 Бизнес-Блог Блоготей Бизнес-Блог «Блоготей» — информационный блог о бизнесе и финансах. Полезные статьи и новости из мира бизнеса, финансов, банков, экономики, инвестиций.
Бизнес-Блог Блоготей Бизнес-Блог «Блоготей» — информационный блог о бизнесе и финансах. Полезные статьи и новости из мира бизнеса, финансов, банков, экономики, инвестиций. 
Как получить выписку из ЕГРЮЛ или ЕГРИП в программе СБИС?
В программе СБИС вы можете просмотреть выписку из ЕГРЮЛ/ЕГРИП или получить юридически значимую с подписью ФНС.
Пошаговая инструкция: Как посмотреть выписку из ЕГРЮЛ/ЕГРИП в программе СБИС?
Шаг 1. Поиск организации
Зайдите в раздел «Компании». В поисковой строке введите название или реквизиты и нажмите «Найти».
Для примера найдем организацию «Золотое дно».
Рис. 1. Раздел «Компании»
Шаг 2. Получение выписки ЕГРЮЛ/ЕГРИП
Организация «Золотое дно» является юридическим лицом, поэтому программа предлагает просмотреть выписку из ЕГРЮЛ. Нажмите в правом столбце на «ЕГРЮЛ». Выписка откроется в новом окне.
Если интересующая вас организация —это ИП, то программа предложит просмотреть выписку из ЕГРИП.
Рис. 2. Информация о компании
Выписку можно сохранить или распечатать.
Рис. 3. Выписка из ЕГРЮЛ
Заключайте сделки только с надежными контрагентами!
Начните работу вместе с СБИС «Всё о компаниях и владельцах»
Пошаговая инструкция: Как запросить выписку из ЕГРЮЛ/ЕГРИП с подписью ФНС в программе СБИС?
Шаг 1. Поиск организации
Зайдите в раздел «Компании». В поисковой строке введите название или реквизиты и нажмите
Для примера найдем организацию «Золотое дно».
Рис. 1. Раздел «Компании»
Шаг 2. Получение юридически значимой выписки
Перед вами откроется карточка компании. Вверху окна нажмите на кнопку «Отчеты» и выберите «Выписка с подписью».
Вверху окна нажмите на кнопку «Отчеты» и выберите «Выписка с подписью».
Готовую выписку вы увидите в выплывающем окне внизу карточки. Для получения выписки нажмите кнопку
Рис. 2. Информация о компании
Просмотрите выписку. Если вы все сделали правильно, на последней странице документа будет подпись налоговой службы.
Рис. 3. Подпись ФНС на выписке из ЕГРЮЛ
Выписку можно сохранить или распечатать. Подготовленная выписка хранится в течение одного дня на главной странице программы в разделе «Конфигурации/Система/Длительные операции».
Рис. 4. Сохраненные документы
СТАТЬИ ПО ДАННОЙ ТЕМЕ:
Как получить выписку из ЕГРЮЛ\ЕГРИП в сервисе 1С-Отчетность?
Выписка из ЕГРЮЛ с синей печатью налоговой на бумаге заказать спб
Сколько стоит заказать выписку ЕГРЮЛ с синей печатью налоговой?
Мы можем получить выписку ЕГРЮЛ на абсолютно любую российскую компанию, причем нам не важно, в каком городе компания или индивидуальный предприниматель состоит на налоговом учёте.
Заказать выписку ЕГРЮЛ в СПб — цены услуги 2020 г.
- Срочная выписка ЕГРЮЛ с синей печатью налоговой (за 1 день) — 1 500 р.
- Не срочная выписка ЕГРЮЛ с живой печатью налоговой (за 5 календарных дней) — 1 300 р.
- Доставка по СПб — 400 р.
* Гос. пошлина включена в стоимость!
Те же цены действуют и для получения выписки на индивидуальных предпринимателей (ИП) и крестьянские (фермерские) хозяйства (КФХ).
Для заказа выписки ЕГРЮЛ просто заполните форму заявки, размещенной на этой странице.
Заказать копию устава ООО в СПб — цена услуги
Если вы потеряли или испортили устав компании, то мы можем получить его копию, заверенную налоговой. Такая копия с синей печатью налоговой будет приравниваться к оригиналу!
- Заказать копию устава ООО с синей печатью налоговой (за 1 день) — 1 500 р.

- Заказать копию устава фирмы из налоговой (за 5 календарных дней) — 1 300 р.
- Доставка по Санкт-Петербургу — 400 р.

* Государственная пошлина включена в стоимость!
Какие документы нужны для того, чтобы заказать выписку ЕГРЮЛ на бумажном носителе?
Как уже было написано выше, сведения, содержащиеся в ЕГРЮЛ, являются открытыми и общедоступными, поэтому мы можем получить выписку из ЕГРЮЛ или копию устава на любую организацию от своего имени.
Поэтому не требуется оформлять каких-либо доверенностей!
Всё, что нужно сообщить нам для заказа выписки ЕГРЮЛ — это ОГРН или ИНН компании и ее название. Это можно сделать просто заполнив заявку, размещенную на этой странице.
Так как за получение сведений или документов из ЕГРЮЛ (выписки или устава) необходимо оплачивать гос. пошлину, то при заказе выписки или устава вам нужно будет внести предоплату как минимум 50% стоимости услуги.

Оставшуюся стоимость заказа вы сможете оплатить при получении выписки.
Оплату можно произвести безналичным расчётом с расчетного счета организации или банковской картой физического лица через систему приема платежей на нашем сайте. Подробнее о способах оплаты можно прочитать на этой странице — «Оплата услуг».
Получение выписки из ЕГРЮЛ и ЕГРИП: информация, порядок получения — Инитпро
Единый государственный реестр юридических лиц (ЕГРЮЛ) и Единый государственный реестр индивидуальных предпринимателей (ЕГРИП) являются информационными ресурсами федерального уровня, в которых собраны актуальные сведения обо всех субъектах данных бизнес-сегментов, зарегистрированных на территории России. Содержание сведений, размещенных в реестрах, регламентировано 129-ФЗ.
Какую информацию дает выписка?
Выписки из ЕГРЮЛ и ЕГРИП дают возможность получить информацию о собственной организации, организации конкурента или будущего партнера. Представленные сведения могут касаться даты и места регистрации, размера уставного капитала, видов экономической деятельности, информации о генеральном директоре, а также времени внесения последних изменений в реестр.
Представленные сведения могут касаться даты и места регистрации, размера уставного капитала, видов экономической деятельности, информации о генеральном директоре, а также времени внесения последних изменений в реестр.
Необходимо сказать о той информации, которая в выписке из реестров не предоставляется: это паспортные данные физических лиц и расчетные счета, используемые для уплаты налогов.
Порядок получения
Сама выписка представляет собой электронный документ, заверенный усиленной электронной подписью. Получение выписки является бесплатной процедурой для заявителя, не требующей наличия ЭЦП от него самого. Чтобы получить выписку из указанных реестров через Интернет, необходимо проделать следующие шаги:
- Зарегистрироваться на портале ФНС;
- Пройти активацию своего аккаунта, указав имя и фамилию;
- Отправить заявку на получение выписки, указав ОГРН или ОГРНИП интересующего субъекта;
- Проверить состояние заявки в соответствующем разделе;
- После появления статуса «Заявка сформирована», скачать документ.

Закономерным является вопрос о том, как получить выписку, не имя данных об ОГРН и ОГРНИП юридического лица или индивидуального предпринимателя. Эти данные можно получить также на портале ФНС в разделе «Сведений о государственной регистрации юридических лиц, ИП и фермерских хозяйств». Параметрами поиска могут быть наименование организации юридического лица или место его нахождения; для поиска ОГРН ИП достаточно ввести его личный ИНН, фамилию и регион места жительства.
Имеет ли такая выписка юридическую силу?
Можно ли говорить о юридической значимости выписки, полученной путем личного запроса через Интернет? На этот вопрос можно дать однозначный отрицательный ответ: единственное назначение такого документа – это предоставление информации заявителю. Юридически значимая выписка из ЕГРЮЛ и ЕГРИП выдается только налоговой инспекцией с печатью учреждения.
Как использовать извлечение банковских выписок — банк квитанций
Вместо того, чтобы вручную копировать каждую строку банковских выписок ваших клиентов в их бухгалтерское программное обеспечение, вы можете использовать Receipt Bank для автоматического извлечения данных из банковской выписки .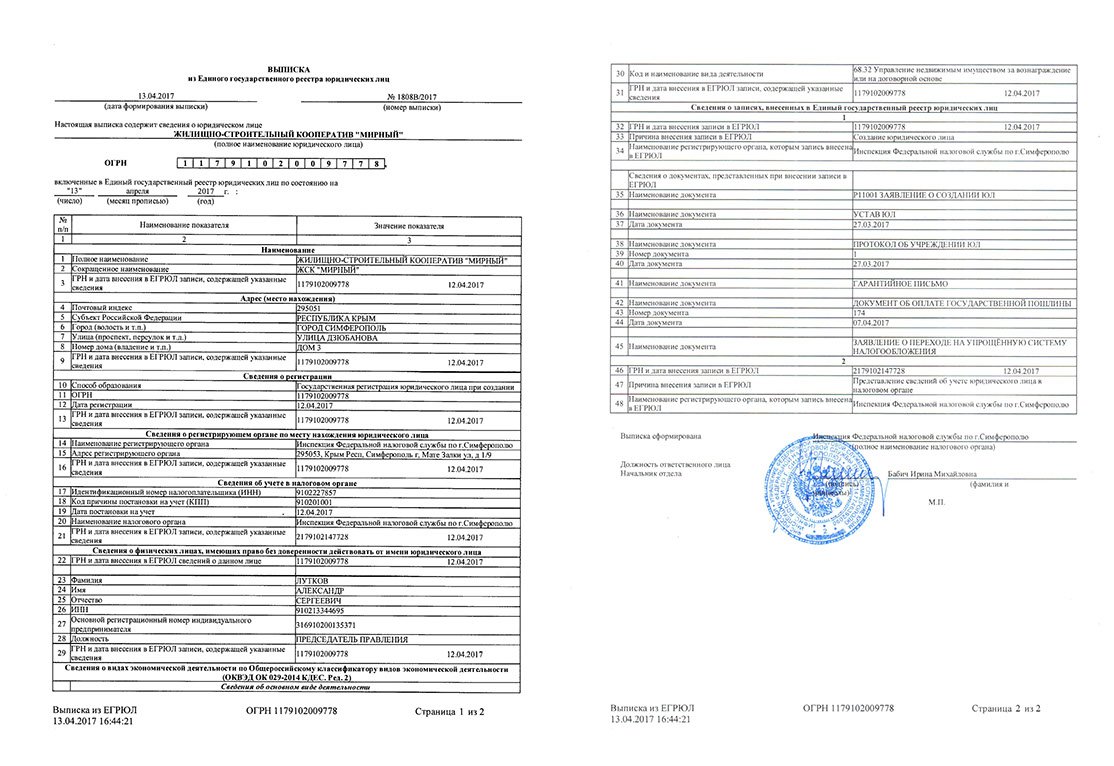 pdf и представления их в электронной таблице или в формате загрузки .CSV. Этот процесс может занять до 2 рабочих дней.
pdf и представления их в электронной таблице или в формате загрузки .CSV. Этот процесс может занять до 2 рабочих дней.
