». - Тестирование товара или услуги
Когда определены приоритеты и целевая аудитория, и уже сделаны первые закупки или созданы предложения, начинается тестовая реализация. Такой запуск проходит небольшими количествами. И уже по фактическому спросу определяется актуальность предложения на конкретном рынке. Если процесс продаж не идет, то стоит пересмотреть цену, аудиторию или само предложение. На данном этапе можно также определить коэффициент ценовой эластичности спроса, чтобы использовать в дальнейшем эти данные при формировании постоянных цен на товар.
 Таким образом, это будет еще один способ понимания, стоит ли выходить на рынок с имеющимся предложением, или же стоит отказаться или доработать идею. Особенно такой этап важен для новинки рынка, на которую сложно изучить спрос без выхода «в поля».
Таким образом, это будет еще один способ понимания, стоит ли выходить на рынок с имеющимся предложением, или же стоит отказаться или доработать идею. Особенно такой этап важен для новинки рынка, на которую сложно изучить спрос без выхода «в поля».При всех возможных расчетах и исследованиях невозможно точно сказать, как поведет себя рынок в данный момент. Прогнозы могут сбыться, а могут и дать ошибку. Но правильный подход позволит минимизировать потери и выбрать верную стратегию поведения и развития своего бизнеса.
Как определить спрос на товар в своем регионе
Чтобы выйти на рынок только в своем регионе, нужно провести всю ту же самую работу, но с ограничением по географии. Так можно выяснить не только спрос по области, но даже по району города. например, кофе с собой или фаст-фуд будут пользоваться спросом в студенческом городке, но вряд ли найдут такой же спрос среди заводов, где чаще всего свои столовые с низкими ценами.
Хочешь свое дело, приносящее прибыль? Получи бесплатную скайп консультацию по открытию интернет магазина
Исследование спроса в регионе актуально не только для услуг оффлайн сегмента, но и для онлайн продаж, если нужно сократить транспортные расходы, и за счет этого сделать более выгодную цену. Хотя находятся и те, кто настолько загорается идеей, что готов приобрести желаемое, и взять все расходы на себя.
Как правильно пользоваться Яндекс Вордстат для определения спроса
Приложение Яндекса для анализа рынка — Вордстат — позволяет получить всю необходимую информацию по спросу на конкретный товар или услугу. При этом сделать это быстро, но максимально качественно. Программа дает возможность получить информацию по спросу как в масштабе всей сети, так и в регионе, городе или даже районе. Особенно это актуально для мегаполисов, где каждый район равен небольшому городу.
При этом сделать это быстро, но максимально качественно. Программа дает возможность получить информацию по спросу как в масштабе всей сети, так и в регионе, городе или даже районе. Особенно это актуально для мегаполисов, где каждый район равен небольшому городу.
Перед тем как определить спрос с помощью данного сервиса, нужно детально ознакомиться с его функционалом.
Базовые функции Вордстата, дающие правильное понимание выданного результата – «Кавычки» и «Восклицательный знак». Если написать фразу в кавычках, то покажутся данные именно по данному запросу в такой формулировке, а восклицательный знак, поставленный перед нужным словом, позволит увидеть запросы с этим словом конкретно с таким окончанием.
Дополнительный функционал Вордстата включает в себя:
- «Или» — очень полезен при сравнении и подборе семантики для личного сайта. Задается символом «|».
- «Квадратные скобки» — Фиксирует порядок расположения слов в запросе, помогает оценить популярность близких фраз и частотность запроса. Задается символами «[]».
- «Плюс» — полезен при поиске запросов, в которых используются стоп-слова. Задается символом «+».
- «Минус» — используется при исключении некоторых слов из запроса для более узкого поиска. Задается символом «-».
- «Группировка» — дает возможность группировать другие функции, которые описаны выше. Задается символами «()».
 Задается символами «[]».
Задается символами «[]».Определяем спрос на Авито
Сервис Авито позволяет выявить спрос на конкретный товар или услугу в необходимом радиусе или по всей стране. Но стоит смотреть и на актуальность запроса, который может носить сезонный характер.
Опять же при узком запросе Авито может выдать и нулевой результат, если за последнее время никто не проявил интереса к нужной теме. Это значит, что либо ниша свободна, либо предложение не актуально.
Ориентироваться в анализе спроса только на доски объявлений не стоит, они не дают нужного результат и прогноза. Вчера всем нужны были елки, потому что их показали по ТВ, сегодня никому не надо, потому что все купили вчера и на Авито спрос нулевой, но в то же время через неделю эти же елки вновь обретут спрос.
Как определить спрос в городе
Спрос в городе определяется запросами на сервисах с указанием конкретного города для поиска. Также влияет популярность продукта или услуги в регионе, производится она на месте или привозится из других регионов, отзывы, частотность поиска. В городе по анализу торговых центров можно понять, какие ниши заняты, а какие еще даже не появились и могут заинтересовать. Можно задать вопросы в сообществах города, поинтересоваться, насколько им будет интересно такое предложение. Как правило, люди с охотой отвечают, чего им не хватает и что может хорошо зайти.
Проведя опрос в различных вариантах и изучив статистику Вордстата можно сделать вывод о том, насколько интересно предложение в данном городе и рассчитать его примерную окупаемость. Если это товар или продукт, то допускается протестировать спрос, открыв временную точку в местах большого скопления людей, на ярмарке или празднике.
Оценивать спрос нужно не только на старте бизнеса, но и все остальное время, чтоб понимать, куда идет покупатель и чем он сейчас интересуется. Поддерживая постоянную связь с клиентом, предприниматель получает практически полную картину состояния своей аудитории, видит периоды спада и даже может определить причины этого. Анализируя спрос, создается маршрут клиента от рекламы к покупке. Знание ситуации на рынке позволяет своевременно реагировать на его изменения и выходить из спадов спроса с минимальными потерями. Изучение рынка нужно не только для большого бизнеса, но и для маленького предпринимателя, для которого даже небольшие убытки могут стать фатальными.
Поддерживая постоянную связь с клиентом, предприниматель получает практически полную картину состояния своей аудитории, видит периоды спада и даже может определить причины этого. Анализируя спрос, создается маршрут клиента от рекламы к покупке. Знание ситуации на рынке позволяет своевременно реагировать на его изменения и выходить из спадов спроса с минимальными потерями. Изучение рынка нужно не только для большого бизнеса, но и для маленького предпринимателя, для которого даже небольшие убытки могут стать фатальными.
Какие авто с пробегом пользуются спросом в России — журнал За рулем
По данным AVITO Авто, во втором квартале 2013 года из общего числа проданных через сайт частных объявлений 375,5 тыс. автомобилей более половины составили машины иностранных марок. Автомобили отечественных производителей выбрали 44% покупателей.
Avito 3 no copyright
По сравнению с первым кварталом 2013 года разрыв между отечественными и иностранными автомобилями увеличился на 4% (44/56 против 46/54%).
Avito 1 no copyright
Лидером квартальных продаж среди иномарок стали «японцы», «захватившие» 16,6% вторичного авторынка на AVITO Авто. Следом бок о бок идут корейские (11,4%) и немецкие (11,3%) автомобили. Доля проданных через сайт автомобилей американского производства во втором квартале 2013 года составила 8,8%. Еще 4,4% пришлись на долю «французов», 0,5% — «итальянцев», 0,3% — «британцев». Оставшиеся продажи поделили прочие европейские и азиатские производители.
Avito 2 no copyright
Что касается отдельных брендов, то лидером во втором квартале 2013 года вновь стала Toyota (8,5%). За ней следуют Hyundai (8,3%) и Ford (7,4%). На четвертом месте Chevrolet (7,2%), на пятом — Daewoo (7%). Далее марки расположились следующим образом: Nissan — 6,4%; Volkswagen — 5,9%; Opel — 5,1%; Mitsubishi — 4,9%; Kia — 4,7%; Renault — 4,6%; Mazda — 3,5%; BMW — 3,4%; Honda — 3,2%; Mercedes-Benz — 3%; Audi — 2,7%; Peugeot — 2,3%; Citroen — 0,9%. На другие автомобили по итогам второго квартала 2013 года в сумме пришлось 11% продаж.
На другие автомобили по итогам второго квартала 2013 года в сумме пришлось 11% продаж.
Среди российских производителей во втором квартале 2013 года по-прежнему лидирует ВАЗ с результатом 86%. Еще 9% продаж занимает продукция ГАЗа.