Как подать банковскую выписку на обработку:
1. Убедитесь, что вы настроили банковский счет для выписки, которую хотите загрузить.2. Щелкните раздел Bank в меню
3. Раздел «Банк» разделен на 3 страницы: «Собранные отчеты», «Обработанные отчеты» и «Транзакции». Вы можете добавлять банковские выписки как на страницах «Собранные выписки», так и на страницах «Обработанные выписки».
4. Нажмите зеленую кнопку «Добавить банковские выписки» и следуйте инструкциям
ПРИМЕЧАНИЕ:- Банковские выписки с нескольких счетов не следует добавлять вместе в один файл загрузки.
- Файл не должен содержать изображений выписок, снятых камерой. Только сканы или оригинальные цифровые копии.
- Файл не должен состоять из данных из нескольких источников (например, половина страниц — это сканированные копии почтовых копий, а половина — загружаемые в Интернете. Или структура данных несовместима).
- В выписке не должно быть чрезмерного количества рукописного текста в числовых столбцах. Обычно принимаются отметки и нечастые аннотации.
- Список поддерживаемых банков можно найти здесь

4. После загрузки выписки по счету она будет доступна для просмотра на вкладке Собранные выписки на странице Банк . Загруженные банковские выписки автоматически добавляются в очередь обработки, во время которой будут извлечены все связанные данные банковской выписки. Этот процесс может занять до 2 рабочих дней.
Как загрузить данные банковской выписки:
1. Когда загруженные банковские выписки завершат процесс извлечения, они будут перемещены на вкладку Processed на странице Bank .
2. Вы можете загрузить данные Выписки по счету из вкладки Транзакции , нажав кнопку Загрузить . Вы можете загрузить исходную выписку из банка, которая была загружена в банк квитанций, щелкнув гиперссылку в столбце Source ID . После выбора банковской выписки для загрузки выберите Диапазон дат , , а затем выберите формат загрузки для банковских выписок.
ПРИМЕЧАНИЕ: Вы можете выбирать между различными форматами файлов для загрузки данных банковской выписки.Перейдите в раздел- Стандартный банк квитанций Excel : файл .xlsx по умолчанию со всеми извлеченными данными
- Xero CSV : формат файла, оптимизированный для загрузки в Xero
- QuickBooks Online CSV : формат файла, оптимизированный для загрузки в Quickbooks Online
- Sage 50 UK CSV : формат файла, оптимизированный для загрузки в Sage 50 (только для Великобритании)
 Это позволит повторно отправить банковскую выписку для извлечения без дополнительной оплаты.
Это позволит повторно отправить банковскую выписку для извлечения без дополнительной оплаты.
машинное обучение — Какой алгоритм использовать для извлечения информации из банковских выписок
Я получил хорошие результаты, рассматривая этот вопрос как проблему классификации с использованием вложений (перчатка 50 для встраивания слов) и двунаправленного LSTM. Я знаю, что эта проблема больше похожа на проблему с распознаванием сущностей, но в моем случае использования мне нужно только классифицировать известное подмножество продавцов, поэтому она работает хорошо. Поскольку обучающие данные были очень несбалансированными, я также использовал синтез данных для повышения точности.
Модель My Keras:
__________________________________________________________________________________________________ Слой (тип) Параметр формы вывода # Подключен к ================================================== ================================================ words_input (InputLayer) (Нет, Нет) 0 __________________________________________________________________________________________________ casing_input (InputLayer) (Нет, Нет) 0 __________________________________________________________________________________________________ embedding_1 (Встраивание) (Нет, Нет, 50) 20000000 слов_ввод [0] [0] __________________________________________________________________________________________________ embedding_2 (Встраивание) (Нет, Нет, 9) 81 casing_input [0] [0] __________________________________________________________________________________________________ concatenate_1 (Concatenate) (Нет, Нет, 59) 0 встраивание_1 [0] [0] embedding_2 [0] [0] __________________________________________________________________________________________________ двунаправленный_1 (Двунаправленный) [(Нет, 400), (Нет, 416000 concatenate_1 [0] [0] __________________________________________________________________________________________________ плотный_1 (плотный) (нет, 1591) 637991 двунаправленный_1 [0] [0] ================================================== ================================================ Всего параметров: 21 054 072 обучаемых параметров: 1053 991 необучаемых параметров: 20 000 081 __________________________________________________________________________________________________
Как я могу автоматизировать извлечение данных из сложных документов?
Бизнес-процессы, подпитываемые сложными документами, несутся.
НЕТ !! Не , что тип медведя …. Это тип медведя!
Почему?
Комплексные документы .
Там, где сложные документы могут замедлить работу, сложные документы лишают продуктивность жизни.
Конечно, у вас может быть система оптического распознавания текста , которая обрабатывает ваши документы.
И OCR — хорошая технология … для структурированных документов. Но как насчет этих сложных неструктурированных документов?
Или, черт возьми, вы все еще вручную обрабатываете свои документы. Старые добрые человеческие усилия — это проверенный и верный способ ввести документ в систему, которая управляет вашим бизнес-процессом. Человек может даже найти нужные данные в море сложных данных. В конце концов.
Но люди медлительны, подвержены ошибкам, непоследовательны и дороги. (А в некоторых случаях, возможно, все-таки не так уж и хорошо!)
(А в некоторых случаях, возможно, все-таки не так уж и хорошо!)
Тогда есть все проблемы.
Комплексных документов:
- Может иметь несколько форматов
- Невозможно принудительно вставить в шаблон
- Может быть сыпучим
- Могут быть столы … или хуже! Вложенные таблицы!
- Может содержать изображения
- Может включать рукописный ввод… или хуже! Грязный почерк!
- [ЗАПОЛНИТЕ СВОЮ ЛЮБИМУЮ БОЛЬЮ ОТ ЭКСТРАКЦИИ ЗДЕСЬ!]
Худшая часть? Системы оптического распознавания текста определенно упираются в стену, когда документы становятся слишком сложными.
Так много об автоматизации, правда?
(Увы, читатель … есть надежда.)
Что такое документо-ориентированный рабочий процесс ?
В своей простейшей форме документо-ориентированный рабочий процесс — это процесс, который выполняет бизнес-процесс. Практически во всех случаях документы подпитывают процесс, который включает в себя захват содержимого, извлечение информации из содержимого и выполнение определенных действий на основе этой информации.
Практически во всех случаях документы подпитывают процесс, который включает в себя захват содержимого, извлечение информации из содержимого и выполнение определенных действий на основе этой информации.
Например, вот процесс подачи документов, который, вероятно, звучит знакомо….
Я отправляю медицинские расходы в свою медицинскую страховку, чтобы получить возмещение. Мне нужно:
- Копировать квитанцию
- Распечатать формы
- Заполните формы
- Получить конверт и печать
- Выяснить адрес
- По почте
И это только мой конец.
В сценариях использования рабочих процессов, ориентированных на процессы, контент содержит данные и информацию, которые контекстуально важны для процесса и бизнеса.
Контент, который мы все используем, имеет ценность…значение, которое сложно выпустить.
Классификация документов
Документы можно разделить на различные формы и типы. Документы могут быть изображениями, текстом, числами, видео или разными типами.
Документы могут быть изображениями, текстом, числами, видео или разными типами.
Классификация может быть основана на любом количестве вещей, в том числе:
- Изображения
- Электронная почта
- Текст
- SMS
- Годовые отчеты
- Квитанции
- Счета
- Выписки с банковского счета
- Марки
- Формы ACORD
- Претензии
- Рукописные бланки
- Коммунальные платежи
- Электрощит
- И многое другое!
Извлечение данных
Информация, содержащаяся в документах, может быть извлечена с помощью ручного процесса, OCR или какой-либо другой технологии.Решая, какой из них использовать, важно знать, можем ли мы извлечь всю информацию из документа и насколько точна эта информация.
Затем извлеченные данные и информация вводятся в процесс. Подумайте об обработке ипотечных кредитов, обработке маршрута, обработке ссуд, обработке требований, обработке ответов на запрос предложений, финансовом соответствии, аудите, управлении расходами, обработке счетов-фактур и т. Д.
Д.
Вероятно, вы уже какое-то время выполняли процессы, требующие извлечения данных.Если вы похожи на большинство, вы столкнулись с препятствиями. И из-за этих препятствий ваши планы автоматизации застопорились.
Виновник? Вероятно, это сложные данные.
Как узнать, мешают ли ваши сложные данные вашим целям автоматизации?
Есть веская причина для большей автоматизации процессов, где это возможно. 10-кратное повышение эффективности, производительности и / или экономии средств звучит невероятно, не так ли ?!
Если ваша цель — автоматизировать больше этих процессов с подачей документов, которые теперь требуют людей для ввода данных…или те, с которыми OCR не может справиться, как вы диагностируете проблему, чтобы достичь своих целей?
И как узнать, когда сложные данные создают узкое место в процессе?
Сложность ваших данных, вероятно, указывает на уровень сложности, с которым вы столкнетесь при попытке извлечь данные и сделать из них выводы.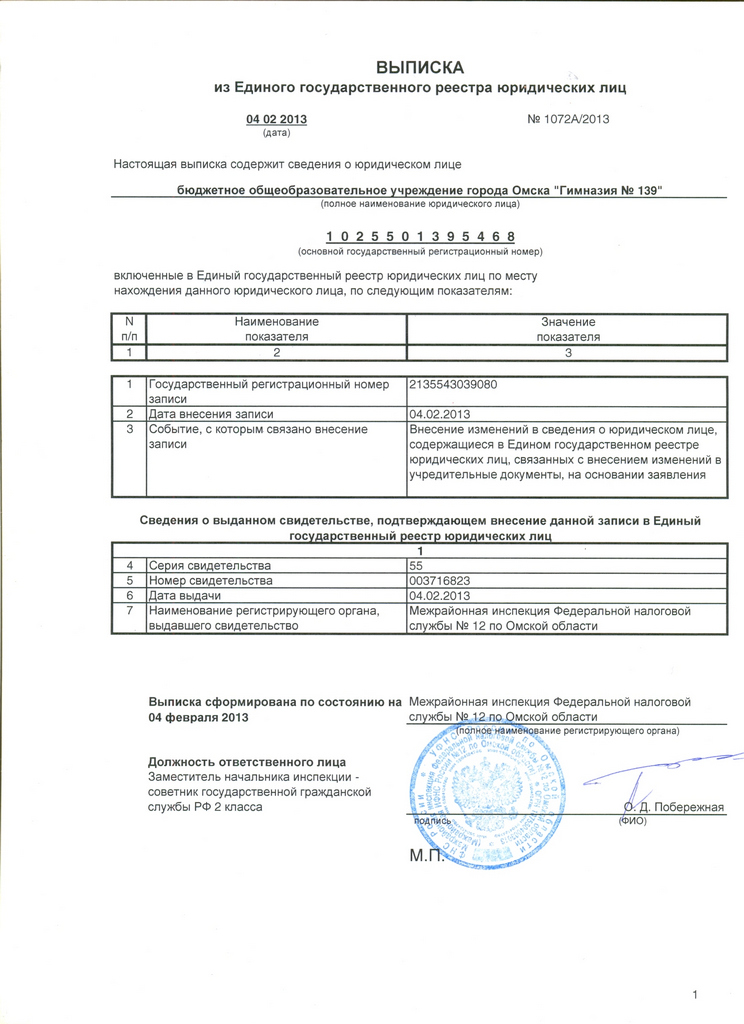
Какие факторы усложняют обработку документов?
- Содержимое свободно текущее
- Документ неструктурированный
- Содержит почерк
- Состоит из нескольких типов документов
- Изменение форматов в том же документе
- Шрифты меняются в том же документе
- Документ содержит сложные таблицы
- Таблицы в разных местах
- Информация отсутствует
- Фотографии и изображения есть в наличии
Это типы документов, для которых не удается OCR, а ручная обработка становится слишком сложной.
Каков бизнес-результат сложных документов?
Когда у вас есть сложные документы, которые нельзя автоматизировать, страдает ваш бизнес.
Как это выглядит?
- Высокие эксплуатационные расходы
- Низкая эффективность процесса
- Длительное время выполнения процесса
- Слишком низкая точность извлечения, чтобы быть полезной
Я думаю, что эти клиенты пришли к выводу, что сказали . ..
..
«Как финансовая компания, наши сотрудники тратят много времени на переписывание счетов.”
А …
«Мы хотим извлечь всю информацию из документов, чтобы мы могли автоматизировать больше процессов и использовать всю информацию для построения аналитических данных. Но наши аналитики используют только 10-20% данных в документах, потому что мы не можем извлечь остальные ».
Решения для комплексной обработки данных
Индустрия эволюционировала от OCR к решениям, использующим несколько технологий искусственного интеллекта для устранения узких мест. Эти решения классифицируются по:
В другом месте вы узнаете, как технология ИИ применяется для решения проблем с неструктурированными данными.Будьте здесь осторожны; ИИ стал модным словом, которое некоторые поставщики используют, чтобы затмить воду, когда дело доходит до описания того, как ИИ играет в их решениях.
На данный момент ключевым моментом является следующее:
Intelligent Data Processing (IDP) может извлекать практически всю информацию, понимать данные и создавать дополнительную ценность из сложных документов.
Три самых распространенных проблемы сложных документов
Infrrd работал рука об руку с сотнями предприятий и компаний для решения сложных проблем с данными.У нас есть чем поделиться. А пока давайте рассмотрим три основных варианта использования, с которыми мы сталкиваемся чаще всего.
Задача 1. Извлечение данных из годовых отчетов
Компания финансовых услуг предоставляет бизнес-ссуды.
Банк предоставляет ссуду и обслуживает ее. Фирмы, которым они ссужают, должны предоставлять финансовые отчеты, чтобы банк мог обеспечить финансовую устойчивость и соблюдение требований.
Довольно просто, правда? Так в чем проблема?
Финансовые отчеты (в данном случае годовые) не имеют универсального стандарта; Обычно они бывают разных форматов, имеют нестандартную таксономию и могут меняться от года к году.Эти отчеты содержат графики, диаграммы и таблицы, которые также противоречивы.
Сложность этих документов требует ручной обработки, поскольку OCR не может обработать документ с такой небольшой структурой. Что хуже? Этот ручной процесс всегда более дорогостоящий, медленный и непоследовательный. Даже самая маленькая ошибка может поставить под сомнение всю финансовую оценку банка.
Что хуже? Этот ручной процесс всегда более дорогостоящий, медленный и непоследовательный. Даже самая маленькая ошибка может поставить под сомнение всю финансовую оценку банка.
Но без информации, содержащейся в этих документах, банк не может определить, насколько хорошо работают фирмы в его кредитном портфеле и почему.А когда информация не доставляется вовремя? Именно тогда банк вводит в свою систему ненужные операционные риски.
Infrrd работал с этим банком для извлечения данных из их сложных документов. Теперь банк использует решение интеллектуальной обработки данных Infrrd, которое применяет многоуровневую последовательность моделей ИИ. Результат? У этого банка больше нет проблем с обработкой годового отчета.
Задача 2. Извлечение данных из чертежей панелей
Чертеж панели — это изображение, которое описывает компоновку и компоненты панели управления, распределительной панели или электрической панели.
В приведенном ниже примере показаны номера деталей и спецификации для компонентов.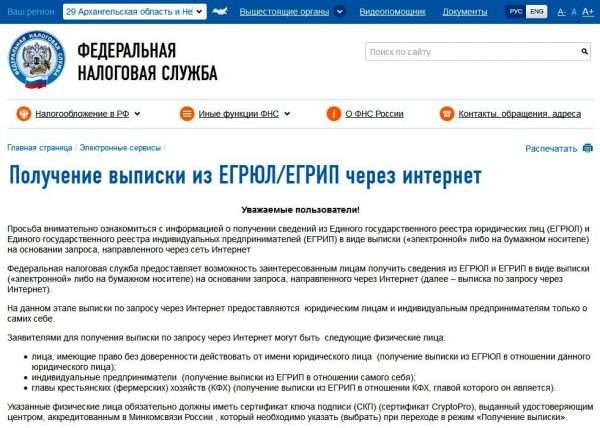
Так как же извлечь полезные данные из этих панелей? Они слишком сложны для этого?
Представьте себе это.
Поставщик получает от застройщика пакет RFP, который включает документы и чертежи панелей. Поставщик должен прочитать чертежи, составить предложение и отправить его строителю. Если у поставщика лучшее предложение, он выигрывает бизнес.
Но когда пакет RFP (документы и множество чертежей панелей) обрабатывается вручную, на создание предложения уходят недели.
Можно ли использовать автоматическое извлечение данных на этих чертежах панелей?
В ходе работы с этим поставщиком мы узнали, что они попробовали OCR … и не смогли.
OCR не может обрабатывать чертежи панелей, потому что не может:
- Определить стиль и толщину линии
- Ориентация текста (верх, низ, сторона чертежа)
- Отличить символы от цифр и букв
Поставщик — после партнерства с Infrrd — узнал, как использовать платформу извлечения информации на базе искусственного интеллекта для решения уникальных задач даже самых сложных чертежей панелей. В результате поставщик автоматизировал процесс запроса предложений. Сегодня они отвечают строителям, которых обслуживают в 20 раз быстрее и точнее.
В результате поставщик автоматизировал процесс запроса предложений. Сегодня они отвечают строителям, которых обслуживают в 20 раз быстрее и точнее.
Вопреки распространенному мнению, ДА. Вы можете автоматизировать извлечение данных из чертежей панелей.
Задача 3. Извлечение данных из таблиц
Столы везде. Вы найдете их в годовых отчетах, финансовых отчетах, счетах, счетах, квитанциях и управленческих отчетах.
Таблицы помогают структурировать информацию, чтобы людям было легче ее понять.
И … столики действительно везде. Скорее всего, они находятся в тех самых документах, которые содержат информацию, которую вы хотите извлечь!
Самая большая проблема с таблицами проявляется по мере увеличения сложности. Вот как это выглядит:
- Таблицы не отображаются в одном месте в отчетах
- Шрифты различаются в одной таблице
- В таблице цифры и буквы
- Таблицы отображаются с рамками и без них
- Вы найдете таблицы внутри таблиц (вложенные таблицы)
- Таблицы занимают десятки или даже сотни страниц
Ручная обработка таблиц может работать в случае простой таблицы с ограниченными строками и столбцами. Но когда таблицы занимают много страниц, любой, кто читает данные, может совершить ошибку.
Но когда таблицы занимают много страниц, любой, кто читает данные, может совершить ошибку.
Как вы уже догадались, с OCR бросают вызов и таблицы. Когда таблица без границ, как показано ниже, OCR не может идентифицировать информацию как таблицу … и, конечно же, тип таблицы.
OCR также не работает, когда ему нужно определить, является ли запись нулем или «O».
Infrrd и наши клиенты уже давно успешно извлекают данные из таблиц. Чтобы последовательно делать все правильно, требуется иной образ мышления и подход, полностью отличный от OCR.
Сбрасывая бомбы знаний при извлечении информации
В этом блоге вы узнали некоторые основы извлечения данных из сложных документов.
Помните три сложных варианта использования (годовые отчеты, панели и таблицы)? Большинство людей, которые испытывают это, в отчаянии разводят руками… и уходят. Они никогда не осознают истинную ценность, заключенную в их документах!
Можете ли вы извлечь полную ценность данных и информации из сложных документов?
ДА. ТЫ. МОЧЬ.
ТЫ. МОЧЬ.
Изучите наши сообщения в блоге, чтобы узнать, как решить каждую из этих проблем с неструктурированными данными.
Обсудим все подробнее.
И вы увидите, как заставить технологии искусственного интеллекта работать на вас.
Вы станете мастером комплексного извлечения данных в своей организации. И ангелы автоматизации будут хором петь твое имя.
Но берегитесь! Будут тесты, и тебе придется надеть эту мыслящую шапку!
А пока задумайтесь над этим: чего еще мы могли бы достичь, если бы могли извлекать все данные и информацию из всех наших сложных документов?
Ответ на этот вопрос, вероятно, поразит вас.
До следующего раза … если вы не хотите поболтать с экспертом сейчас:
Извлечение данных из финансовых PDF-файлов | Даулет Нурманбетов
Как быстро извлекать текст и данные из отчетов CAFR по муниципальным облигациям
Фото Маркуса Списке на UnsplashЧто распространяется
Большая часть финансовых ресурсов уходит на написание и чтение финансовой отчетности. В США, чтобы финансовый отчет считался официальным, он должен быть в формате PDF.Это создает проблемы позже, когда файлы PDF становятся машиночитаемыми.
В США, чтобы финансовый отчет считался официальным, он должен быть в формате PDF.Это создает проблемы позже, когда файлы PDF становятся машиночитаемыми.
Раньше банки и финансовые организации нанимали целые команды людей для чтения финансовых отчетов в формате PDF и ввода их в базы данных банка. Эти позиции были вводом данных, вводом формы. Тем не менее, другие команды сопоставляли введенные значения с теми, которые обычно используются банком. Эти задачи называются финансовым распределением.
Например, большая семейная ферма, подающая заявку на ссуду, должна перечислить такие предметы, как грузовик Peterbilt, в своем инвентаре фермы.Но когда распространитель в банке читает финансовые отчеты, им нужно будет отнести грузовик (-ы) к категории долгосрочных (не валютных) активов в подкатегории — транспортное средство. Это позволяет банку снизить финансовую неопределенность, поскольку он может сопоставить этот конкретный грузовик с другими аналогичными автомобилями, с которыми банк имел дело в течение многих лет. Говоря языком финансов, он позволяет банку сопоставить это событие с более широким стандартизированным набором счетов.
Говоря языком финансов, он позволяет банку сопоставить это событие с более широким стандартизированным набором счетов.
В недалеком прошлом эти разбрасыватели располагались в недорогих районах и на море.Сегодня многие финансовые учреждения в той или иной форме внедрили ИИ, чтобы уменьшить человеческое бремя чтения каждого финансового PDF-файла вручную.
Давайте обсудим, как ИИ читает и обрабатывает эти PDF-файлы.
Распаковка PDF с помощью машины
Мы рассмотрим Комплексные годовые финансовые отчеты (CAFR), которые являются основным ежегодным документом, раскрывающим информацию по муниципальным облигациям. CAFR — это преимущественно отсканированные документы в формате PDF. Вот пример CAFR для города Нью-Йорк.