Avito no copyright
Какие авто с пробегом пользуются спросом в РоссииПо данным AVITO Авто, во втором квартале 2013 года из общего числа проданных через сайт частных объявлений 375,5 тыс. автомобилей более половины составили машины иностранных марок. Автомобили отечественных производителей выбрали 44% покупателей.
Какие авто с пробегом пользуются спросом в РоссииЖенщины с маленькими детьми активно пользуются приложениями Авито и Юла
2020-01-15
Исследовательский холдинг Ромир представляет новые медиа-данные по ТВ, радио и Интернет потреблению, которые публикуются на еженедельной основе – ТВ и радио во вторник, Интернет в среду, кросс-потребление в четверг.
Статистика приложений (Android). География: Россия 100+, Период: 06/01/2020 — 12/01/2020, Женщины с детьми 0-3
Женщины с детьми в возрасте до 3 лет более активно пользуются приложениями Вконтакте и Instagram по сравнению со всеми людьми. Кроме того, они чаще базовой аудитории просматривают объявления на Авито и Юле и используют такие приложения, как Едадил, Озон, Wildberries и Детский мир.
При использовании интернета на десктопе покупатели категории Жевательная резинка больше сидят на сайтах Вконтакте, Авито, AliExpress и Кинопоиск. Также они активнее используют сервисы Яндекса: Поиск, Дзен, Почта, Видео, Картинки и другие.
Покупатели пива Carlsberg в целом менее активны в мобильном интернете по сравнению с базовой аудиторией: они меньше сидят на YouTube и в поисковиках Google и Mail.ru. Однако, данная целевая аудитория больше интересуется новостями на Яндексе и порталах Lenta.ru и Dni.ru.
С более подробными данными по ТВ и радио-потреблению вы можете ознакомиться в разделе Медиа Рейтинги.
Данные мы получаем на основе Single Source Panel Romir* — уникального продукта команды «Ромир», направленного на кросс-анализ всех видов потребления: потребление товаров и услуг, медиа (ТВ и радио) и Интернет потребление (десктоп, мобильный и приложения). Исследование Интернет-потребления на десктопе охватывает 40 000 человек (15 000 домохозяйств), также, как и Потребительская панель «Ромир». А исследования ТВ, радио, мобильного интернета (Android) и приложений – 4 000 респондентов в городах России с численностью населения 100 000 человек и более. Подобный размер городской выборки продиктован спросом на рынке и основан на запросах текущих клиентов, однако в случае необходимости и развития рынка возможно расширение указанных параметров.
*Описание Single Source Panel (SSP) можно посмотреть по ссылке.
Ромир – крупнейший российский частный холдинг, специализирующийся на маркетинговых, медиа и социально-экономических исследованиях. Компания располагает широкой собственной региональной сетью в России и странах ближнего зарубежья. Ромир является эксклюзивным представителем международных исследовательских ассоциаций Gallup International и GlobalNR в России и СНГ, география исследований охватывает более сорока государств.
Отдел медиа исследований
Петрова Елизавета
Тел.: +7 (495) 011-00-07
petrova.e@romir.ru
Поделиться в соцсетях:
итоги 2020 года, прогнозы на 2021 год
11.02.2021
Аналитики Авито Авто опросили 10 000 россиян, а также обратились за комментариями к экспертам, чтобы узнать, как изменился рынок автомобилей в России в 2020 году и чего ожидать в 2021.
Первые два месяца 2020 года рынок традиционно раскачивался, март 2020 показал рост в 4% относительно марта прошлого года. Но уже к апрелю из-за локдауна производители сократили поставки, а шоурумы закрылись на карантин.
От резкого снижения авторынок спасли падение рубля и рост цен на машины. Во второй половине года люди стремились спасти рублёвые накопления и активно искали автомобили. Желающих приобрести транспорт было больше, чем машин в продаже, что позволило дилерам отменить скидки и активнее продавать допоборудование. В итоге доходность сделок и кумулятивная маржа выросли.
Однако всплеск продаж замедлился уже к декабрю. Некоторые дилеры называют его самым спокойным декабрём десятилетия: по данным АЕБ, по сравнению с декабрём 2019 года продажи новых автомобилей снизились на 2,1%.
«2020 год оказался одним из самых сложных для российского автомобильного рынка: продажи новых автомобилей превышали показатели предыдущего года всего 4 месяца. Несмотря на все трудности, по динамике продаж в 2020 году Россия показала один из лучших результатов среди крупнейших автомобильных рынков мира, а в Европе вышла на 4-е место. Этот год подтвердил весьма прочное положение и долгосрочную заинтересованность автопроизводителей в российском рынке, а также критически важное значение мер государственной поддержки для устойчивости автомобильного бизнеса в России».
В прошедшем году автобизнес столкнулся с дефицитом не только новых, но и подержанных машин. Из-за ажиотажного спроса часть клиентов решила продавать старый автомобиль своими силами, в итоге входящий поток б/у автомобилей в трейд-ин снизился.
Денис Мигаль, основатель сети автосалонов Fresh Auto:
«Благодаря превентивному развитию омниканальности мы нарастили долю онлайн-продаж»
Пандемия в 2020 году отразилась не только на продажах новых авто, но и на вторичном рынке. Обычно цены на подержанные машины увеличиваются вслед за прайсами новых. 2020 год не стал исключением.
В нашей компании реализация автомобилей с пробегом в 2020 году увеличилась на 3% (26 009 штук). А благодаря тому, что мы заранее развивали омниканальность и смогли нарастить долю онлайн сделок. Кроме того, мы предлагаем услуги, востребованные на рынке автомобилей с пробегом: бесплатная комиссия, проверка технического состояния и истории владения авто, быстрый выкуп и интерактивные продажи с возможностью доставки машины из другого региона. Мы думаем, что в 2021 году эти конкурентные преимущества позволят нам укрепить наши позиции.
Пополнение склада б/у транспорта затруднял и дефицит новых автомобилей. Люди не расставались со старой машиной, пока не получали возможность пересесть на новую. Для пополнения складов дилерам пришлось выкупать подержанные автомобили на открытом рынке, обзванивать собственников из объявлений на Авито и других классифайдах. На Авито им помогла новая функция «Сигнал».
«Сигнал» позволяет дилерам узнавать о размещении объявления собственником автомобиля и предлагать выкуп.
47% россиян в 2020 году отложили покупку на будущее. Главная причина — рост цен, он стал стоп-фактором для 10% опрошенных. Ещё 7% не обновили машину, потому что не захотели брать кредит, а 5% перенесли покупку из-за форс-мажорных обстоятельств, таких как потеря дохода или болезнь.
5% купили машину спонтанно. Причём женщины делали это чаще — 7% опрошенных женщин обновили машину незапланированно. Среди мужчин таких только 4%.
Спонтанные покупки новых автомобилей в основном связаны с падающим курсом рубля и ростом цен — некоторые россияне спешили приобрести новый автотранспорт до увеличения прайс-листов. На рынке машин с пробегом к ценовому фактору добавляется эксклюзивность отдельного предложения, когда в продажу поступает авто в нужной комплектации с прозрачной историей.
35% опрошенных планируют купить автомобиль, 22% — продать. Самая большая доля желающих поменять машину — в Северо-Западном федеральном округе — 38%. В прошлом году там было больше всего респондентов, отложивших покупку.
74% пользователей Авито хотят купить иномарку, 13% — отечественный автомобиль. Это средние цифры по стране, без деления на новые и подержанные машины.
В предпочтениях россиян заметна региональная специфика. В Дальневосточном федеральном округе, где традиционно много автомобилей из Японии, больше желающих приобрести подержанную иномарку — 40%. А в Приволжском федеральном округе, на родине «АВТОВАЗа», больше всего тех, кто планирует купить новый российский автомобиль — 13% жителей.
22% присматриваются к машинам за 1–3 млн ₽. По данным исследования Авито, это самый популярный ценовой диапазон. Тех, кто в 2021 году готов потратить на автомобиль более 3 млн ₽, — всего 2%. 5% респондентов намерены купить максимально бюджетное средство передвижения стоимостью не дороже 200 000. ₽.
Рита Халилова, директор по продажам ГК «КАН АВТО»
«Мы согласны с мнением большинства экспертов относительно ёмкости рынка в 2021 году и не ждём заметного роста как в сегменте новых, так и подержанных машин».
Динамика цен на автомобили из года в год показывает только рост. Мы уверены, что нынешний год не станет исключением. Но на вопрос «почему цены будут расти» односложно ответить нельзя — влияет много факторов.
Мы согласны с мнением большинства экспертов относительно ёмкости рынка в 2021 году и не ждём заметного роста как в сегменте новых, так и подержанных машин.