Большинство городов США имеют непогашенные облигации и обязаны раскрывать годовую финансовую отчетность через CAFR. Вот хороший слайд об общем размере Muni и охвате CAFR. Давайте посмотрим на образец страницы из CAFR, мы будем использовать его для выполнения извлечения данных оптического распознавания символов (OCR) —
CAFR из города Хобокен, штат Нью-Джерси, страница 150 Если вы посмотрите внимательно, вы заметите это отсканированная страница, которая была сохранена в формате PDF, поэтому пока не может быть прочитана машиной.
Документы CAFR содержат очень интересную информацию о планировании, составлении бюджета и деятельности муниципалитета, такого как город.Они содержат информацию о государственных школах, полицейских управлениях, пожарных частях. Такие вещи, как количество больничных коек в финансируемой государством больнице, доход на больничную койку и другие операционные расходы.
Что происходит под капотом
Итак, как ИИ может сделать документ поверх машиночитаемого текста?
По сути, ИИ пытается изолировать области с черными пятнами от областей, на которых их нет. Затем другой ИИ, как школьник, смотрит на отдельные чернильные пятна, чтобы различить слова и символы.И еще один ИИ пытается понять, организован ли весь обнаруженный текст в виде таблицы, формы или текста произвольной формы.
В частности, PDF-файл считывается машиной как изображение. Затем алгоритм пытается нарисовать рамкой любой текст, который он видит. Каждое слово или группа символов получит свою коробку. Как только алгоритм покрывает каждый фрагмент текста в ограничивающей рамке, можно переходить к следующему набору алгоритмов. Вот как выглядят ограничивающие прямоугольники —
Как только алгоритм покрывает каждый фрагмент текста в ограничивающей рамке, можно переходить к следующему набору алгоритмов. Вот как выглядят ограничивающие прямоугольники —
Затем задействуется другой алгоритм — оптическое распознавание символов (OCR) для декодирования текста внутри каждого ограничивающего прямоугольника.Этот алгоритм принимает изображения текста и преобразует их в понятный для компьютера текст, содержащийся в этом изображении.
И, наконец, другой алгоритм просматривает все эти ограничивающие прямоугольники и текст в них, чтобы понять, образует ли каждое слово строку или часть таблицы.
Например, в верхней строке написано «CITY OF HOBOKEN», алгоритм ограничивающей рамки обнаружил 3 области с текстом — «CITY», «OF», «HOBOKEN» и присвоил им оценки достоверности и уникальные идентификаторы —
Затем Консолидатор алгоритм берет выходные данные из 3 отдельных слов и группирует их вместе в зависимости от расположения этого текста на странице —
Доверие к уведомлению: 95 текста: «CITY OF HOBOKEN» Этот последний алгоритм консолидации также классифицирует области страницы, которые являются таблица, текст произвольной формы или форма. Вот как это выглядит вместе —
Вот как это выглядит вместе —
Сегодня каждый упомянутый выше алгоритм представляет собой глубокую нейронную сеть, которая была обучена с отдельными данными обучения и аннотирована людьми. И мы видим оценки достоверности на каждом этапе пути, поэтому мы можем исправить алгоритм с помощью активного обучения.
Если вы заинтересованы в настройке сквозного OCR-as-a-service на AWS, см. Здесь.
Заключение
Благодаря последним достижениям в области искусственного интеллекта мы теперь можем читать PDF-документы в массовом порядке в наши озера данных и выполнять последующее машинное обучение и аналитику для обнаружения альфа-версии.
Новые стартапы появляются, чтобы почерпнуть идеи из массы документов в финансовом секторе, которые в прошлом были непомерно дорогими.
OCR — это лишь небольшая, но важная часть того, как финансовые документы принимаются, обрабатываются и отображаются для профессионалов в области инвестиций, чтобы получить денежное преимущество (альфа).
Извлечение данных бухгалтерского учета с помощью искусственного интеллекта
Большинство бухгалтеров и бухгалтеров задают вопрос, как можно извлекать данные с помощью искусственного интеллекта или машинного обучения, а не только с помощью методов извлечения данных / распознавания текста.
Сценарий прост. Вы бухгалтер или бухгалтер , и вы можете работать в компании, которая предлагает бухгалтерские или бухгалтерские услуги на аутсорсинге, или во внутренней финансовой группе в компании. Неважно.
Важно то, ведете ли вы учет по кассовому методу или по методу начисления. Если вы ведете кассовый учет, то в первую очередь вы создаете бухгалтерские проводки либо из банковских выписок, либо из выписок по кредитной карте.Это означает, что у вас нет огромного количества документации, из которой вам нужно обрабатывать бухгалтерские записи.
Однако, если вы ведете учет на основе начисления , вам необходимо просмотреть каждый документ. (А иногда сначала нужно согласовать группы документов) .
(А иногда сначала нужно согласовать группы документов) .
Затем составьте бухгалтерскую проводку по каждому из этих документов.
Таким образом, вы можете либо выполнить этот процесс извлечения данных вручную, либо использовать различные доступные технологии, которые помогут вам в этом.
Искусственный интеллект при извлечении данных — сбивающий с толку термин
Существует так много информации и дезинформации об извлечении данных с использованием ИИ. Если вы выполните пару поисков в Google, вы найдете такие статьи, как:
- извлечение данных из документов
- извлечение AI
- интеллектуальное извлечение данных
- документ AI
- глубокое обучение для извлечения данных
- AI ввод данных
Действительно запутанно, не правда ли!
Даже несмотря на то, что искусственный интеллект, машинное обучение и другие технологии продаются вместе с другими технологиями бухгалтерского учета и бухгалтерского учета, это все еще вызывает сильную путаницу, поскольку люди не уверены в различиях между различными технологиями или в том, как они могут помочь им автоматизировать учет.
Чтобы усложнить ситуацию, некоторые компании используют действительно базовые технологии вместе с людьми в фоновом режиме, а некоторые компании используют технологии.
Идея этой статьи состоит в том, чтобы попытаться дать вам ясность в отношении различных вариантов. А также то, как DOKKA подходит к проблеме.
Что такое OCR в бухгалтерии
Прежде чем мы перейдем к более продвинутым технологиям, таким как искусственный интеллект и машинное обучение, важно понять основы.Таким образом вы сможете узнать, как извлекать бухгалтерские данные с помощью искусственного интеллекта.
OCR существует уже много лет и определяется в Википедии следующим образом:
Оптическое распознавание символов или оптический считыватель символов — это электронное или механическое преобразование изображений печатного, рукописного или напечатанного текста в машинно-кодированный текст, будь то из отсканированного документа, фотографии документа, фотографии сцены или из текста субтитров.
 накладывается на изображение.
накладывается на изображение.Извлечение данных OCR относительно хорошо работает для англоязычных документов, если документация ясна, а необходимая информация содержится в документе.
Существует множество различных сервисов, предлагающих извлечение данных OCR, некоторые хорошие, а некоторые прямо противоположные.
А как насчет OCR на языках, не говорящих по-английски?
OCR на языках, отличных от английского, по-прежнему не работает, особенно если буквы не используют латинский или латинский алфавит.
Подумайте о таком языке, как иврит, где под буквами стоит много разных точек. Он сильно отличается от английских букв или цифр.
Сегодняшние технологии меняют способ ведения бухгалтерского учета и обработки данных. Раньше бухгалтерские записи создавались вручную из исходной документации. Сегодня, благодаря сочетанию технологии извлечения данных / распознавания текста, машинного обучения и искусственного интеллекта, бухгалтеры во всем мире полагаются на автоматизированный учет. И часть автоматизированного учета — возможность извлекать данные бухгалтерского учета с помощью искусственного интеллекта.
И часть автоматизированного учета — возможность извлекать данные бухгалтерского учета с помощью искусственного интеллекта.Есть технология, которая может обслуживать разные языки. Однако, вообще говоря, OCR для извлечения данных не на английском языке (и особенно для нелатинского или римского алфавита) по-прежнему не работает так же, как Извлечение данных OCR для английского языка.
А как насчет извлечения данных с помощью рукописного ввода?
Мои коллеги всегда шутят и говорят, что предприниматель, который успешно создаст технологическое решение, способное преобразовывать рукописный текст в цифровой формат с высокой степенью точности, будет иметь бизнес на миллиард долларов.
Если вы попробуете какое-либо программное решение для извлечения рукописного текста, вы обнаружите, что иногда оно работает лучше, чем в других случаях. Это зависит от множества факторов, начиная от качества изображения, из которого вы пытаетесь извлечь, но, в частности, от стиля почерка и аккуратности.
Так мне просто выбрать программу для извлечения данных для моих бухгалтерских нужд?
Все не так просто. Когда вы хотите извлечь данные из финансовой документации, в частности, чтобы создать бухгалтерскую запись, следует учитывать ряд соображений:
- Все ли извлечение данных осуществляется с помощью технологии , или есть люди, участвующие в фоновом режиме?
- Как насчет частей бухгалтерской записи , с которыми извлечение данных не поможет?Где вам понадобится больше, чем OCR?
Вторая часть посвящена извлечению бухгалтерских данных с помощью искусственного интеллекта. Однако, как мы увидим, не всегда используется ИИ. Иногда это другая технология.
Однако, как мы увидим, не всегда используется ИИ. Иногда это другая технология.
Давайте посмотрим на эти 2 соображения по извлечению данных, которые бухгалтеры и бухгалтеры должны принять во внимание.
Извлекаются ли ваши данные с помощью технологий?
Это так интересно. Есть компании, которые предоставляют технологии извлечения данных с использованием чистой технологии.Есть также компании, которые предоставляют технологии извлечения данных, используя людей в качестве «технологий».
Часто эти люди приезжают из более бедных стран, где стоимость рабочей силы дешевле, чем в вашей стране. Итак, вы вводите финансовый документ для извлечения данных , и когда вы его просматриваете, кажется, что извлечение данных было выполнено правильно. Но на самом деле это было сделано не с помощью технологических решений. На самом деле люди обрабатывали его вручную.
Часто эти люди приезжают из более бедных стран, где стоимость рабочей силы дешевле, чем в вашей стране.

Одна из основных проблем, связанных с этим, заключается в том, что люди на другом конце света видят вашу конфиденциальную информацию или конфиденциальную информацию ваших клиентов .
Год назад была ситуация, когда в горячую воду попала крупная компания по управлению расходами. Выяснилось, что они использовали «Механический турок» для обработки большого количества данных из квитанций о расходах. Вместо того, чтобы использовать технологии.
Еще один пример, с которым мы столкнулись, — это когда потенциальный клиент упомянул, что DOKKA не смогла правильно автоматизировать извлечение данных из чаевых в квитанциях о расходах при посещении ресторана .
Я не говорю о случаях, когда есть общая сумма, затем человек вводит сумму чаевых, а затем человек аккуратно вводит общую сумму в конце. Итак, есть сумма до чаевых, сумма чаевых и сумма после чаевых. DOKKA часто справляется с подобными ситуациями.
Я имею в виду общую сумму, включая чаевые, которые были «нацарапаны» где-то в квитанции о расходах, и «решение для извлечения технологических данных» смогло понять, что эта нацарапанная сумма была окончательной суммой и включала чаевые.Это не технология! Это люди.