Прогнозируем, что определённым вызовом для дилеров станет снижение кумулятивной маржи по сравнению с 2020 годом. В первую очередь из-за сокращения дефицита автомобилей.
Уже сейчас в нашем регионе дефицит сохраняется лишь на некоторые модели и комплектации, и если тенденция сохранится, то ко второй половине года нехватка автомобилей может закончиться. Чтобы максимизировать прибыль в этих условиях, дилерам придётся сфокусироваться на выполнении планов продаж по всем брендам, которые есть в портфеле.
Руслан Абдулнасыров, основатель и владелец компании «АВТОСЕТЬ.РФ»:
«У населения в период карантина существенно уменьшился доход, что сильно повлияет на продажи автомобилей».
В текущем году рынок может как упасть до 1,5-2%, так и подняться, но в целом мы прогнозируем устойчивость показателей к предыдущему году. На количество продаж и ёмкость рынка автомобилей влияет ситуация с пандемией 2020 года.
Вдобавок у населения в период карантина существенно уменьшился доход, что является важным фактором, влияющим на продажи автомобилей. У людей нет уверенности в завтрашнем дне, чтобы совершать дорогостоящие покупки и это потенциальная угроза для авторынка в 2021 году.
Первичный рынок автомобилей в 2021 году составит примерно 1,6 млн штук. Эксперты не ожидают серьёзной динамики относительно прошлого года. Комитет автопроизводителей АЕБ прогнозирует рост на 2,1%, что эквивалентно продаже 1 632 000 машин на первичном рынке.
По итогам опроса Авито, 52% респондентов рассматривают покупку нового автомобиля в 2021 году. Купить новую иномарку хотят 43% опрошенных, новый российский автомобиль — 9%.
Андрей Каменский, директор по маркетингу АГ «АВИЛОН»:
«Мы не ожидаем в 2021 году существенного роста рынка»
Мы не ожидаем в 2021 году существенного роста рынка — показатели будут оставаться на текущем уровне. Основным сдерживающим продажи и динамику фактором остаётся дефицит автомобилей. По нашим оценкам, нехватка машин сохранится как минимум до конца первого квартала 2021 года. Возможно, уровень складских запасов не изменится до середины года. В целом объёмы продаж рынка и его динамика зависят от дальнейшей ситуации с коронавирусом, уровня цен и покупательной способности населения.
Факт возможного подорожания стимулирует рынок. По этой причине в январе большинство марок показали рост по сравнению с итогами января прошлого года. Но при этом сложно оценить спрос после очередной индексации.
Мы надеемся, что поддержанию хорошего спроса на автомобили массового сегмента будут содействовать госпрограммы льготного кредитования, которые были продлены. Дополнительно мы ожидаем увеличения популярности онлайн-сделок и кредитных продуктов.
В будущем на рынке автомобилей возможно сохранение тренда по укрупнению дилерских сетей: события 2020 года показали, насколько важно дилерам быть подготовленными к работе в новых условиях. Игроки рынка, которые предоставили в прошедшем году полный и качественный набор онлайн-услуг, не только сохранили бизнес, но и увеличили свою долю.
Денис Петрунин, генеральный директор ГК «АвтоСпецЦентр»:
«В 2021 году авторынок продолжит сокращаться, по нашим прогнозам, на 10–15% к 2020 году. Нас ждёт ещё большая непредсказуемость».
В результате адаптации к падению курса рубля по отношению к евро и доллару в 2020 году и ожидаемого повышения утилизационного сбора цены на новые поставки автомобилей 2021 года выпуска выросли на 1–5%. Однако сейчас в наличии есть автомобили большинства моделей массового сегмента по ценам 2020 года. Спрос в январе держится высокий, на уровне декабря.
В 2021 году авторынок продолжит сокращаться, по нашим прогнозам, он упадёт на 10–15% относительно итогов 2020 года. Нас ждёт ещё большая непредсказуемость. Из-за нарушения логистических цепочек продолжатся перебои в поставках автомобилей и неравномерное наполнение складов. Как итог — снова несбалансированность спроса и предложения. Кроме того, волатильность рубля в 2020 году привела к продолжению роста цен на автомобили в 2021 году, что в свою очередь повлияет на сокращение спроса.
Дефицит моделей и комплектаций присутствует практически у всех брендов. Это связано с перебоями в поставках автомобилей: нарушением сроков и объёмов. Но по многим моделям массового сегмента ещё есть в наличии автомобили по ценам 2020 года.
У большинства брендов не будет масштабных акций и программ поддержки со стороны автопроизводителей и дилеров, поэтому transaction price в любом случае будет выше.
Андрей Ольховский, генеральный директор АО «АВТОДОМ»:
«После прохождения верхнего пика цены, когда стоимость автомобиля превысит ожидания клиентов, покупательский спрос резко снизится»
По нашим прогнозам, в 2021 году ситуация на авторынке будет аналогична осени 2020 года: с одной стороны, цены на автомобили будут расти, с другой — на рынке сохранится определённый дефицит. После прохождения верхнего пика цены, когда стоимость автомобиля превысит ожидания клиентов, покупательский спрос резко снизится.
Учитывая определённый дефицит на рынке и нерегулярность поставки автомобилей, динамика продаж новых машин будет зависеть прежде всего от логистики и возможностей импортеров — это актуально как минимум на первое полугодие 2021 года.
Если по итогам первого квартала ситуация с пандемией изменится в лучшую сторону, то можем ожидать восстановления поставок и выхода на стандартную модель бизнеса. Если ситуация будет по-прежнему критическая, то дефицит продлится и далее, что однозначно скажется на объёмах продаж.
В любом случае во втором полугодии я прогнозирую охлаждение рынка: будут исчерпаны запасы спроса со стороны покупателей, и цена на автомобили будет соответствовать курсам валют по состоянию на первый квартал 2020 года.
В совокупности это может создать ситуацию с точностью до наоборот, когда на складах дилеров будут машины, а покупатели не будут готовы заключать сделки по текущей стоимости.
Если смотреть на 2021 год в целом, то динамика продаж будет в коридоре показателей 2019 и 2020 годов — скорее всего, цифра не будет выше 7–8% к объёмам 2020 года. Безусловно, внутри этой цифры будут разные показатели по массовому и премиум-сегменту. Причём последний будет чувствовать себя значительно лучше. По массовому сегменту итоги продаж будут зависеть от ценовой политики импортёров и возможной поддержки со стороны государства или кэптивных банков.
Вторичный рынок практически не изменится. В сегменте подержанных автомобилей в 2021 году представители отрасли тоже не ждут значительных колебаний. По их прогнозам, рынок сохранится на уровне примерно 5,5 млн штук.
Особенность российского б/у рынка последних лет — в старении автопарка и снижении его качества. Из-за просадки первичного рынка в середине 2010-х годов практически вдвое средний возраст автомобилей в России растёт. По данным «Автостата», на 2020 год он составляет 13,6 лет. По этой причине будет усиливаться ценовой разрыв между подержанными автомобилями в хорошем и плохом состоянии. Машины с подтверждённой и хорошей историей будут продавать быстрее и дороже, чем автомобили без сервисных отметок и с аварийным прошлым.
Данил Пивоваров, руководитель направления исследований рынка автомобилей с пробегом аналитического агентства «АВТОСТАТ»:
«Мы прогнозируем, что в 2021 году вторичный рынок автотранспорта останется на уровне 5,5 млн автомобилей в год»
«Если рынок новых автомобилей — это рынок спроса, то автотранспорт с пробегом — это рынок предложения. Рынки эти взаимосвязаны, но законы их поведения разные.
Рынком новых автомобилей управляют спрос, цены и курс рубля. Вторичный рынок гораздо более стабильный и предсказуемый. Здесь главную роль играет предложение. Сколько машин вышло на рынок — столько и будет продано.
Мы прогнозируем, что в 2021 году вторичный рынок автотранспорта останется на уровне 5,5 млн автомобилей в год».
Денис Мигаль, основатель сети автосалонов Fresh Auto:
«Скорее всего, из-за роста цен на новые авто интерес россиян ко вторичному рынку останется на уровне 2020 года, то есть вполне ощутимым»
По моим прогнозам, от 2021 года не стоит ждать масштабных прорывов. Скорее всего, не будет резкого роста и падения продаж — реализация сократится на 5–10% по отношению к показателям 2020 года. Зато автобизнес будет расширяться и максимально цифровизироваться. Ведь только те, кто смогут подстроиться под современные реалии, останутся на рынке.