Итак, как узнать, вовлечены ли люди в процесс извлечения данных?
Лучший способ быстро определить, является ли решение по извлечению технологических данных чисто технологическим или участвуют ли люди в процессе, — это посмотреть, сколько времени требуется, чтобы получить решение. Если это займет пару секунд или меньше минуты или двух, то это почти гарантированно будет технологическим решением для извлечения данных.
Загрузите финансовый документ и посмотрите, нужно ли ждать от нескольких минут до одного дня или больше.Если да, то есть большая вероятность, что за извлечением данных стоят люди.
Практическое правило гласит, что меньше минуты — это технология, а все, что длиннее нескольких минут, вероятно, — люди ( или люди в сочетании с технологиями ). Или в настоящее время возникает проблема с технологией чистого извлечения данных. Так что загрузите пару документов в течение нескольких дней, и вы сами узнаете, какой тип решения для извлечения данных используется.
Или в настоящее время возникает проблема с технологией чистого извлечения данных. Так что загрузите пару документов в течение нескольких дней, и вы сами узнаете, какой тип решения для извлечения данных используется.
Рекомендации по бухгалтерским проводкам в дополнение к извлечению данных
Бухгалтерские проводки — это не просто извлечение суммы, даты и НДС / GST / налога с продаж из расходной квитанции.
Как насчет счета главной книги , которому должен быть присвоен финансовый документ ? На самом деле, что насчет того, если суммы или суммы в финансовом документе должны быть распределены по нескольким счетам.
Итак, у вас есть счет за электроэнергию для вашей компании, и вы по какой-то причине хотите разделить 80% на электричество и 20% на другой счет главной книги.
Что с описанием? Если вы просто хотите записывать электричество каждый месяц, это одно, но что, если вы хотите, чтобы в описании было больше деталей?
Финансовый документ уже оплачен? Если да, то какой банковский счет или кредитную карту следует отнести к ? А если не платят?
При создании бухгалтерской записи необходимо учитывать множество других факторов, помимо фактического извлечения данных.
Мой лучший пример — название продавца.Когда бы я ни разговаривал с клиентами, у них всегда возникают проблемы, потому что многие технологии конкурентов извлекают название компании из счета или квитанции. Это часто включает орфографическую ошибку. Или извлекает часть имени, когда оно уже есть в бухгалтерском программном обеспечении с немного другой версией имени поставщика. Результат? В бухгалтерском программном обеспечении существует несколько версий одного и того же поставщика.
Как DOKKA обрабатывает извлечение данных и создание бухгалтерской записи?
DOKKA использует совершенно другой подход к извлечению данных и автоматизированному учету.
После того, как DOKKA получит от вас финансовый документ, будут выполнены следующие действия, чтобы автоматически создать для вас нужную бухгалтерскую запись:
- DOKKA разработала собственную технологию визуального распознавания , которая анализирует структуру финансового документа. Затем он может проанализировать, был ли уже загружен дубликат документа и какой тип документа вы отправили. (счет, расход, кредит-нота, квитанция и т. Д.)
- В течение 7 секунд (, и именно так вы можете видеть, что DOKKA — это исключительно решение для извлечения данных и автоматизированного учета ), мы создаем страницу, показывающую документ вы отправили слева, а предлагаемая бухгалтерская запись справа
- Бухгалтерская запись немного отличается в зависимости от выбранной вами интеграции бухгалтерского программного обеспечения.Вы еще не подключили к DOKKA бухгалтерское программное обеспечение? У нас есть макет по умолчанию? Connected Xero, Zoho, QBO, QBD, SAGE50 или какое-либо другое программное обеспечение для бухгалтерского учета, которое мы поддерживаем? Вы увидите немного разный макет для каждого из них.
- Если вы впервые представляете этого конкретного поставщика, DOKKA предпримет образованную попытку «машинного обучения / искусственного интеллекта», чтобы понять ваши конкретные требования к этой бухгалтерской записи для этого поставщика для этого клиента. Какая ставка НДС / НДС / налога с продаж? Если он оплачен, на какой банковский счет или кредитную карту он должен пойти? Какой ссылочный номер правильный, если в документе есть несколько возможных ссылочных номеров? К какому счету или счетам главной книги его следует отнести? Обычно DOKKA для попытки 1 st будет очень точной, но вам может потребоваться немного подправить бухгалтерскую запись.
- Настроить бухгалтерскую запись в DOKKA очень просто. Вы можете настроить учетную запись вручную, но еще проще использовать наш метод корректировки бухгалтерского учета «перетаскиванием».Просто найдите нужный ссылочный номер в документе и перетащите его в бухгалтерскую запись. Найдите в документе нужную сумму и перетащите ее в бухгалтерскую запись. Перетащите нужную дату и перетащите ее в бухгалтерскую запись.
- Если это 2 и раз, когда вы получили этого конкретного поставщика или поставщика, тогда DOKKA уже будет знать, каковы ваши конкретные требования к этому документу, и представит вам правильную бухгалтерскую запись .
- Взгляните на документ, посмотрите на бухгалтерскую запись и нажмите «утвердить».Это оно. Если вы интегрировали DOKKA с Xero, QBO, QBD, SAGE50, Zoho или одним из других наших интегрированных программных решений для бухгалтерского учета, бухгалтерская запись вводится в бухгалтерское программное обеспечение в реальном времени. ( и в большинстве случаев также копия документа ). У вас нет бухгалтерского программного обеспечения? Вы можете загрузить утвержденную бухгалтерскую запись в формате CSV или Excel в любое время.
 Затем он может проанализировать, был ли уже загружен дубликат документа и какой тип документа вы отправили. (счет, расход, кредит-нота, квитанция и т. Д.)
Затем он может проанализировать, был ли уже загружен дубликат документа и какой тип документа вы отправили. (счет, расход, кредит-нота, квитанция и т. Д.)  Какая ставка НДС / НДС / налога с продаж? Если он оплачен, на какой банковский счет или кредитную карту он должен пойти? Какой ссылочный номер правильный, если в документе есть несколько возможных ссылочных номеров? К какому счету или счетам главной книги его следует отнести? Обычно DOKKA для попытки 1 st будет очень точной, но вам может потребоваться немного подправить бухгалтерскую запись.
Какая ставка НДС / НДС / налога с продаж? Если он оплачен, на какой банковский счет или кредитную карту он должен пойти? Какой ссылочный номер правильный, если в документе есть несколько возможных ссылочных номеров? К какому счету или счетам главной книги его следует отнести? Обычно DOKKA для попытки 1 st будет очень точной, но вам может потребоваться немного подправить бухгалтерскую запись.

Итак, в DOKKA удивительно то, что это НАМНОГО больше, чем просто извлечение данных. Он сочетает извлечение данных с логикой машинного обучения / искусственного интеллекта и объединяет все это с функцией перетаскивания и другими умными методами автоматизации бухгалтерского учета. Таким образом, вам, бухгалтеру, не нужно создавать правила или редактировать правила для обучения системе.
Вместо этого, чем больше вы используете DOKKA, тем лучше он будет автоматически понимать, каковы ваши конкретные бухгалтерские требования для каждого конкретного поставщика в каждой компании, с которой вы работаете.
Заключение: извлечение данных бухгалтерского учета с помощью искусственного интеллекта или машинного обучения для достижения наилучших результатов
Теперь вы знаете, что не всегда извлекаете бухгалтерские данные с помощью искусственного интеллекта. Иногда можно просто извлечь данные без дополнительных аналитических данных. А иногда вы используете искусственный интеллект или другие технологии, например машинное обучение, для достижения желаемых результатов.
Надеюсь, эта статья дала вам некоторое представление об извлечении данных и о том, как работает OCR.Что наиболее важно, даже если компания утверждает, что у нее есть решение для извлечения данных / OCR, которое будет работать на вас, теперь вы знаете, что извлечение данных и OCR — это лишь очень небольшая часть процесса создания правильной бухгалтерской записи, которая требуется для автоматизации. ваш бухгалтерия.
Еженедельная выдержка: 28 сентября 2020 г.
Еженедельная выдержка из Extractable — это сжатый обзор новостей о цифровом опыте для финансовых организаций, а также наш опыт из Сан-Франциско.
На этой неделе мы обсуждаем искусственный интеллект как основу цифровой трансформации банковской системы. Мы охватываем финтех-компании, получившие преимущество во время пандемии. Наконец, мы рассмотрим важность партнерских отношений в сфере финансовых технологий для будущих банковских моделей.
Как стать AI-First Bank McKinsey опубликовала статью, в которой обосновывается, что при цифровой трансформации банковской системы ИИ должен быть центральной трансформирующей технологией. Статья написана партнерами из Мумбаи, Супарна Бисвас, Швайтанг Сингх и Ренни Томас, из Сиднея, Брант Карсон, и из Гонконга, Вайолет Чанг.
Статья написана партнерами из Мумбаи, Супарна Бисвас, Швайтанг Сингх и Ренни Томас, из Сиднея, Брант Карсон, и из Гонконга, Вайолет Чанг.
Авторы подчеркивают, что ИИ «потенциально может приносить до 1 триллиона долларов дополнительной стоимости каждый год» для банковского дела во всем мире. Тем не менее, банки изо всех сил пытались выйти за рамки отдельных вариантов использования из-за «отсутствия четкой стратегии для ИИ, негибкого технологического ядра и нехватки инвестиций, фрагментированных активов данных и устаревших операционных моделей, которые препятствуют сотрудничеству между бизнесом и технологическими группами».
McKinsey призывает банки уделять первоочередное внимание ИИ для решения проблем, меняющих общество и бизнес-модели.
«Чтобы оправдать растущие ожидания клиентов и победить конкурентные угрозы в цифровую эпоху на базе искусственного интеллекта, банк, ориентированный на искусственный интеллект, будет предлагать интеллектуальные предложения и опыт (то есть рекомендовать действия, предвидеть и автоматизировать ключевые решения или задачи), персонализированные (то есть актуальные и своевременные, основанные на подробном понимании прошлого поведения и контекста клиентов) и действительно многоканальные (плавно охватывающие физический и онлайн-контексты на нескольких устройствах и обеспечивающие единообразный опыт) и сочетающие банковские возможности с соответствующими продуктами и услугами помимо банковских. ”
”
Авторы подробно описывают, как может происходить трансформация AI-first. «Чтобы преодолеть проблемы, которые ограничивают развертывание технологий искусственного интеллекта в масштабах всей организации, банки должны применять целостный подход. Чтобы стать ИИ в первую очередь, банки должны инвестировать в трансформацию возможностей на всех четырех уровнях интегрированного стека возможностей… уровне взаимодействия, уровне принятия решений на основе ИИ, уровне базовой технологии и данных, а также операционной модели ».
Амир Хусейн, основатель и генеральный директор SparkCognition и генеральный директор SkyGrid, пишет в Forbes, что три новых сдвига в искусственном интеллекте «начинают материализоваться в форме реальных исследований и приложений.Эти области работы представляют собой темы, которые, я верю, будут записаны как значимые прорывы в будущем графике ключевых разработок в области ИИ ».