Скорее всего, из-за роста цен на новые автомобили интерес россиян к вторичному рынку останется на уровне 2020 года, то есть вполне ощутимым. Соответственно, объём продаж будет равен 5,5 млн, максимум 6 млн авто с пробегом.
Из-за дальнейшего ослабления курса российской валюты заплатить за подержанные машины в 2021 году, скорее всего, придётся больше. Думаю, что стоимость автомобилей с пробегом продолжит расти до весны 2021 года или до тех пор, пока не будет отыграна девальвация в размере 30%.
Предполагаю, что вырастет доля дилеров на вторичном рынке. В 2020 году они реализовали примерно 20% от всего объёма проданных подержанных авто. Думаю, за 2 года доля официальных дилеров на авторынке России займёт около 30–35%.
Отталкиваясь от того, что с мая 2021 года покупка машины с пробегом станет доступна через сайт Госуслуг, границы региональных продаж станут размытыми. В нашей компании уже можно приобрести автомобиль в Москве, находясь в любом другом регионе, и получить его, оставаясь дома. Судя по продажам в январе, уже наметились лидеры по реализации авто с пробегом: Калининградская область — там пользуются спросом автомобили сегмента SUV — продажи выросли в среднем на 8%, Ростовская область, Татарстан, столица и Московская область.
Источник: https://www.avito.ru/blog/avtorynok
работники каких специальностей пользуются спросом на рынке труда
Официальный уровень безработицы в стране составляет 4,6%.
Сергей Антонов
трудоустроен
Профиль автораНо Росстат считает безработными только тех, кто пытался трудоустроиться весь предыдущий месяц и готов приступить к новым обязанностям в ближайшую неделю.
По данным статистиков, такой человек найдет работу в среднем через семь с половиной месяцев. В этой статье расскажем, где и кем быстрее всего получится трудоустроиться.
Кем работают жители России
Больше всего россиян работает в торговле: по данным Росстата, в этой сфере трудится 15,9% взрослых жителей России — каждый шестой. На втором месте по популярности — обрабатывающие производства: 14,1%. На третьем — образование: 9,5%.
Структура занятого населения по видам экономической деятельности, РосстатXLS, 45,5 КБ
Какая самая популярная профессия в России — сказать сложно. Статистики смотрят только на то, в какой сфере работает человек, а не на то, кем именно. Поэтому, например, водитель из «Пятерочки» — это для Росстата работник торговли, а школьный сторож — сферы образования.
Еще Росстат учитывает только официально трудоустроенных граждан. Сколько в стране продавцов, которые получают зарплату в конверте, фрилансеров-программистов, репетиторов или блогеров — государство не знает.
Сколько длится поиск работы
По статистике, типичный безработный россиянин-мужчина трудоустраивается в среднем через 7 месяцев и 9 дней. Женщине требуется на шесть дней больше.
При этом чем младше человек, тем быстрее у него получится найти работу. Например, в 19 лет россиянину для этого нужно всего четыре месяца, а в 35 — восемь месяцев. Тяжелее всего людям в возрасте от 50 до 54 лет. Если верить Росстату, в этом возрасте человек тратит на поиски места больше всего времени — почти девять месяцев.
Средняя продолжительность поиска работы в зависимости от возраста, РосстатDOC, 69 КБ
Россияне обычно ищут работу сразу несколькими способами. Самый популярный — обратиться за помощью к друзьям и знакомым. Если верить Росстату, так поступают три четверти безработных. На втором месте по популярности — специализированные интернет-сайты и СМИ. На третьем — рассылка резюме напрямую потенциальным работодателям.
Как россияне ищут работу, РосстатDOC, 68,5 КБ
В каком регионе проще найти работу
«Хедхантер» оценивает рынок труда, используя специальный индекс, который показывает, сколько резюме приходится на одну вакансию.
Индекс «Хедхантера»
Если ориентироваться на эти данные, то тяжелее всего устроиться в Чеченской республике. Здесь в 2019 году на одно место приходилось 14 потенциальных кандидатов. При этом за год количество резюме от соискателей на «Хедхантере» выросло на четверть, а число вакансий, наоборот, уменьшилось на 7%.
Если же посмотреть данные Росстата, то самый высокий уровень безработицы — в Ингушетии: 26,7%. Чечня на втором месте: 13,5%.
Все о работе и заработке
Как сменить профессию, получать больше и на чем заработать. Дважды в неделю в вашей почте
Проще всего с рабочими местами обстоят дела на Чукотке: на одну вакансию приходится 1,2 резюме. Количество открытых вакансий на «Хедхантере» за год увеличилось пропорционально числу опубликованных резюме — на 10%. На втором месте — Камчатский край: 2,7 резюме на рабочее место. На третьем — Ненецкий автономный округ: 3,2 резюме.
Самый низкий официальный уровень безработицы в России статистики фиксируют в Москве и Санкт-Петербурге: 1,4%. На втором месте — Ямало-Ненецкий автономный округ: 1,9%. Чукотка — на третьем: 2,5%.
В какой сфере самый большой дефицит кадров
Судя по индексу «Хедхантера», единственная сфера, где соискателей меньше, чем вакансий, — консультирование: на десять мест приходится девять резюме. Средняя зарплата, которую предлагали здесь работодатели в 2019 году, — 48 619 Р. Это почти на две тысячи выше средней зарплаты по стране — 46 549 Р.
Почти нет конкуренции в сфере, которую в «Хедхантере» называют «Инсталляция и сервис»: речь об инженерах по установке и настройке промышленного и телекоммуникационного оборудования. В этой отрасли на 10 вакансий приходится всего 11 резюме. Средняя зарплата — примерно как у консультантов: 46 765 Р.
Третье место в рейтинге дефицитных профессий делят специалисты в области страхования и рабочие: на 10 вакансий 16 резюме. Средняя зарплата, которую предлагают работодатели по этим отраслям, примерно одинаковая: 47 784 Р у страховщиков, 47 036 Р у представителей рабочих профессий.
Тяжелее всего устроиться на работу руководителям: конкурс составляет 11 человек на место. Правда, зарплата здесь в полтора раза выше, чем в среднем по стране: 62 810 Р.
Еще проблемы с трудоустройством у тех, кто только начинает карьеру и не имеет опыта: 10 резюме на одну вакансию.
Проект «Авито-работа» посчитал для Т—Ж другой коэффициент — он показывает, сколько раз пользователи сайта запрашивали контакты работодателя, разместившего объявление. Так можно оценить, в какой сфере люди ищут работу активнее всего.
Чаще всего соискатели откликаются на вакансии, где требуются люди без опыта: на каждое объявление откликаются 98 человек. На втором месте — сфера охраны и безопасности: в среднем контакты работодателя запрашивают 93 человека. На третьем — госслужба: 82 человека.
Самая низкая конкуренция, если верить «Авито», — в банковской сфере: в среднем на вакансию здесь реагируют 23 соискателя.
На втором месте — топ-менеджеры: на среднестатистическое объявление откликаются 24 человека. Но если ориентироваться на индекс «Хедхантера», в целом число тех, кто ищет работу руководителя, намного больше, чем размещено вакансий. Получается, либо многие безработные начальники просто не соответствуют требованиям работодателя, либо избирательно реагируют на такие объявления.
Kaggle Avito Demand Challenge: решение на 18-м месте — нейронная сеть | Автор: Kung-Hsiang, Huang (Steeve)
Как показано на изображении выше, моя модель NN состоит из 4 различных модулей, которые используют все данные, предоставленные организатором, изображения, категориальные, непрерывные и текстовые данные. Я объясню каждый из разделов в следующих параграфах.
Непрерывный
Это самый неудивительный раздел. Входной тензор непрерывных функций напрямую связан с другими модулями.Следует отметить, что обработка нулевых значений. Если отсутствуют непрерывные данные, я указываю либо 0, либо средние значения.
Категориальные
Для категориальных данных применяется слой внедрения для изучения скрытого представления этих дискретных значений. Я знаю, что это может быть не новая идея, но я впервые использовал категориальное встраивание, поскольку я никогда не использовал NN для работы со структурированными / табличными данными. Понятие категориального вложения похоже на вложение слов. Категориальные значения отображаются на обучаемые векторы внедрения, так что эти векторы содержат значения в скрытом пространстве.Это помогает избежать редкости категориальных функций с горячим кодированием и повысить производительность модели.