- «Стоимость обучения систем машинного обучения резко снизится»
- «Искусственный интеллект будет все шире использоваться для расширения творческих способностей человека и помощи в разработке идей»
- «Предприятия, осознающие потенциал искусственного интеллекта, превзойдут свою конкуренцию»
Хусейн считает, что эти три развития делают будущее ИИ, которое предлагает McKinsey, достижимым в ближайшем будущем.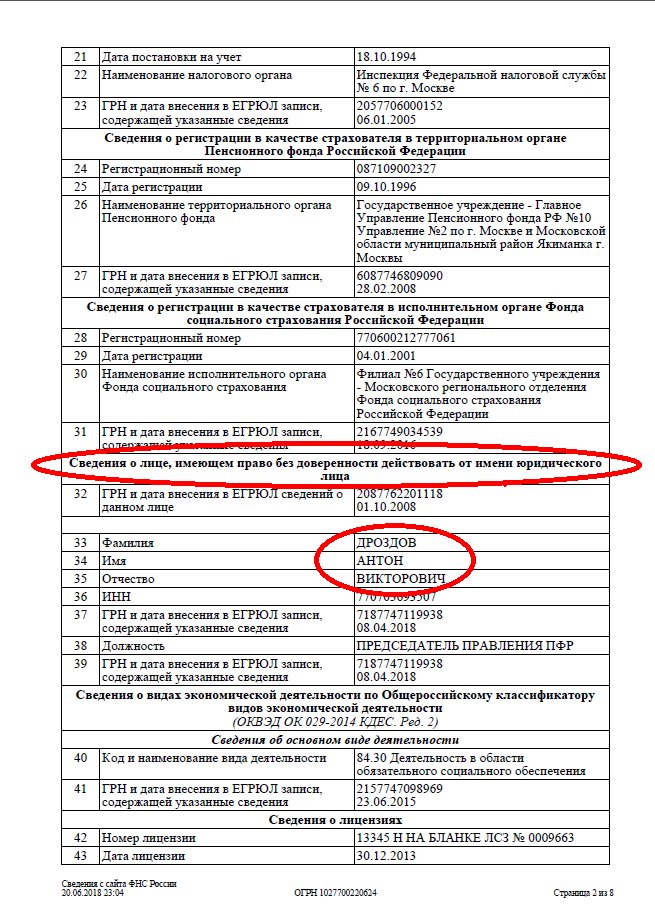 «Каждый процесс, каждый рабочий процесс и каждая задача, которая может быть реализована с помощью ИИ, представляет собой улучшение… неорганическую эволюцию, выходящую за рамки текущего, обычного состояния».
«Каждый процесс, каждый рабочий процесс и каждая задача, которая может быть реализована с помощью ИИ, представляет собой улучшение… неорганическую эволюцию, выходящую за рамки текущего, обычного состояния».
Он добавляет: «Мы можем сделать это практически сейчас, потому что исследования позволяют использовать недорогие методы обучения, которые можно встраивать на периферии, во все более мелкие объекты. Идеи, усиленные ИИ, создают потенциал для рекурсивного самосовершенствования. А внедрение искусственного интеллекта является конкурентной потребностью до такой степени, что оно становится эволюционным фильтром для бизнеса: принимать и развиваться или отрицать и истекать.”
McKinsey создает аргументы в пользу тотальной трансформации, основанной на искусственном интеллекте, а Хусейн изучает возможности даже в ближайшем будущем, и остается только задаться вопросом, какие на самом деле тактики помогут организации продвинуться по пути трансформации. Камила Читил, главный операционный директор MoneyGram, опубликовала в Forbes статью, в которой подробно описываются пять строительных блоков для ускорения цифровой трансформации.
- «Установленные ожидания: цифровые преобразования беспорядочные»
- «Установи ясного собственника, но не помещай его / его на остров»
- «Не оставляйте часть организации, не тронутую цифровыми технологиями»
- «Будьте безжалостно клиентоориентированными»
- «Поддерживайте культуру экспериментов»
В Extractable мы согласны с точкой зрения Chytil.Часто мы работаем с организациями, чтобы согласовать единое видение их трансформации, прежде чем они смогут двигаться вперед. Этот процесс запутан и требует сильного руководства и сосредоточения внимания на потребностях клиентов, а не только на применении технологий.
«Порыв роста» финансовых технологий в условиях пандемии Несомненно, влияние Covid-19 на экономику было и будет тяжелым испытанием для компаний, оказывающих финансовые услуги.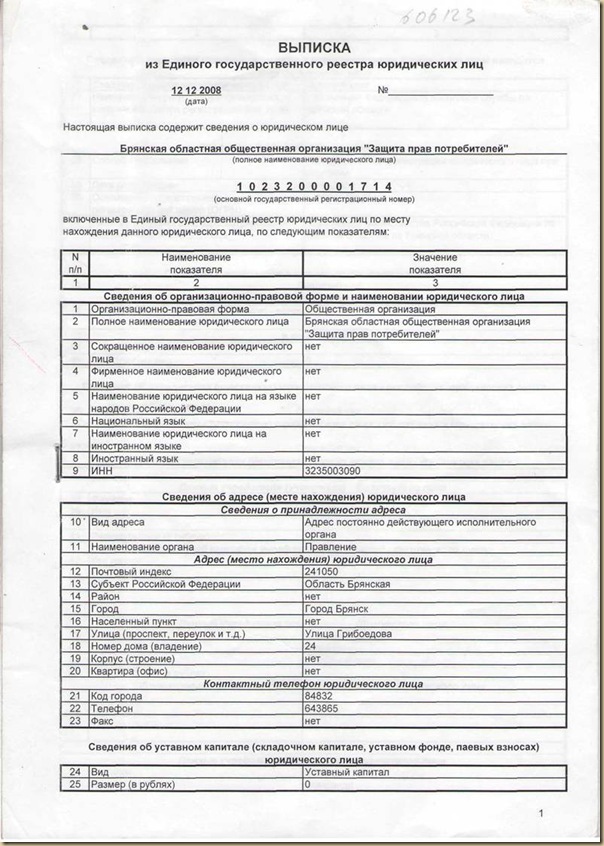 По словам Джеффа Кауфлина и Элизы Хаверсток из Forbes, нынешний спад, вызванный Covid, ударил и по финтех-компаниям.«LendingClub, предлагающий индивидуальные ссуды потребителям с повышенным риском, уволил 30% сотрудников; кредитор малого бизнеса On Deck был продан на распродаже ».
По словам Джеффа Кауфлина и Элизы Хаверсток из Forbes, нынешний спад, вызванный Covid, ударил и по финтех-компаниям.«LendingClub, предлагающий индивидуальные ссуды потребителям с повышенным риском, уволил 30% сотрудников; кредитор малого бизнеса On Deck был продан на распродаже ».
Кауфлин и Хаверсток в статье на Forbes продолжают рассказывать о связанных с платежами финтех-фирмах и учредителях, которые, тем не менее, извлекли выгоду из роста цифровых платежей, вызванного карантином. Пишут:
«для значительной части финтех-компаний, ориентированных на потребителей и связанных с платежами, вирус вызвал бурный рост, как и гигант электронной коммерции Amazon и Zoom, Slack и DocuSign, работающие из дома.”
Кауфлин и Хаверсток цитируют Викторию Трейгер, генерального партнера и управляющего директора Felicis Ventures: «Принятие потребительских финансовых технологий уже было сильным перед пандемией, особенно в возрастной группе от 20 до 40 лет. Пандемия стала ракетой роста, способствующей быстрому ускорению усыновления во всех возрастных группах, включая 40–60-летних ».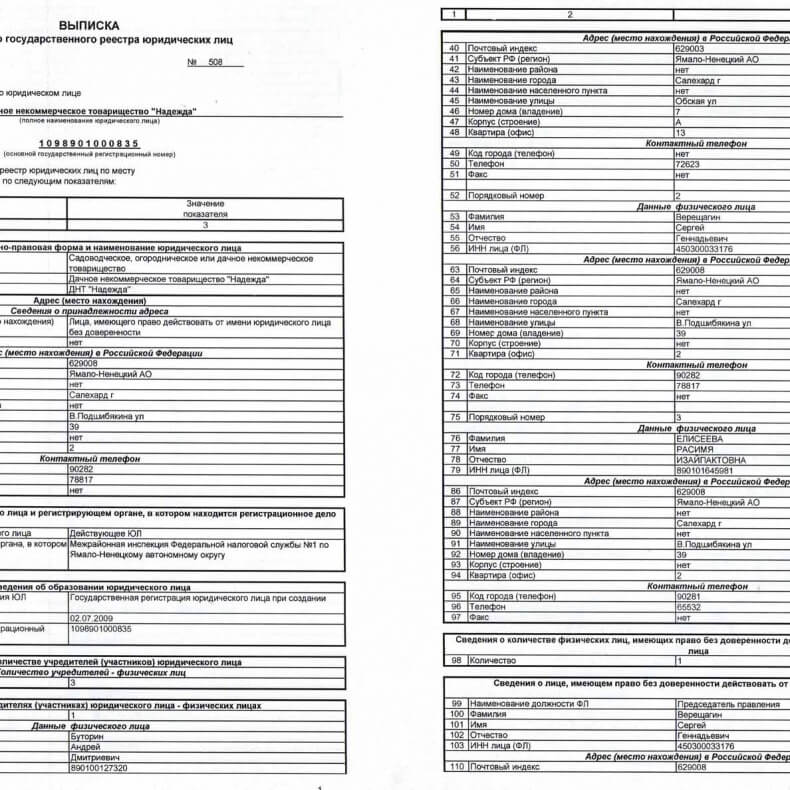
Среди «победителей» — Marqeta, обрабатывающая платежи для таких клиентов, как Instacart, DoorDash и Postmates, а также цифровые банки, такие как Chime, которые получили выгоду от «стимулирующих чеков, выходных для выплаты студенческих ссуд и (срок действия истек) в неделю. доплаты по безработице.«Цифровые банки также выигрывают, потому что они чаще всего ориентированы на платежи, и почти весь доход поступает от комиссионных сборов.
Еще одним бенефициаром экономики домоседов является Robinhood. Кауфлин и Хэверсток пишут:
«Скука застрять дома, резкие колебания фондового рынка и государственные проверки стимулов превратили некоторых миллениалов и представителей поколения Z в дневных трейдеров и игроков опционами».
По словам Кауфлина и Хаверстока: «Если есть один сегмент финансовых технологий, который безоговорочно победил в пандемии, то это… рассрочка платежа в пунктах продажи через Интернет.Он выигрывает как от перехода потребителей к покупкам через Интернет, так и от их нежелания в эти нестабильные экономические времена брать на себя новые долги по кредитной карте ». Они выделяют Afterpay, Affirm в Сан-Франциско и Klarna в Стокгольме.
Они выделяют Afterpay, Affirm в Сан-Франциско и Klarna в Стокгольме.
Текущая ситуация обязательно изменится, и соответственно изменятся условия, которые стимулировали рост этих финансовых технологий. Мы ожидаем, что экономическая ситуация по-прежнему будет давать долгосрочное финансирование в рассрочку POS.
Цифровые банки сосредоточены исключительно на обмене, так как выручка — это проблема, которую необходимо решить для этих организаций, чтобы они процветали в будущем.В частности, когда новые платежные системы, такие как RTP Клиринговой палаты и FedNow ФРС, закрепляются, что может повлиять на обмен. Дикая карта меняет покупательское поведение потребителей.