Текст
Текстовая часть моей сети NN относительно проще, чем подход других победителей. Нет ни сложной повторяющейся единицы, ни сверточного слоя, ни предварительно обученного встраивания. Я не уверен, почему, но ни один из них не работает на моей модели NN. Единственная уловка здесь — это использование общего слоя встраивания, мотивированного второстепенным решением в задаче Mercari.Две текстовые записи, заголовок и описание, встраиваются на основе одной и той же матрицы встраивания. Это не только помогает ускорить обучение NN, но также приводит к более быстрой сходимости и меньшим потерям.
Image
Мой первый подход к данным изображений заключался в использовании предварительно обученных моделей ImageNet для извлечения элементов с головой или без головы этих моделей. Я пробовал ResNet50 и InceptionV3; к сожалению, ни один из них не работал. В то время, когда до соревнований оставалось около 2 недель, кто-то на дискуссионном форуме сказал, что его модель включает несколько слоев свертки для обучения необработанного изображения вместе с другими функциями.Поэтому я начал переписывать свой код, чтобы он использовал генератор для чтения изображений и табличных данных, поскольку было невозможно загрузить все данные изображения в ОЗУ. Опробовав несколько структур, я обнаружил, что 1 ячейка InceptionV3 + несколько слоев свертки подходят для меня лучше всего (поскольку у меня был только графический процессор K80 на GCP, проверка результатов всего нескольких экспериментов занимает очень много времени) .
- Решение NN, занявшее первое место, также столкнулось с низкой производительностью извлеченных функций из большинства предварительно обученных моделей ImageNet.Они объединились, используя верхние слои VGG + средние уровни ResNet50. Самая большая разница между их подходом и моим предыдущим заключается в том, что перед тем, как извлеченные элементы изображения объединяются с другими записями, они применяли средний пул и добавляли плотный слой.
- Взаимодействие категориальных признаков: объедините две категориальные особенности и обработайте их как новую функцию.
- Обучение без учителя: используйте автоэнкодер для извлечения векторов из категориальных данных.
- Стратегия проверки: помните, что значение перекрывающейся функции между каждой складкой должно быть таким же, как при разделении на поезд / тест.(особенно идентификатор пользователя в этом соревновании)
- Функция потерь: все 3 лучших решения используют двоичную кросс-энтропию в качестве функции потерь, в то время как я использовал MSE для всего соревнования. Я должен был попробовать больше функций потерь, таких как потеря BCE и Huber.
- Штабелирование: мы начали штабелирование за неделю до окончания конкурса, поэтому у нас есть только несколько базовых моделей с неглубоким штабелированием. Почти во всех топовых решениях использовалось большое количество моделей для более широкой и глубокой укладки (занявший второе место использовал 6 слоев…)
Мне было очень весело в этом соревновании.Я хотел бы поблагодарить своих товарищей по команде, всех людей, которые публично делятся своими идеями / решениями. Я многому у вас научился! Я также хотел бы поблагодарить Kaggle и организаторов за проведение такого грандиозного конкурса. Без вас я бы не смог отточить свои навыки машинного обучения.
Если вы хотите узнать больше о моем решении, вы можете обратиться к этому репозиторию Github.
Приближение к конкурсу на Kaggle: вызов прогнозирования спроса на Avito (Часть 1) | Крис Стивенс
Я уже писал немного о Kaggle раньше и считаю его одним из лучших ресурсов для тех, кто пытается заняться машинным обучением.Вы можете не только найти настоящие проблемы машинного обучения, но и найти большое открытое сообщество, которое любит рассказывать о том, что они делают, и об идеях, которые они пытаются воплотить.
Сегодня в качестве примера я остановлюсь на Avito Demand Prediction Challenge. Это проблема, создаваемая российским сайтом тематических объявлений, который хочет предоставить своим пользователям более точные данные о том, насколько хорошо их реклама будет честной при использовании сайта. Ключевой целью является предотвращение разочарования пользователей, которые не могут продать свои товары.
Поскольку это соревнование проводится в течение короткого времени, на момент написания в нем уже было ~ 1000 участников, при этом наивысший результат достиг средней квадратичной ошибки 0.2180. Скорее всего, если вы новичок в ML, как я, вы не сможете прикоснуться к этому результату, но не волнуйтесь, нам всем нужно с чего-то начинать. Давайте сначала посмотрим на набор данных.
Данные
Что делает эту задачу интересной, так это диапазон данных, с которыми вы можете работать. Основные данные объявления состоят из региона, города, родительской категории, категории, заголовка, описания, цены, даты активации, типа пользователя, необязательного изображения, кода классификации изображений и (нашей целевой) вероятности сделки.
Самая важная вещь при запуске новой проблемы машинного обучения — это обработать данные. Поймите, что у вас есть и к чему вам нужно добраться. Это мгновенно дает вам целенаправленную информацию о том, какой подход может сработать. Кроме того, вы должны начать формировать картину того, какие точки данных будут ключевыми, те, которые будут иметь наибольшее влияние на ваши прогнозы. В дополнение к просмотру необработанных точек данных обратите внимание на то, как ваши данные естественно выглядят для пользователей:
Снимок экрана с листингом Avito.Это может дать дальнейшее понимание того, как пользователи могут использовать этот сайт, что может помочь посеять ваши идеи о наиболее значительных последствиях для вероятности сделки (наша цель). Мои выводы из этого: изображение, название и цена занимают почетное место на сайте. Поэтому, вероятно, они имеют большее влияние, чем описание. Это может оказаться неправильным после более глубокого анализа. Нам также необходимо рассмотреть список страниц, которые похожи на эти:
Хорошее понимание того, как пользователи создают данные, которые вы будете использовать, имеет неоценимое значение для разработки вашего алгоритма, даже если вы сначала не можете их увидеть.
Загрузите копию данных, даже если вы планируете использовать облачные ресурсы Kaggle, поскольку нет лучшей интерактивности, чем иметь ее на вашем собственном ПК.
Теперь мы можем поиграть с нашими данными, чтобы увидеть, сможем ли мы получить дополнительную интуицию о том, какая модель может быть лучшей, или даже просто для лучшего понимания наших данных. Как обычно, я буду использовать Pandas, так как лучшего инструмента для быстрой обработки и работы с вашими данными нет. Первым делом я посмотрел на наши числовые столбцы: price, deal_probability, item_seq_number.Я буду использовать Pandas, встроенные в инструменты визуализации, чтобы получить общий вид. Сначала я использовал pandas.plotting.scatter_matrix, чтобы получить:
Это отображает каждую переменную относительно другой переменной и выводит красивую вещь типа матрицы графа. Я удалю выбросы и построю график заново, чтобы придать нашим данным больше формы:
Вот некоторые вещи, которые я сразу заметил:
- Есть много дешевых предметов.
- Вероятность сделки уменьшается по мере того, как пользователи публикуют больше элементов (item_sequence_number).Это могло быть связано с плохим качеством предметов или сообщений или чем-то еще. Возможно, что-нибудь для изучения позже.
- Товары с низкой ценой имеют более высокую вероятность сделки.
- Существует небольшая корреляция между более низкой ценой и количеством товаров, которые публикуются пользователем.
Не решив сразу нашу проблему, я чувствую, что приобрел некоторую дополнительную интуицию в своих данных и, следовательно, в поведении пользователей, что бесценно.
Я пойду по этой дороге завтра. В первую очередь я хочу посмотреть на категоризированные данные, сколько и каких типов существует: «parent_category_name», «category_name», «user_type», «image_top_1» и что они могут означать в более широком контексте наших данных.Кроме того, мне нужно понять, что содержат «param_1», «param_2», «param_3».
Как всегда, мой текущий код можно найти на моем Github. Это покажет вам, как создавать диаграммы рассеяния и как я начинаю исследовать свои данные.
Форумы
Другой неизмеримо ценный ресурс Kaggle — это форумы или обсуждения, связанные с каждым соревнованием. Часто эти пользователи публикуют тестовые решения или ядра, которые вы можете просто разветвить и использовать в качестве базовой точки. Вокруг конкурса идей также ведутся всевозможные дискуссии, это действительно отличное совместное сообщество, несмотря на то, что оно оформлено как соревнование.Я настоятельно рекомендую прочитать форумы, прежде чем начинать какие-либо испытания.
Спасибо за чтение. Завтра я продолжу изучать базовые данные и начну думать о различных алгоритмах, которые я могу реализовать.
Часть 2
[Примечания] Задача прогнозирования спроса Avito на Kaggle (2018) | Автор Ceshine Lee | Настоящее
Мультимодальное обучение с изображениями, текстом и столбцовыми данными
Кредит на фотоВведение
Этот конкурс требует от специалистов по данным «спрогнозировать спрос на онлайн-рекламу на основе ее полного описания (название, описание, изображения и т. Д.).), ее контекст (географически, где она была размещена, похожие объявления уже размещены) и исторический спрос на аналогичные объявления в аналогичных контекстах ».