Финтех-партнерство: секрет обеспечения актуальности Будущее цифрового банкинга после пандемии стало предметом двух интервью, которые мы видели на этой неделе. ITP.net опубликовал интервью Сары Ризви с Виссамом Хури, главой международного бизнеса Finastra, посвященное партнерским отношениям между финтех-компаниями и банками. В свою очередь Гэри Дреник, основатель Prosper Business Development, взял интервью у технического директора Moxtra Стэнли Хуанга и CBO Лину Ияр для статьи в Forbes, в которой обсуждались недостатки существующих предложений цифрового банкинга.
В свою очередь Гэри Дреник, основатель Prosper Business Development, взял интервью у технического директора Moxtra Стэнли Хуанга и CBO Лину Ияр для статьи в Forbes, в которой обсуждались недостатки существующих предложений цифрового банкинга.
Хури отмечает, что:
«С начала пандемии COVID-19 мы стали свидетелями резкого роста внедрения цифровых банковских услуг … Ограничения, введенные в попытке замедлить продолжающийся кризис здравоохранения, такие как социальное дистанцирование, работа из дома, приносят финансовые технологии и другие цифровые технологии выходят на первый план, поскольку потребители меняют свое повседневное поведение, а предприятия меняют методы своей работы.”
Однако внедрение цифрового банкинга не является чем-то новым. Хури добавляет: «В конечном итоге цифровая трансформация финансовых услуг уже шла полным ходом, и COVID-19 открыл будущее, ускорив темпы трансформации».
Ияр соглашается:
«Переход на мобильный банкинг уже произошел, но после пандемии произошел серьезный сдвиг в сторону виртуального банкинга.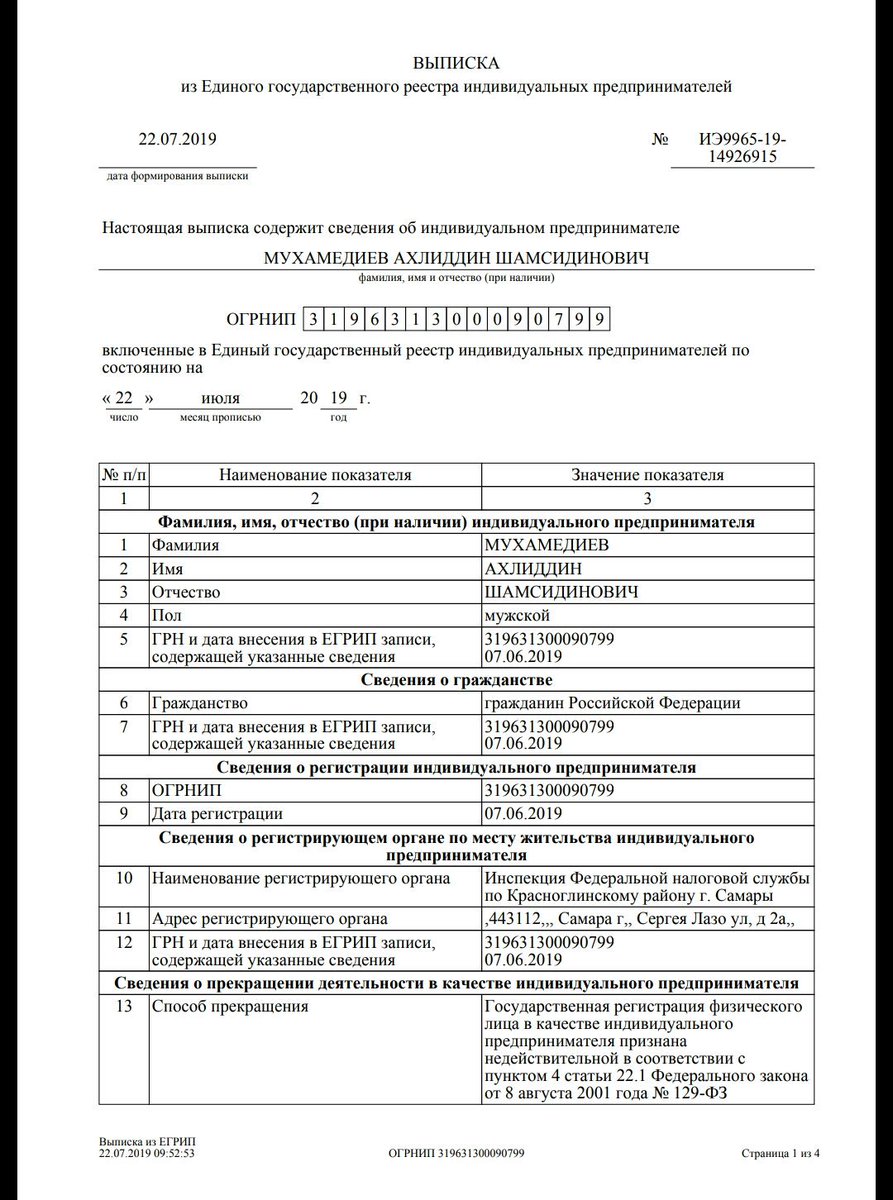 Сегодня все больше банков полагаются на финтех-платформы, чтобы предоставлять клиентам персонализированный опыт взаимодействия с клиентами наравне с их традиционными отделениями.”
Сегодня все больше банков полагаются на финтех-платформы, чтобы предоставлять клиентам персонализированный опыт взаимодействия с клиентами наравне с их традиционными отделениями.”
Важность налаживания партнерских отношений с финтех-компаниями как способа устранения пробелов в возможностях банков выходит на первый план в обоих обсуждениях.
Хури считает, что банки «должны смотреть на партнерство с финтех-компаниями, которые позволят банкам получить доступ к услугам, знаниям и опыту, необходимым для реализации их предложений. Эти партнерские отношения также помогут банкам преодолеть некоторые из внутренних барьеров, с которыми они сталкиваются внутри, такие как давление экономии средств или культура избегания риска.”
Изучая качество обслуживания клиентов, Хури предупреждает банки, что они «должны отказаться от устаревших систем и сделать это быстро». Ияр видит переход от рынка банковских клиентов к рынку банковских услуг ».
Текущая банковская модель допускает «разные уровни обслуживания на основе суждения банка. Благодаря цифровой платформе банки могут предоставлять свои услуги всем клиентам по требованию, и тогда клиент может воспользоваться этими услугами, если они соответствуют его индивидуальным потребностям.Это создает постоянные отношения между клиентом и банком, поскольку каждый профиль и история клиента остаются в рамках организации, обеспечивая непрерывные непрерывные отношения при любой передаче управления отношениями ».
Благодаря цифровой платформе банки могут предоставлять свои услуги всем клиентам по требованию, и тогда клиент может воспользоваться этими услугами, если они соответствуют его индивидуальным потребностям.Это создает постоянные отношения между клиентом и банком, поскольку каждый профиль и история клиента остаются в рамках организации, обеспечивая непрерывные непрерывные отношения при любой передаче управления отношениями ».
Хуан добавляет:
«Ключевым моментом для банков является интеграция функций, ориентированных на удобство и доступность, таких как обмен сообщениями, видеочат, совместная работа с документами и многое другое, чтобы создать привлекательное решение для клиентов, которым можно будет пользоваться из любого места и в любое время».
Хури считает, что сотрудничество с финтех-фирмами имеет решающее значение для всех банков: «больше нецелесообразно стремиться к успеху в одиночку.Инновации редко приходят исключительно изнутри, и чем раньше банки осознают внутреннюю ценность новой открытой экосистемы, тем лучше они смогут обеспечить свою актуальность ».
Мы согласны с важностью взаимоотношений и реального партнерства между финтех-компаниями и финансовыми учреждениями. Финансовые организации и финтех-компании должны изменить свое мышление при налаживании таких партнерских отношений. Еще в апреле мы внесли предложения, чтобы помочь обеим сторонам понять друг друга и наладить их отношения.
Сообщите нам, что вы думаете о Weekly Extract. Оставайся в безопасности. И не забудьте подписаться на нас в LinkedIn и Twitter.
Еженедельная выдержка: 5 октября 2020 г.
Еженедельная выдержка из Extractable — это сжатый обзор новостей о цифровом опыте для финансовых организаций, а также наш опыт из Сан-Франциско.
На этой неделе мы обсуждаем последние действия регулирующих органов США в отношении инноваций и финансовых технологий. Мы резюмируем учебник RegTech, который, по нашему мнению, должен прочитать каждый, кто работает в сфере финансовых услуг, и, наконец, мы освещаем продолжающиеся дискуссии о цифровой трансформации в банковской сфере.
В прошлом наблюдатели в сфере финансовых услуг возлагали вину за медленные темпы инноваций на режим регулирования. Правила, как и eSig, не обновлялись десятилетиями; даже с появлением новых технологий. Новые области, такие как криптовалюта, не регулируются нормативными актами, что часто не позволяет традиционным финансовым организациям расширять финансовую деятельность. Между агентствами и местными экспертами существует противоречивое толкование правил.Регулирующие органы штата и федеральные органы часто расходятся во взглядах, что иногда приводит к судебным искам.
В последнее время регулирующие органы начали больше говорить об инновациях, финансовых технологиях и конкретных технологиях с некоторыми действиями. Пандемия COVID-19 и внезапная необходимость перехода к цифровым моделям вызвали у регулирующих органов чувство безотлагательности. На этой неделе во время конференции LendIt Fintech USA 2020 и.о. финансового контролера OCC, и председатель FDIC рассказали об инновациях. Елена МакВильямс, председатель FDIC, отметила, что FDIC предприняла шаги для развития партнерских отношений в сфере финансовых технологий в сфере финансовых услуг как внутри страны, так и между учреждениями, которые они регулируют.Маквильямс не привел никаких конкретных правил. Со своей стороны исполняющий обязанности финансового контролера Брайан Брукс подробно рассказал о продолжающемся стремлении OCC к финансовым технологиям и платежным банковским чартерам.
На этой неделе во время конференции LendIt Fintech USA 2020 и.о. финансового контролера OCC, и председатель FDIC рассказали об инновациях. Елена МакВильямс, председатель FDIC, отметила, что FDIC предприняла шаги для развития партнерских отношений в сфере финансовых технологий в сфере финансовых услуг как внутри страны, так и между учреждениями, которые они регулируют.Маквильямс не привел никаких конкретных правил. Со своей стороны исполняющий обязанности финансового контролера Брайан Брукс подробно рассказал о продолжающемся стремлении OCC к финансовым технологиям и платежным банковским чартерам.
В статье в BankingDive на этой неделе Анна Хрушка резюмирует комментарии Брукса и некоторые реакции банковского сектора. Хрушка пишет:
«Брукс сказал, что национальная хартия для финансовых компаний и платежных компаний является надлежащим ответом на продолжающееся разделение финансовых услуг.В качестве обоснования цитируется фраза Брукса: «Клиенты хотят того, чего хотят. Вопрос в том, достаточно ли гибка наша платформа для этого? И я думаю, что так и должно быть ».
Вопрос в том, достаточно ли гибка наша платформа для этого? И я думаю, что так и должно быть ».