Я не планировал тратить много времени на это соревнование, пока не посмотрел Fast.ai Урок 10 [1] и не решил найти реальный набор данных, чтобы попробовать языковую модель из обновленной библиотеки fast.ai (с менее чем до окончания конкурса осталось три недели). Тонкая настройка универсальной языковой модели показала свою эффективность для классификации текстов [2,3]. Я задавался вопросом, работает ли это также для регресса.(Недавно OpenAI опубликовал статью, расширяющую структуру с использованием трансформаторных сетей [4,5].)
Путем предварительного обучения языковой модели извлеките кодировщик в сочетании с числовыми и категориальными функциями, получившаяся модель нейронной сети усреднена с общедоступным LightGBM Ядро добралось до бронзовой медали (~ 125-е место, насколько я помню) в течение недели. Я был заинтригован и решил потратить некоторое время, чтобы добавить в модель элементы изображения. Окончательная ансамблевая модель заняла 54-е место в частной таблице лидеров:
- К счастью, эта модель не подошла более чем к общедоступной таблице лидеров.Скорее всего, модель все еще не соответствует требованиям. Из-за некоторых ошибок, которые я упомяну в следующих разделах, обучение идет медленнее, чем должно быть.
- Я не обучал кодировщик текста с нуля в качестве контрольной группы. Но поскольку я действительно не занимался разработкой дополнительных функций, похоже, что языковая модель дала мне некоторый толчок.
Цель этого поста
Как видите, я действительно не делал ничего особенного, кроме как предварительно обучил языковую модель. И я действительно собирался не писать об этом конкурсе.Но есть некоторые детали реализации, которые меня беспокоят, и некоторые из них до сих пор не решены полностью. Я подумал, что их записывание поможет мне избежать повторения тех же ошибок или обнаружения такой же путаницы в будущем. Кроме того, я хочу попробовать сделать диаграммы архитектуры модели с помощью Google Drawings.
Чистую модель нейронной сети можно разделить на 3 этапа:
- Предварительное обучение языковой модели
- Извлечение признаков изображения
- Обучение модели регрессии
Входной токен поступает из объединенных полей title и description .
Уровень внедрения инициализируется предварительно обученными векторами FastText [6]. Это сложно, потому что мы хотим, чтобы матрица вложения также была весами слоя softmax [7, 8]. Вот что я сделал:
Learner.models.model [0] .encoder.weight = nn.Parameter (T (векторы))
Learner.models.model [1] .decoder.weight = (
Learner.models. model [0] .encoder.weight
)
В последней модели я использовал слои LSTM, которые нормально работали с настройками fast.ai по умолчанию. Для QRNN параметры нуждаются в некоторой настройке, я не закончил тренировку QRNN до конца соревнований.
Вот график скорости обучения, который я использовал:
lrs = 1e-4
Learner.fit (lrs, 1, wds = 1e-7, use_clr = (32, 5),
cycle_len = 6, use_wd_sched = True)
Предварительно обученная модель Resnet101 взята из официальной библиотеки torchvision , а модель Resnext101_64x4d — из Cadene / pretrained-models.pytorch [9]. Последний средний уровень объединения был заменен слоем глобального объединения для поддержки изображений произвольного размера.
Были использованы два вида предварительной обработки изображения: обрезка по центру и отступы до квадрата.Отступы до квадрата, казалось, давали лучшие результаты, но лишь незначительно. Вы можете использовать оба метода и объединить результаты. Я не сделал этого из-за нехватки места на диске.
self.transform_pad = transforms.Compose ([
ResizeAndPad (299),
transforms.ToTensor (),
transforms.Normalize (
среднее = [0,485, 0,456, 0,406],
std = [0,229, 0,224, 0,225]) )
]) self.transform_center = transforms.Compose ([
transforms.Resize (299),
transforms.CenterCrop (299),
transforms.ToTensor (),
transforms.Normalize (
mean = [0,485, 0,456, 0,406],
std = [0,229, 0,224, 0,225])
])
Выходные данные выгружаются на диск как один файл рассола на изображение, в попытке избежать взрыва памяти. Это ошибка, потому что из-за этого общий размер диска увеличивается, а чтение замедляется. Лучше всего использовать numpy.memmap.
Здесь собраны все части. Числовые характеристики были нормализованы до нулевого среднего и стандартного отклонения.Категориальные размеры внедрения были относительно консервативными по сравнению с тем, что использовали другие конкуренты:
self.region_emb = nn.Embedding (28, 3)
self.city_emb = nn.Embedding (290, 5)
self.p_cate_emb = nn.Embedding (9 , 3)
self.cate_emb = nn.Embedding (47, 5)
self.image_top1_emb = nn.Embedding (888, 5)
self.user_type_emb = nn.Embedding (3, 2)
self.weekday_emb = nn.Embedding (7, 3)
self.param1_emb = nn.Embedding (204, 5)
self.param2_emb = nn.Embedding (131, 3)
self.param3_emb = nn.Embedding (113, 3)
Голубые плотные слои действуют как субдискретизаторы. Они уменьшают размеры элементов изображения и выходных данных кодировщика до 128. Мы можем извлекать элементы из этих слоев и передавать их в модели GBM.
Плотные слои имеют одинаковую структуру. Вероятно, нормализацию слоя следовало поставить после Relu. Но каким-то образом я поместил его перед Релу и до сих пор не думал об этом…
Для этой регрессионной модели модель и ученик были почти полностью переписаны.Использовались только некоторые служебные функции из библиотеки fast.ai (странно, что при использовании класса Learner из библиотеки fast.ai потери при проверке всегда в некоторой степени уменьшались. Я не мог Найдите, где была проблема. У моего индивидуального ученика такой проблемы не было.)
Я повторно реализовал наклонную треугольную скорость обучения [2,10], расширив официальный класс планировщика скорости обучения:
Модель обучена с использованием Фреймворк 5-кратной проверки.Прогнозы теста от каждой складки были усреднены, чтобы получить окончательные прогнозы.
Ensemble
Лучшая одиночная (и окончательная) модель чистой нейронной сети дает 0,2201 публичных и 0,2242 частных потерь, что занимает от 534 до 548 места в частной таблице лидеров.
Если мы извлечем изображения и текстовые функции из сети (голубые плотные слои) и поместим их в модель LightGBM, слегка измененную по сравнению с общедоступным ядром. Мы можем получить единственную (своего рода) модель с 0.2197 публичных и 0,2236 частных убытков, которые занимают 189–210 места в частной таблице лидеров.
Чтобы попасть на 54-е место, нам нужно скормить прогнозы вне складки от разных моделей (ту, у которой resnet101 с обрезкой по центру, ту, у которой resnext101_64x4d с отступом до квадрата, public lightgbm, lightgbm с NN функции и т. д.) в модель LightGBM. Здесь важно разнообразие моделей. Поскольку я использую только один предварительно обученный кодировщик языковой модели, я думаю, что есть еще некоторые низко висящие плоды, которые нужно захватить.Конечно, есть и другие приемы стекирования / ансамбля, которые могут еще больше повысить производительность. Вы можете проверить, чем поделились на форуме другие конкуренты, чтобы получить подсказки.
Вот и все! Это действительно легкий процесс, который работает на удивление хорошо. На прошлой неделе я в основном оставлял свою машину, чтобы обучать модель в течение 24+ часов, возвращался и вносил некоторые изменения, а затем повторял цикл. Я мог бы сделать гораздо больше итераций, если бы проблема с файлом изображения была решена должным образом. Это подводит нас к последнему разделу:
Обработка большого количества небольших файлов (например,
).грамм. Images) на диске
На моем компьютере был раздел ext4 с поддержкой SSD с 40+ ГБ свободного места, раздел NTFS с поддержкой SSD с более чем 70 ГБ свободного места и раздел NTFS с жестким диском со свободным пространством 1 ТБ. У нас есть более миллиона изображений из обучающих и тестовых наборов данных. Это стоит около 60 ГБ места.
Я обнаружил, что чтение изображений из NTFS с жестким диском мучительно медленно. Даже поиск файла в командной строке может занять секунды. Я провел небольшое исследование и выяснилось, что NTFS не может обрабатывать слишком много файлов в одной папке:
Итак, я написал сценарий для размещения изображений в подпапках таким же образом, как:
Производительность кажется лучше, при минимум перемещение изображений с HDD на SDD было быстрее.Я не стал тратить больше времени на изучение этой проблемы и перешел к использованию раздела NTFS с поддержкой SSD для хранения файлов изображений и раздела ext4 с поддержкой SSD для хранения функций извлеченных изображений. Как я упоминал ранее, это все же немного замедлило обучение модели, и использование numpy.memmap вместо сброса отдельных файлов рассола должно быть намного лучше.