Хрушка отмечает, что в тот же день «несколько торговых групп направили в Конгресс письмо, в котором выразили несогласие с планами OCC относительно платежной хартии». Она цитирует их заявление:
«Мы выступаем против усилий OCC по предоставлению коммерческим компаниям, таким как Amazon или Facebook, национальной платежной хартии для доступа к платежной системе Федеральной резервной системы и системе безопасности… без защиты финансовой системы и потребителей от сопутствующего увеличения системного риска.”
Brooks отклонил эти опасения и назвал их недоразумением: «некоторые из этих торговых групп действуют в рамках… (идеи), что каким-то образом это приведет к более легкому принятию решения с меньшим количеством обязательств, и это сделает игровое поле непригодным для использования. -уровень. Я думаю, все как раз наоборот ».
Брукс также обратился к продолжающемуся судебному разбирательству между OCC и штатами по поводу чартеров. «Мы собираемся выиграть эти дела», — цитирует Брукса. «OCC никогда не проигрывал дело о полномочиях банков в США.С. Верховный суд. И все же в каждом поколении каждое новое действие OCC для адаптации к рынкам всегда подвергалось сомнению. Так что нет ничего нового в том, что Нью-Йорк подает на нас в суд ».
«Мы собираемся выиграть эти дела», — цитирует Брукса. «OCC никогда не проигрывал дело о полномочиях банков в США.С. Верховный суд. И все же в каждом поколении каждое новое действие OCC для адаптации к рынкам всегда подвергалось сомнению. Так что нет ничего нового в том, что Нью-Йорк подает на нас в суд ».
Nikhilesh De рассматривает еще одну проблему регулирования в статье в Coindesk. De пишет:
«OCC и Комиссия по ценным бумагам и биржам (SEC) опубликовали руководство по стейблкоинам… о том, как криптовалюты, обеспеченные фиатными валютами, должны рассматриваться в соответствии с законом.Де продолжает: «OCC подробно описал, как банки должны обращаться с резервами стейблкоинов, в частности, имея в виду стейблкоины, обеспеченные такими валютами, как доллар».
С тех пор, как Брукс был назначен исполняющим обязанности контролера, «ОКК предпринял ряд шагов по интеграции криптопространства с существующей финансовой системой. В последние месяцы OCC сообщил банкам, что они могут предоставлять услуги криптостартапам », а также о чартерной деятельности, упомянутой ранее.
В последние месяцы OCC сообщил банкам, что они могут предоставлять услуги криптостартапам », а также о чартерной деятельности, упомянутой ранее.
В части ТРЦ Де пишет:
«Комиссия по ценным бумагам и биржам заявила, что некоторые стейблкоины могут не являться ценными бумагами в соответствии с федеральным законом, но посоветовала эмитентам сотрудничать с агентством и юрисконсультом, чтобы убедиться, что это так.Согласно заявлению, Комиссия по ценным бумагам и биржам готова опубликовать письмо о запрете действий, которое заверит получателя в том, что регулирующий орган не будет возбуждать принудительные меры против компании ».
Ноэль Ачесон, директор по исследованиям CoinDesk, в отдельной статье CoinDesk пишет, что спрос на стейблкоины значительно вырос, и необходимо срочно принять ответные меры регулирующих органов.
«Общая стоимость стейблкоинов в настоящее время превысила 18 миллиардов долларов по сравнению с 10 миллиардами долларов всего четыре месяца назад. Во многом этот рост был обусловлен международным спросом на доллары, а также все более сложными финансовыми инструментами, созданными на основе общедоступной технологии блокчейн. USDC , ведущий американский стейблкоин, в этом году продемонстрировал почти четырехкратное увеличение рыночной капитализации до более чем 2 миллиардов долларов »
Во многом этот рост был обусловлен международным спросом на доллары, а также все более сложными финансовыми инструментами, созданными на основе общедоступной технологии блокчейн. USDC , ведущий американский стейблкоин, в этом году продемонстрировал почти четырехкратное увеличение рыночной капитализации до более чем 2 миллиардов долларов »
Ачесон полагает, что эти нормативные положения «могут стимулировать банки к активному поиску стабильного бизнеса и тем самым расширить как их клиентскую базу, так и их долю на крипторынках.Она добавляет, что «в недавнем заявлении OCC говорится, что национальные банки США теперь могут хранить криптоактивы. Предположительно, это также относится к стейблкоинам. Таким образом, банк может привлекать не только эмитентов стейблкоинов, но и их клиентов. Тогда имело бы смысл облегчить переводы стейблкоинов между клиентами и (почему бы и нет) даже между банками. Могут появиться новые платежные сети, которые, в свою очередь, могут привести к появлению множества новых банковских услуг. Для отрасли, испытывающей давление из-за низких процентных ставок и надвигающихся дефолтов, этот потенциальный вектор роста в конечном итоге станет привлекательным.”
Для отрасли, испытывающей давление из-за низких процентных ставок и надвигающихся дефолтов, этот потенциальный вектор роста в конечном итоге станет привлекательным.”
Хотя многие из этих шагов действительно служат хорошим предзнаменованием для инноваций в финансовых услугах, тот факт, что регулирующие органы не работают согласованно в рамках нормативного режима США, оказывается постоянным препятствием.
Что необходимо знать каждому финансовому агенту о RegTechВ соответствии с тематикой регулирования, в ReadWrite мы наткнулись на отличный учебник по RegTech от Алекса Соколова. Соколов начинает с определения RegTech:
«RegTech подразумевает использование технологий для надзора, отчетности и обеспечения соблюдения требований в основном для финансовой отрасли (по сути, наиболее регулируемой), а также для удовлетворения потребностей фармацевтического и медицинского производства, нефтегазового сектора, транспорта и т. Д.”
Д.”
Он добавляет, что здесь также рассматривается применение технологий для управления рисками. Соколов кратко рассказывает о RegTech: «История RegTech восходит к финансовому кризису 2008 года, который привел к усилению правительственных постановлений. Кроме того, технологические достижения в финансовой сфере стимулировали появление множества финтех-решений, направленных на различное обслуживание клиентов ».
Соколов затем исследует текущую ситуацию и преимущества RegTech.«Тем не менее, многие финансовые организации воздерживаются от внедрения решений RegTech, несмотря на их растущую популярность и ощутимые выгоды». Соколов отлично справляется с задачей, кратко исследуя каждое из препятствий на пути внедрения RegTech.
Наконец, он проводит исследование «зрелых технологий, используемых в решениях RegTech», в том числе:
- Облачные вычисления для безопасности данных и экономической эффективности
- Обработка естественного языка (NLP) для контроля и управления изменениями нормативной базы
- Машинное обучение (ML) для улучшения мониторинга транзакций
- Роботизированная автоматизация процессов (RPA) для упрощения процессов KYC и AML
- Аналитика больших данных для улучшения принятия решений
- Блокчейн для большей прозрачности сделок
- Биометрия для лучшего управления идентификацией
Мы сталкиваемся с большой неразберихой в отношении применения технологий в области комплаенс и управления рисками в нашей работе с различными финансовыми учреждениями. Я призываю наших читателей прочитать этот краткий букварь.
Я призываю наших читателей прочитать этот краткий букварь.
Цифровая трансформация: дело не в технологиях
В статье в Forbes на этой неделе Дмитрий Долгоруков пишет, что:
«цифровую трансформацию не следует рассматривать как стратегию, основанную на технологиях. Другими словами, вы не переходите на цифровые технологии только потому, что можете. Вместо этого все сводится к созданию бизнес-стратегии, позволяющей финансовым учреждениям оперативно реагировать на потребности рынка.”
Далее он отмечает, что «ключевыми компонентами концепции цифрового банкинга являются клиентоориентированный подход, персонализация предложения и мобильность». Это концепции, которые близки нашему подходу к оказанию помощи нашим клиентам в определении их цифровой стратегии.
В то время как более мелкие финансовые организации считают, что они не могут внедрять инновации, Долгоруков отмечает, что «чем больше становятся банки, тем труднее им внедрять инновации». Способ ускорить цифровую трансформацию — это «стратегическое партнерство и альянсы с финтех-компаниями».Он добавляет: «В то время как банки имеют более глубокое понимание отрасли, финтех более опытны во внедрении технологий».
Способ ускорить цифровую трансформацию — это «стратегическое партнерство и альянсы с финтех-компаниями».Он добавляет: «В то время как банки имеют более глубокое понимание отрасли, финтех более опытны во внедрении технологий».
Однако, как отмечает Эдмунд Лоулер в статье в журнале BAI’s Banking Strategies, небольшим организациям не нужно полагаться только на партнерство. Лоулер приводит несколько примеров небольших финансовых организаций, которые смогли легко поворачиваться во время пандемии благодаря цифровым стратегиям, которые применялись ранее.
Лоулер пишет:
“ Vast Bank Цифровая трансформация шла полным ходом, когда разразилась пандемия.Семейный банк, расположенный в Талсе, штат Оклахома, имеет активы на 670 миллионов долларов и 11 филиалов. Президент и генеральный директор Брэд Скривнер говорит, что недавно установила новую банковскую платформу с открытым исходным кодом и предоставляет банковские услуги для финансовых технологий Meed Banking Club . Мобильное приложение Vast дает банку доступ к сети в 48 штатах ».
Мобильное приложение Vast дает банку доступ к сети в 48 штатах ».
Другой пример — NBT, общественный банк с активами в 10 миллиардов долларов, расположенный в Норвиче, Нью-Йорк. NBT «быстро и эффективно перешел на почти полностью цифровую деятельность, — говорит Джозеф Стальяно, исполнительный вице-президент и президент розничного банковского обслуживания.Лоулер цитирует Стаглиано:
«Семь или восемь лет назад мы разработали очень надежную технологическую дорожную карту с упором на качество обслуживания клиентов, опыт сотрудников и опыт работы в цифровых отраслях».
В другой статье Forbes Касия Боровска, управляющий директор Brainpool AI, пишет, что:
«Традиционным банкам потребуется либо сотрудничать с FinTech [sic], либо самим взять на себя процесс трансформации».
Она отмечает, что цифровые преобразования требуют «цифровых возможностей, а также фундаментального изменения мышления.”
Borowska правильно определяет изменение мышления с продуктов банка на потребности клиентов. В этом сдвиге технологии могут быть использованы для оказания помощи. Она отмечает: «Использование искусственного интеллекта и больших данных имеет решающее значение для масштабной персонализации… услуг (отвечающих потребностям клиентов)».
В этом сдвиге технологии могут быть использованы для оказания помощи. Она отмечает: «Использование искусственного интеллекта и больших данных имеет решающее значение для масштабной персонализации… услуг (отвечающих потребностям клиентов)».
Другая смена, которую она определяет, — это понимание:
«Важность как физических, так и цифровых точек соприкосновения. Цифровая трансформация не означает технологию, которая всегда заменяет человеческое прикосновение.Решение не двоичное. Физические точки соприкосновения можно и нужно улучшить, применяя цифровые технологии, такие как искусственный интеллект, для улучшения человека ».
Боровска добавляет: «Цифровое включение не должно приводить к исключению тех, кто больше всего нуждается в человеческом контакте». Наконец, Боровска предупреждает: «Банки, которые не осознают потенциал новых технологий сегодня, останутся позади и завтра потеряют клиентов».
Сообщите нам, что вы думаете о Weekly Extract.