Подобные проблемы случаются со мной раз в несколько месяцев. Поэтому после соревнований я решил потратить некоторое время, чтобы выяснить, как это правильно сделать, и написал несколько простых скриптов для тестирования различных схем:
Однако результаты были очень противоречивыми.Однажды я обнаружил, что плоская структура работает медленнее, чем вложенная. На следующий день вложенная структура была медленнее плоской. Это было неприятно. Я подозреваю, что ОС производила некоторую оптимизацию под капотом, но у меня пока нет таких знаний. Так что это все еще загадка, ожидающая своего решения .
Я бы, вероятно, просто создал экземпляр в Google Cloud Compute с подключенным большим разделом с поддержкой SSD и достаточно большой памятью для загрузки набора данных, если бы у меня был бюджет. Это значительно упростило бы задачу.В любом случае использование жесткого диска для обслуживания большого количества произвольных операций чтения — плохая идея.
- Fast.ai: 10 — Классификация и перевод НЛП
- Ховард Дж. И Рудер С. (2018). Тонкая настройка универсальной языковой модели для классификации текста.
- Знакомство с современной классификацией текста с универсальными языковыми моделями.
- Рэдфорд, А. и Салиманс, Т. Улучшение понимания языка с помощью генеративного предварительного обучения.
- Блог OpenAI: Улучшение понимания языка с помощью обучения без учителя
- E.Grave *, P. Bojanowski *, P. Gupta, A. Joulin, T. Mikolov, Изучение векторов слов для 157 языков
- «Использование вложения вывода для улучшения языковых моделей» (Press & Wolf 2016)
- «Связывание Векторы слов и классификаторы слов: структура потерь для языкового моделирования »(Инан и др., 2016)
- Предварительно обученные модели для Pytorch (Github)
- Лесли Н. Смит. 2017. Циклические темпы обучения для обучения нейронных сетей.
GitHub — RussellXing / Avito-Demand-Prediction
## Инструктор: Джонстон Патрик Холл ##
## Название команды: ##
Мастер GY
## Член команды: ##
- Ся, Пей-Сюань
- Лю, Мики
- Xing, Гуанюй
- Цзэн, Цзивэй
Дата окончания: 27 июня 2018 г.
О проекте
## Авито.ru ## — самый популярный сайт объявлений в России и третий по величине сайт объявлений в мире после Craigslist и китайского сайта 58.com. В декабре 2016 года его ежемесячно посещали более 35 миллионов уникальных посетителей. В среднем пользователи Avito.ru размещают более 500 000 новых объявлений ежедневно, а общее количество объявлений составляет около 30 миллионов активных списков.
https://www.kaggle.com/c/avito-demand-prediction
При продаже подержанных товаров в Интернете сочетание крошечных нюансов в описании товара может иметь большое значение для повышения интереса.И даже при оптимизированном перечне продуктов спрос на продукт может просто не существовать, что расстраивает продавцов, которые, возможно, слишком много инвестировали в маркетинг.
## Target: ## В этом конкурсе Avito предлагает нам спрогнозировать спрос на онлайн-рекламу на основе ее полного описания (заголовок, описание, изображения и т. Д.), Ее контекста (географически, где она была размещена, похожие объявления уже размещено) и исторический спрос на похожие объявления в аналогичных контекстах. Обладая этой информацией, Avito может проинформировать продавцов о том, как лучше всего оптимизировать их листинг, и дать некоторое представление о том, сколько процентов они реально должны ожидать.
О ноутбуке
Впереди еще одно захватывающее соревнование, в котором участвуют как NLP (текстовые данные на русском языке), так и графические данные, а также числовые. В этом блокноте мы рассмотрим извлечение функций, интеллектуальный анализ текста и обучение моделей Gradient Boosting Machine.
## Шаги: ##
- Импорт наборов данных
- Перевести столбцы с русского языка в столбцы на английском языке или заменить киллирические алфавиты римскими алфавитами.
- Разделить наборы данных для обучения на обучение и проверку
- Заполнить пустые значения
- Извлечение признаков из активных таблиц и таблиц периодов
- Извлечение признаков с текстовыми столбцами
- Кодировка этикетки
- TF-IDF
- Wordbatch
- Извлечение функций изображения с помощью Keras
- Модель поезда с Light GBM
- Модель поезда с XGBoost
- Отправьте результаты и выберите модель
Naspers получает полный контроль над русским сайтом объявлений Avito за 1 доллар.Сделка 16B — TechCrunch
Южноафриканский интернет-конгломерат Naspers известен прежде всего тем, что поддерживает китайского технологического гиганта Tencent, но он также управляет обширной сетью компаний по размещению объявлений в Интернете. Эта сеть стала немного больше после того, как Naspers взял под полный контроль российскую Avito за счет новых инвестиций в размере 1,16 миллиарда долларов, которые увеличили свою долю владения до более чем 99 процентов.
Avito — лучший сайт объявлений в России, который ежедневно посещают 10,3 миллиона уникальных посетителей. В настоящее время в нем около 47 миллионов объявлений, охватывающих категории товаров, автомобилей, недвижимости, вакансий и услуг.
Сделка, которая была заключена через OLX Group Naspers, увеличивает ее долю до 99,6% на полностью разводненной основе и оценивает всю компанию в 3,85 миллиарда долларов.
Хотя объявления могут звучать как ретро-уголок электронной коммерции, это все еще растущий бизнес (просто спросите Facebook, который расширяет свой собственный рынок и расширяет его присутствие в собственной сети).
Ведущие местные игроки продолжают набирать обороты, особенно на развивающихся и развивающихся рынках.За последние шесть месяцев, закончившихся 30 сентября, объем продаж Avito составил 10,3 миллиарда рублей (157,50 миллиона долларов), что на 30 процентов больше, чем годом ранее; рентабельность EBITDA составляет 65,4%, листинговые акции выросли на 7,4% до 17,46 млн. — по данным Vostok New Ventures, одного из спонсоров этой сделки.
«Талантливая команда менеджеров Avito во главе с генеральным директором Владимиром Правдивым продемонстрировала способность последовательно добиваться значительного роста с течением времени», — сказал Мартин Шипбауэр, генеральный директор OLX Group.«Деловые показатели превосходны, и мы с нетерпением ждем продолжения этой тенденции за счет дальнейшего использования технологий, знаний и опыта Avito в рамках OLX Group и наоборот».
В частности, в России рынок имеет большой потенциал в области электронной коммерции — в стране очень высокий уровень проникновения Интернета и смартфонов с большим населением, но по общему размеру рынка он отстает от Великобритании, Франции и Германии. По оценкам Morgan Stanley, к 2020 году рынок будет стоить около 31 миллиарда евро, но для сравнения в 2017 году U.K. уже продвигала 200 миллиардов, а Франция и Германия, соответственно, получали более 90 миллиардов евро в год от продаж электронной коммерции.
Аналитикиподчеркнули, что одной из проблем в России является отсутствие на рынке одного конкретного сильного лидера в области электронной коммерции: Яндекс (в партнерстве со Сбербанком), Mail.ru (в партнерстве с Alibaba), Ozon (частично при поддержке Rakuten). ) и Wildberries вместе занимают только 27 процентов рынка. Это оставляет дверь открытой для того, чтобы кто-то мог войти и укрепить еще больше, и это представляет двойную возможность для Naspers: он может либо получить выгодную сделку для Avito от другого покупателя, либо сделать решительный шаг, чтобы сделать это самостоятельно, используя Авито как его точка опоры.
Naspers-OLX первоначально приобрела контрольный пакет акций в 2015 году за счет инвестиций в размере 1,2 миллиарда долларов. До этого она участвовала в Avito еще в 2013 году, когда компания была образована в результате слияния Slando.ru и OLX.ru, двух конкурентов, которых поддерживал Naspers.
Укрепление своей позиции в компаниях, где она уже сильна, помогает Naspers также использовать денежные средства от этих операций для инвестирования в новые области бизнеса, такие как доступ к большему количеству услуг по запросу и инновациям в финансовых услугах в дополнение к прежним областям.
«Avito — ведущий игрок в сфере онлайн-объявлений в России, и наше решение увеличить нашу долю отражает нашу веру в долгосрочные перспективы этого великого бизнеса и российского интернет-рынка», — сказал Боб ван Дейк, генеральный директор Naspers. «Эта инвестиция еще больше укрепляет наши глобальные позиции в сфере онлайн-объявлений, что является основным направлением деятельности Naspers наряду с онлайн-доставкой еды и финтех».
даррагдог / авито-спрос — githubmemory
Kaggle — прогноз спроса на Avito
Решение за 5-е место — команда Optumize
Прогнозируйте спрос на онлайн-объявления
https: // www.kaggle.com/c/avito-demand-prediction
Модели Progrssion
Одиночные модели
Модель Small Val 5CV Val Leaderboard Комментарий
================================================== ==============================================
lgb_1406A 0.2113 0.2136 ?????? тюнинг - от 250 до 1000 листов
lgb_1406 0,2113 0,2136 ?????? тюнинг - от 250 до 1000 листов
lgb_1106A 0.2117 0,2140 ?????? Добавить дополнительные функции кодирования
lgb_1006 0,2120 0,2153 ?????? Добавить параметры параметров
lgb_0906 0,2123 0,2158 ?????? Добавить переоценки рейтинга цен
lgb_0206 0,2132 0,2162 ?????? Добавить перевод заголовка как col и tfidf it
lgb_3105 0,2134 0,2168 0,2190 Особенности мета-изображения
rnndh_0406a 0,2136 0.2194 Добавить коэффициенты цен
lgb_2705B 0,2137 0,2168 0,2194 соотношения imgtop1; более длительная ранняя остановка; удалить категориальный
lgb_2705A 0.2139 ?????? 0.2197 Удалить категории, добавить соотношение цены image_top_1
lgb_2505 0,2143 0,2167 0,2202 Подробнее FE - соотношение цены и позиции по категории / названию
lgb_2405D 0.2145 ?????? 0,2204 Соотношение цен по категории / титулу
lgb_2405 0.2152 ?????? 0.2211 pymorph на тексте
rnn_2605 0,2146 ?????? 0.2213 Усреднение логита и удаление стоп-слов
lgb_2205 0.2153 ?????? 0.2213 Добавить функцию выступа на текстовых и графических данных.
rnn_2205 0,2149 ?????? 0.2215 Обработка русского текста
lgb_2205 0.2157 ?????? 0.2215 Добавить функцию выступа на текстовых данных
mlp_1905 0.2159 ?????? 0.2217 Добавьте разные виды для непрерывной группировки
mlp_1705 0,2162 0,21875 0,2217 Добавить совокупные функции из активных файлов
rnn_2105 0,2153 ?????? 0,2221 только представление RNN, больше регуляризации .2153 при проверке
mlp_1605B 0.2166 ?????? 0.2224 Добавить все заголовки элементов из файлов avctive для каждого пользователя
lgb_2105C 0.2162 ?????? 0.2225 Добавить счетчик и кодировку
mlp_1605A 0.2170 ?????? 0,2228
nnet_1505 0,2177 ??????
lgb_2105 0.2174 ?????? 0,2133
lgb_1404 0.2182 ?????? 0,2241
Смесь (средневзвешенное значение)
Модель Small Val 5CV Val Leaderboard Комментарий
================================================== ==============================================
blend3x_2605 ???? ????? 0.2188 Смесь 0,25 * mlp_1705, 0,5 * lgb_2505 и 0,25 * rnn_2205
all_2405 ???? ????? 0,2193 Равная смесь mlp_1905, lgb_2205 и rnn_2205
mlp_1905 ???? ????? 0,2204 MLP 1705A и 1905 50/50 и смешайте 50/50 с лучшими LB
mlp_1705A ???? ?????? 0.2204 Взвешенное среднее mlp и лучшее ядро lb https://www.kaggle.com/lscoelho/blending-
mlp_1605B ???? ?????? 0.2208 Взвешенное среднее значение mlp и лучшее ядро lb https://www.kaggle.com/lscoelho/blending-models-lb-0-2216
Стек
Модель Small CV Val 5CV Val Таблица лидеров Комментарий
в сценарии смешивания
================================================== ==============================================
L1GBM_2306 0,2113 ????? 0.2147 Дополнительные функции гребня и добавление пользовательской энтропии
L1GBM_2006A 0.2118 ????? 0.2151 разных tfidf
L1GBM_1606B 0.2122 ????? 0.2153 Дополнительные функции на уровне L2
L1GBM_1506B 0.2126 ????? 0.2154 Сумка L2 lgb; Сумка для подводной лодки 1406
L1GBM_1506 0.2127 ????? 0.2155 Добавить тюнинг листьев lgb 1406
L1GBM_1006A 0.2133 ????? 0.2161 Добавить параметры параметров
L1GBM_1006 ?????? ????? 0.2163 Добавить ценовой рейтинг
L1GBM_0406A ?????? ????? 0.2166 исправлена ошибка lgb на L1, хеш 'text' вместо описания
L1GBM_0306A ?????? ????? 0.2167 Включен перевод названия LGB
Вложения слов
================================================== =================================================
features / wiki.ru.vec - https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md
cc.ru.300.vec.gz - https: // github.com / facebookresearch / fastText / blob / master / docs / crawl-vectors.md
all.norm-sz100-w10-cb0-it1-min100.w2v - http://panchenko.me/data/dsl-backup/w2v-ru/
Конкурс прогнозирования спроса Avito
Соревнования, Проекты ·Проверить код github
Avito запустил конкурс на Kaggle, предлагая пользователям предсказать Avito, чтобы спрогнозировать спрос на онлайн-рекламу на основе ее полного описания (заголовок, описание, изображения и т. Д.)), ее контекст (географически, где она была размещена, похожие объявления уже размещены) и исторический спрос на похожие объявления в аналогичных контекстах.
Введение
Поскольку спрос на рекламу был многообещающей темой, меня привлекли попытки поработать над этим конкурсом, имея возможность объединить несколько типов функций.
В качестве отправной точки я начал читать опубликованные ядра и некоторые статьи. Прогнозирующий документ Dimitri Ad Clicking был подробным привлекательным документом, который предсказывал вероятность того, что пользователь нажмет на рекламу или привлечется к ней на основе миниатюры рекламы. .
В этом документе были представлены некоторые функции изображений, затем эти функции были реализованы с использованием OpenCV и добавлены к базовой модели LightGBM.
Характеристики изображения
вычислить простоту изображения => Используется для вычисления простоты входного изображения.
- Статистика основных сегментов изображения
=> Используется для извлечения базовой статистики сегментации изображений (набор из 10 функций).
image face feats => Используется для извлечения количества лиц из входного изображения с использованием предварительно обученного HaarCascade из opencv.
умений просеивания изображений => количество ключевых точек отсеивания, извлеченных из входного изображения
image rgb simplicity => получить функцию простоты изображения из изображения RGB
image hsv simplicity => получить функции простоты изображения из hsv image
- Гистограмма оттенков изображения
=> характеристики изображения из гистограммы изображений HSV
изображение в оттенках серого, простота => используется для упрощения функций на изображениях в оттенках серого
резкость изображения => используется для расчета оценки резкости изображения
контраст изображения => используется для расчета показателя контрастности изображения
насыщенность изображения => используется для расчета насыщенности изображения
яркость изображения => используется для расчета показателя яркости изображения
красочность изображения => используется для расчета показателя красочности на основе бумаги
Текстовые элементы
Векторизатор подсчета для заголовка и для описания, а также количество слов в обоих из них (пользователя привлекает краткое и прямое описание).
Была извлечена функция, называемая индексом удобочитаемости Flesch English. Этот индекс удобочитаемости, основанный на пакете словарей Pyphen, был рассчитан путем подсчета средней длины предложения, которая представляет собой подсчет лексиконов по количеству предложений, найденных во входном описании на основе знаков препинания.
def flesch_reading_ease (текст):
ASL = avg_sentence_length (текст) # lexicon_count / nsentences
ASW = avg_syllables_per_word (text) # количество слогов, проверенных Pyphen
FRE = 206.835 - поплавок (1.015 * ASL) - поплавок (84.6 * ASW)
вернуть legacy_round (FRE, 2)
Эта функция вместе с функциями векторизатора подсчета для заголовка и описания входных данных улучшала модель, сложная часть входного текста — языковой барьер (русский язык). Мне не удалось проверить правильность индекса читабельности или проверить текстовые шаблоны, чтобы получить больше возможностей.
Выбор функций
Используется пакет BorutaPy для выбора всех ранее извлеченных функций (изображения и текст).